Optimizing Portfolio with Two-Sided Transactions and Lending: A Reinforcement Learning Framework
作者: Ali Habibnia, Mahdi Soltanzadeh
分类: q-fin.PM, cs.LG
发布日期: 2024-08-09
💡 一句话要点
提出基于强化学习的双边交易与借贷投资组合优化框架,提升高风险环境下的收益。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 投资组合管理 加密货币交易 风险管理 双边交易 借贷 SAC算法 CNN-MHA
📋 核心要点
- 传统强化学习模型在处理高风险投资组合时存在局限性,难以有效管理下行风险和优化资本。
- 论文提出一种新的环境公式和基于损益的奖励函数,结合双边交易和借贷机制,优化投资组合管理。
- 实验结果表明,该模型在高波动性市场中显著优于基准,实现了更高的风险回报率和盈利能力。
📝 摘要(中文)
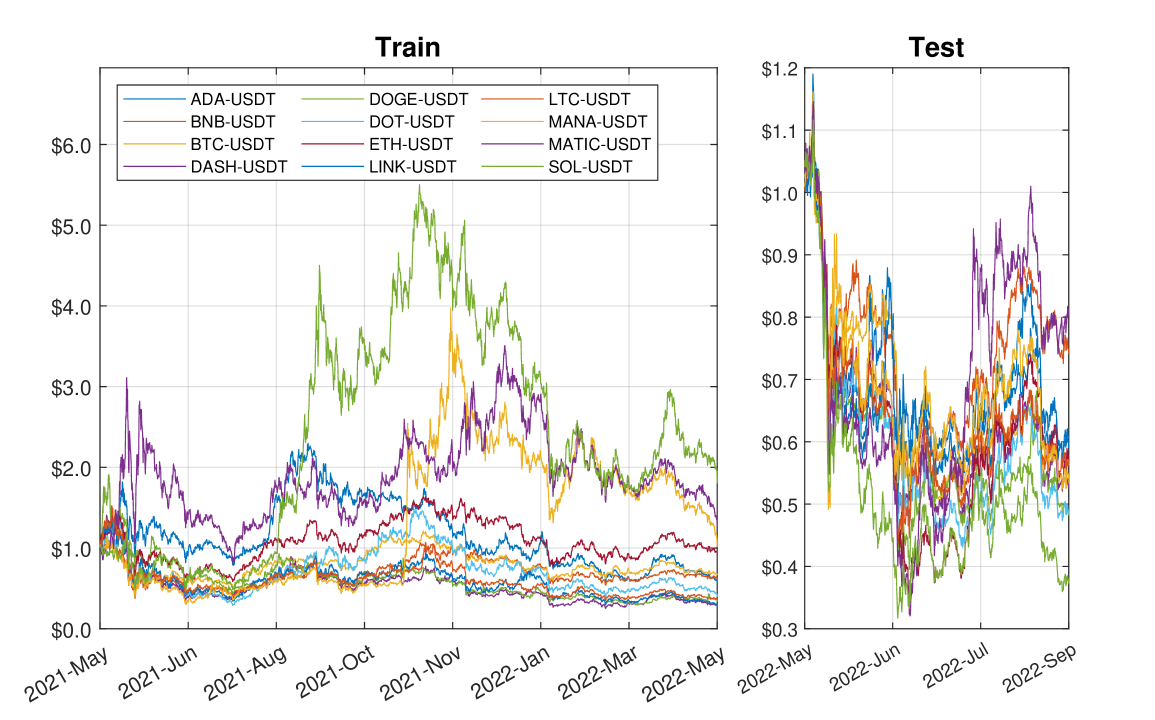
本研究提出了一种基于强化学习(RL)的投资组合管理模型,专为高风险环境设计,旨在解决传统RL模型的局限性,并通过双边交易和借贷来挖掘市场机会。该方法集成了一种新的环境公式和基于损益(PnL)的奖励函数,增强了RL智能体在下行风险管理和资本优化方面的能力。我们使用带有卷积神经网络与多头注意力机制(CNN-MHA)的软演员-评论家(SAC)智能体实现了该模型。该设置有效地管理了币安永续期货市场中一个多元化的12种加密资产投资组合,利用USDT进行贷款的发放和接收,并每4小时进行一次再平衡,利用前48小时的市场数据。在两个16个月的不同市场波动时期进行的测试表明,该模型显著优于基准,尤其是在高波动性情景中,实现了更高的风险回报率,并展示了强大的盈利能力。这些结果证实了该模型在利用市场动态和管理加密货币等波动环境中的风险方面的有效性。
🔬 方法详解
问题定义:论文旨在解决高风险环境下,传统强化学习在投资组合管理中的不足,尤其是在下行风险管理和资本优化方面。现有方法难以有效利用市场中的双边交易和借贷机会,导致收益受限。
核心思路:论文的核心在于构建一个能够有效利用双边交易(买入和卖空)和借贷机制的强化学习模型。通过优化环境设置和奖励函数,鼓励智能体在控制风险的同时最大化收益,从而在高波动市场中获得更好的表现。
