VulScribeR: Exploring RAG-based Vulnerability Augmentation with LLMs
作者: Seyed Shayan Daneshvar, Yu Nong, Xu Yang, Shaowei Wang, Haipeng Cai
分类: cs.SE, cs.CR, cs.LG
发布日期: 2024-08-07 (更新: 2025-08-12)
备注: Accepted by TOSEM; 26 pages, 6 figures, 8 tables, 3 prompt templates, 1 algorithm
DOI: 10.1145/3760775
💡 一句话要点
VulScribeR:探索基于RAG的LLM漏洞增强方法,提升漏洞检测器性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 漏洞检测 数据增强 大型语言模型 检索增强生成 软件安全
📋 核心要点
- 深度学习漏洞检测器受限于脆弱代码数据不足,阻碍了其检测性能。
- VulScribeR利用RAG和LLM,通过变异、注入和扩展三种策略增强脆弱数据集。
- 实验表明,VulScribeR显著优于现有数据增强方法,并能以较低成本生成大量样本。
📝 摘要(中文)
漏洞检测对于软件安全至关重要,但基于深度学习的漏洞检测器(DLVD)面临数据匮乏的问题,限制了其有效性。数据增强可以缓解这一问题,但增强脆弱代码具有挑战性,需要一种能够保持漏洞的生成解决方案。以往的工作只关注于生成包含单个语句或特定类型漏洞的样本。最近,大型语言模型(LLM)已被用于解决各种代码生成和理解任务,并取得了令人鼓舞的结果,特别是与检索增强生成(RAG)融合时。因此,我们提出了VulScribeR,一种新颖的基于LLM的解决方案,它利用精心设计的提示模板来增强脆弱数据集。更具体地说,我们探索了三种策略来增强单语句和多语句漏洞,即Mutation、Injection和Extension。我们对四个漏洞数据集和DLVD模型进行了广泛的评估,使用三个LLM表明,我们的方法在f1-score上优于两种SOTA方法Vulgen和VGX,以及随机过采样(ROS),平均生成5K个脆弱样本时分别提高了27.48%、27.93%和15.41%,生成15K个脆弱样本时分别提高了53.84%、54.10%、69.90%和40.93%。我们的方法证明了其大规模数据增强的可行性,以低至1.88美元的价格生成1K个样本。
🔬 方法详解
问题定义:现有基于深度学习的漏洞检测器(DLVD)的性能受到训练数据不足的限制。虽然数据增强是一种潜在的解决方案,但生成既包含漏洞又具有真实性的代码样本非常困难。以往的方法通常只能生成包含单个语句或特定类型漏洞的简单样本,无法有效提升DLVD的性能。
核心思路:VulScribeR的核心思路是利用大型语言模型(LLM)强大的代码生成能力,结合检索增强生成(RAG)技术,生成更真实、更复杂的脆弱代码样本。通过精心设计的提示模板,引导LLM在生成过程中保持并增强漏洞的特征。
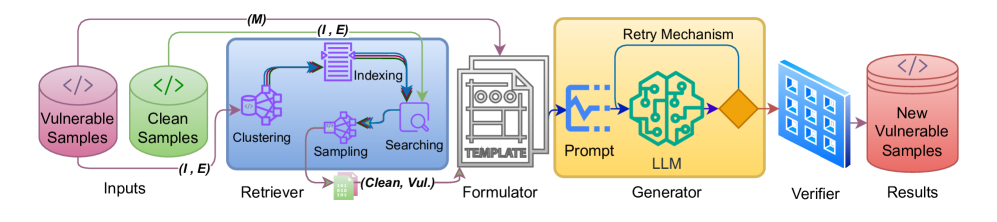
技术框架:VulScribeR的整体框架包含以下几个主要阶段:1) 漏洞检索:从现有漏洞数据集中检索与目标漏洞类型相似的样本。2) 提示生成:根据检索到的样本和预定义的提示模板,生成包含漏洞信息的提示。3) 代码生成:使用LLM根据生成的提示生成新的脆弱代码样本。4) 验证与过滤:对生成的代码样本进行验证,确保其包含目标漏洞,并过滤掉不符合要求的样本。
关键创新:VulScribeR的关键创新在于其基于RAG的漏洞增强方法,以及三种具体的增强策略:Mutation(变异现有漏洞代码)、Injection(向现有代码注入漏洞)和Extension(扩展现有漏洞代码)。与现有方法相比,VulScribeR能够生成更复杂、更真实的脆弱代码样本,从而更有效地提升DLVD的性能。
关键设计:VulScribeR的关键设计包括:1) 精心设计的提示模板,用于引导LLM生成包含漏洞的代码。2) 三种不同的增强策略,以适应不同类型的漏洞和代码结构。3) 使用多个LLM进行实验,以评估方法的泛化能力。4) 详细的实验评估,包括与现有数据增强方法的比较,以及对不同DLVD模型的影响。
