A Single Goal is All You Need: Skills and Exploration Emerge from Contrastive RL without Rewards, Demonstrations, or Subgoals
作者: Grace Liu, Michael Tang, Benjamin Eysenbach
分类: cs.LG, cs.AI
发布日期: 2024-08-11
备注: Code and videos: https://graliuce.github.io/sgcrl/
💡 一句话要点
基于对比学习的无奖励强化学习,实现技能涌现与自主探索
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 强化学习 对比学习 无奖励学习 自主探索 技能涌现
📋 核心要点
- 传统强化学习依赖奖励函数引导探索,但设计奖励函数耗时且易引入偏差,限制了智能体的泛化能力。
- 该论文提出一种基于对比学习的无奖励强化学习方法,仅需目标状态的单次观察即可涌现技能和引导探索。
- 实验表明,该方法在操作任务中能自主学习移动、推动、拾取放置等技能,无需人工干预即可完成目标。
📝 摘要(中文)
本文提出了一种简单的强化学习算法,该算法能够在观察到任何成功试验之前,就涌现出技能和有方向的探索行为。例如,在操作任务中,智能体仅被给予目标状态的单个观察,就能学习技能,首先是移动其末端执行器,然后是推动块,最后是拾取和放置块。这些技能的涌现发生在智能体成功地将块放置在目标位置之前,并且不需要任何奖励函数、演示或手动指定的距离度量。一旦智能体学会可靠地达到目标状态,探索就会减少。该方法的实现是对先前工作的简单修改,不需要密度估计、集成或任何额外的超参数。直观地说,所提出的方法似乎不擅长探索,我们缺乏对其有效工作原理的清晰理论理解,尽管我们的实验提供了一些提示。
🔬 方法详解
问题定义:现有强化学习方法严重依赖于精心设计的奖励函数,这需要大量的人工工作,并且奖励函数的设计往往会引入偏差,导致智能体学习到次优策略。此外,奖励函数的设计也限制了智能体的泛化能力,难以适应新的环境和任务。因此,如何设计一种无需奖励函数的强化学习方法,实现自主探索和技能学习,是一个重要的研究问题。
核心思路:该论文的核心思路是利用对比学习,鼓励智能体学习区分不同的状态。具体来说,智能体被给予一个目标状态的观察,然后通过对比学习,学习如何达到这个目标状态。这种方法不需要任何奖励函数、演示或手动指定的距离度量,而是通过自我监督的方式,引导智能体进行探索和学习。
技术框架:该方法的技术框架主要包括以下几个步骤:1. 智能体与环境交互,收集经验数据。2. 从经验数据中采样正样本和负样本。正样本是指与目标状态相似的状态,负样本是指与目标状态不相似的状态。3. 使用对比损失函数,训练智能体学习区分正样本和负样本。4. 使用学习到的策略,与环境进行交互,并重复以上步骤。
关键创新:该论文最重要的技术创新点在于提出了一种基于对比学习的无奖励强化学习方法。与传统的强化学习方法相比,该方法不需要任何奖励函数、演示或手动指定的距离度量,而是通过自我监督的方式,引导智能体进行探索和学习。这种方法可以有效地解决奖励函数设计的问题,提高智能体的泛化能力。