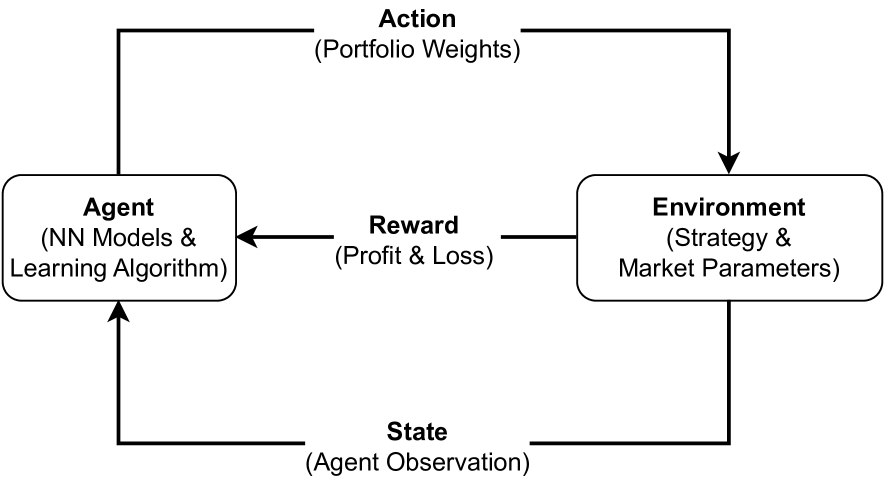
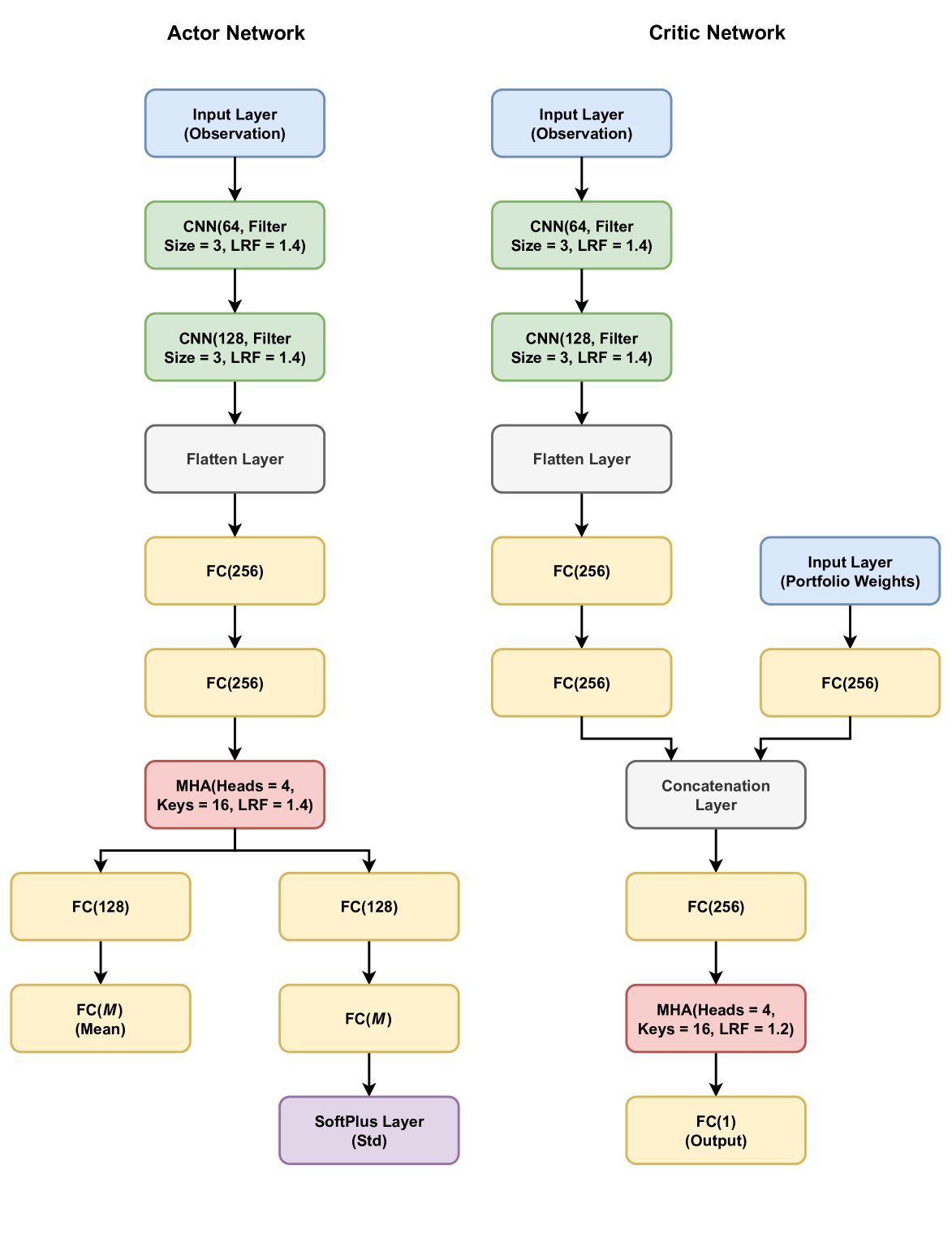
技术框架:整体框架包括以下几个主要模块:1) 环境模拟器:模拟加密货币市场,包括价格变动、交易费用、借贷利率等。2) 强化学习智能体:采用SAC算法,负责根据市场状态选择交易和借贷策略。3) 奖励函数:基于损益(PnL)设计,鼓励智能体实现盈利并控制风险。4) 网络结构:使用CNN-MHA提取市场数据中的特征,为智能体提供决策依据。
关键创新:论文的关键创新在于将双边交易和借贷机制融入强化学习框架,并设计了相应的环境和奖励函数。这使得智能体能够更灵活地利用市场机会,并在高风险环境中实现更好的风险管理和收益优化。此外,CNN-MHA的使用提升了智能体对市场信息的理解能力。
关键设计:模型使用Soft Actor-Critic (SAC) 作为强化学习算法,这是一个off-policy的算法,可以平衡探索和利用。CNN-MHA网络用于提取过去48小时的市场数据特征,输入到SAC智能体中。奖励函数基于PnL设计,鼓励盈利和风险控制。投资组合每4小时再平衡一次,允许借入和借出USDT。
🖼️ 关键图片
📊 实验亮点
该模型在两个16个月的不同市场波动时期进行了测试,结果表明,该模型显著优于基准,尤其是在高波动性情景中,实现了更高的风险回报率。具体而言,该模型在收益率和夏普比率等指标上均优于传统投资策略,证明了其在高风险环境下的有效性。
🎯 应用场景
该研究成果可应用于高波动性金融市场,如加密货币交易、外汇交易等。该模型能够帮助投资者在复杂市场环境中进行风险管理和资产配置,提高投资回报率。未来可扩展到其他金融产品和市场,并结合更多市场信息,进一步提升模型的性能。
📄 摘要(原文)
This study presents a Reinforcement Learning (RL)-based portfolio management model tailored for high-risk environments, addressing the limitations of traditional RL models and exploiting market opportunities through two-sided transactions and lending. Our approach integrates a new environmental formulation with a Profit and Loss (PnL)-based reward function, enhancing the RL agent's ability in downside risk management and capital optimization. We implemented the model using the Soft Actor-Critic (SAC) agent with a Convolutional Neural Network with Multi-Head Attention (CNN-MHA). This setup effectively manages a diversified 12-crypto asset portfolio in the Binance perpetual futures market, leveraging USDT for both granting and receiving loans and rebalancing every 4 hours, utilizing market data from the preceding 48 hours. Tested over two 16-month periods of varying market volatility, the model significantly outperformed benchmarks, particularly in high-volatility scenarios, achieving higher return-to-risk ratios and demonstrating robust profitability. These results confirm the model's effectiveness in leveraging market dynamics and managing risks in volatile environments like the cryptocurrency market.