🖼️ 关键图片
📊 实验亮点
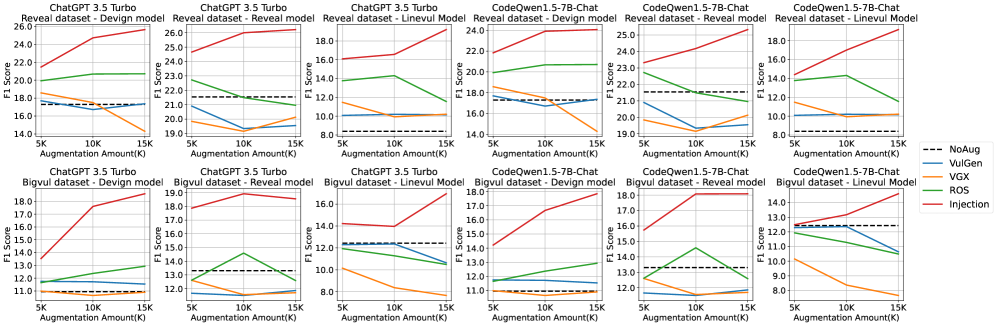
实验结果表明,VulScribeR在四个漏洞数据集上显著优于两种SOTA方法Vulgen和VGX,以及随机过采样(ROS)。使用5K生成样本时,f1-score平均提升27.48%、27.93%和15.41%;使用15K生成样本时,f1-score平均提升53.84%、54.10%、69.90%和40.93%。此外,该方法还具有较低的生成成本,生成1K个样本仅需1.88美元。
🎯 应用场景
VulScribeR可应用于软件安全测试、漏洞挖掘和安全代码生成等领域。通过自动生成大量高质量的脆弱代码样本,可以有效提升漏洞检测器的性能,降低软件安全风险。该研究成果有助于构建更安全可靠的软件系统,并为未来的漏洞研究提供新的思路。
📄 摘要(原文)
Detecting vulnerabilities is vital for software security, yet deep learning-based vulnerability detectors (DLVD) face a data shortage, which limits their effectiveness. Data augmentation can potentially alleviate the data shortage, but augmenting vulnerable code is challenging and requires a generative solution that maintains vulnerability. Previous works have only focused on generating samples that contain single statements or specific types of vulnerabilities. Recently, large language models (LLMs) have been used to solve various code generation and comprehension tasks with inspiring results, especially when fused with retrieval augmented generation (RAG). Therefore, we propose VulScribeR, a novel LLM-based solution that leverages carefully curated prompt templates to augment vulnerable datasets. More specifically, we explore three strategies to augment both single and multi-statement vulnerabilities, with LLMs, namely Mutation, Injection, and Extension. Our extensive evaluation across four vulnerability datasets and DLVD models, using three LLMs, show that our approach beats two SOTA methods Vulgen and VGX, and Random Oversampling (ROS) by 27.48%, 27.93%, and 15.41% in f1-score with 5K generated vulnerable samples on average, and 53.84%, 54.10%, 69.90%, and 40.93% with 15K generated vulnerable samples. Our approach demonstrates its feasibility for large-scale data augmentation by generating 1K samples at as cheap as US$ 1.88.