关键设计:该方法使用了对比损失函数来训练智能体。对比损失函数的目标是使正样本之间的距离尽可能小,负样本之间的距离尽可能大。具体的损失函数形式未知,但其核心思想是鼓励智能体学习区分不同的状态。此外,该方法还使用了某种形式的策略梯度方法来更新智能体的策略,具体的策略梯度方法未知。
🖼️ 关键图片


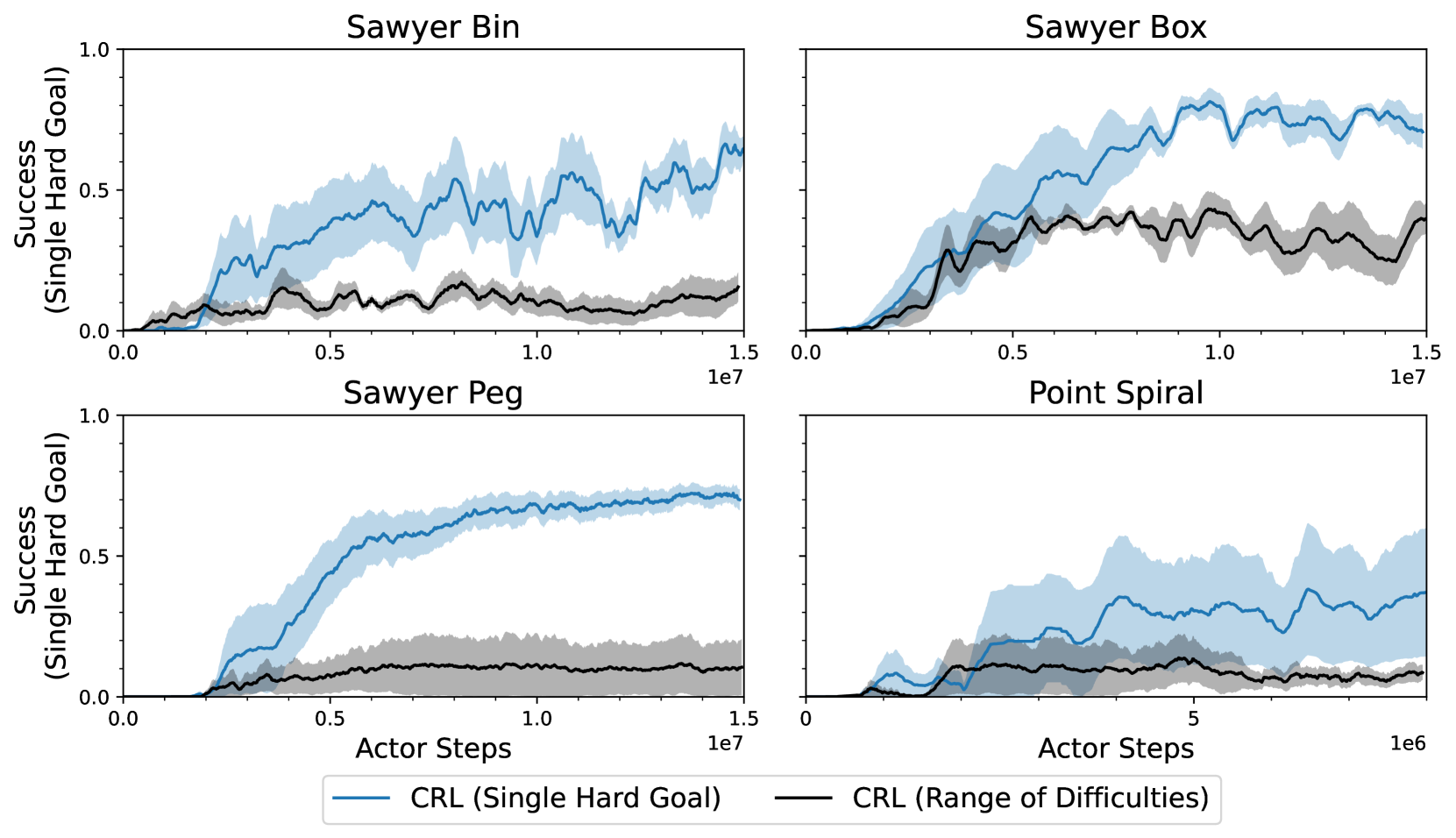
📊 实验亮点
该方法在操作任务中表现出色,智能体仅需目标状态的单次观察,就能自主学习移动、推动、拾取放置等技能,无需任何人工干预。实验结果表明,该方法能够有效地引导智能体进行探索和学习,并且能够学习到高质量的策略。具体的性能数据和对比基线未知。
🎯 应用场景
该研究成果可应用于机器人操作、自动驾驶、游戏AI等领域。通过无奖励的自主学习,机器人可以在复杂环境中学习完成各种任务,例如物体抓取、路径规划等。在自动驾驶领域,可以帮助车辆在没有明确奖励信号的情况下,学习安全驾驶策略。在游戏AI领域,可以使游戏角色更加智能,能够自主探索和学习游戏规则。
📄 摘要(原文)
In this paper, we present empirical evidence of skills and directed exploration emerging from a simple RL algorithm long before any successful trials are observed. For example, in a manipulation task, the agent is given a single observation of the goal state and learns skills, first for moving its end-effector, then for pushing the block, and finally for picking up and placing the block. These skills emerge before the agent has ever successfully placed the block at the goal location and without the aid of any reward functions, demonstrations, or manually-specified distance metrics. Once the agent has learned to reach the goal state reliably, exploration is reduced. Implementing our method involves a simple modification of prior work and does not require density estimates, ensembles, or any additional hyperparameters. Intuitively, the proposed method seems like it should be terrible at exploration, and we lack a clear theoretical understanding of why it works so effectively, though our experiments provide some hints.