Can DPO Learn Diverse Human Values? A Theoretical Scaling Law
作者: Shawn Im, Sharon Li
分类: cs.LG
发布日期: 2024-08-06 (更新: 2025-10-14)
备注: NeurIPS 2025
💡 一句话要点
提出DPO泛化理论框架,分析LLM学习多样化人类价值观的尺度规律
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 直接偏好优化 价值观对齐 泛化误差 奖励模型 理论分析
📋 核心要点
- 现有大型语言模型难以与人类偏好对齐,产生不良输出,需要偏好学习进行对齐。
- 论文提出理论框架,分析直接偏好优化(DPO)训练中,泛化能力如何随价值观多样性和样本数量变化。
- 通过分析奖励边际和训练轨迹,论文提供了泛化误差的界限,并在LLM上验证了理论的实际意义。
📝 摘要(中文)
大型语言模型(LLMs)展现了卓越的能力,但常常难以与人类偏好对齐,导致有害或不良输出。偏好学习,即训练模型基于人类反馈区分偏好和非偏好响应,已成为确保LLMs与人类价值观对齐的关键组成部分。确保LLMs为所有人对齐的一个重要部分是考虑多样化的价值观。本文提出了一个新的理论框架,用于分析在使用直接偏好优化训练的模型中,泛化如何随价值多样性和样本数量而变化。我们的框架严格评估了模型在有限数量的梯度步骤后泛化的程度,反映了真实世界的LLM训练实践。通过分析与每个样本相关的奖励边际及其在整个训练过程中的轨迹,我们提供了泛化误差的界限,证明了有效学习广泛的概念或价值观的挑战。这些见解在当代LLMs上得到了经验验证,突显了我们理论的实际相关性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在学习多样化人类价值观时泛化能力不足的问题。现有方法在处理价值观多样性时,难以保证模型在有限的训练步骤后仍能有效泛化,导致模型可能无法准确捕捉不同人群的偏好。
核心思路:论文的核心思路是通过建立一个理论框架,分析模型在DPO训练过程中,泛化误差与价值观多样性和样本数量之间的关系。该框架关注奖励边际,即模型对偏好样本和非偏好样本的区分程度,并以此来衡量模型的泛化能力。通过分析奖励边际在训练过程中的变化,可以推导出泛化误差的界限。
技术框架:论文构建的理论框架主要包含以下几个阶段:1) 定义奖励模型和偏好数据;2) 分析DPO训练过程中的梯度更新;3) 推导奖励边际的动态变化;4) 建立泛化误差与奖励边际、价值观多样性和样本数量之间的关系。该框架的核心在于通过奖励边际来量化模型的学习效果,并以此为基础分析泛化能力。
关键创新:论文最重要的技术创新点在于提出了一个针对DPO训练的泛化误差界限,该界限明确地将泛化误差与价值观多样性和样本数量联系起来。与现有方法相比,该理论框架能够更精确地分析模型在学习多样化价值观时的泛化性能,并为实际训练提供指导。
关键设计:论文的关键设计包括:1) 使用奖励边际作为衡量模型学习效果的关键指标;2) 采用有限梯度步骤的分析方法,更贴近实际LLM训练场景;3) 建立泛化误差与价值观多样性和样本数量之间的显式关系,为模型训练提供理论指导。
🖼️ 关键图片
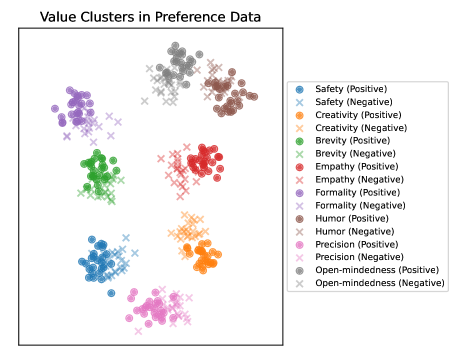
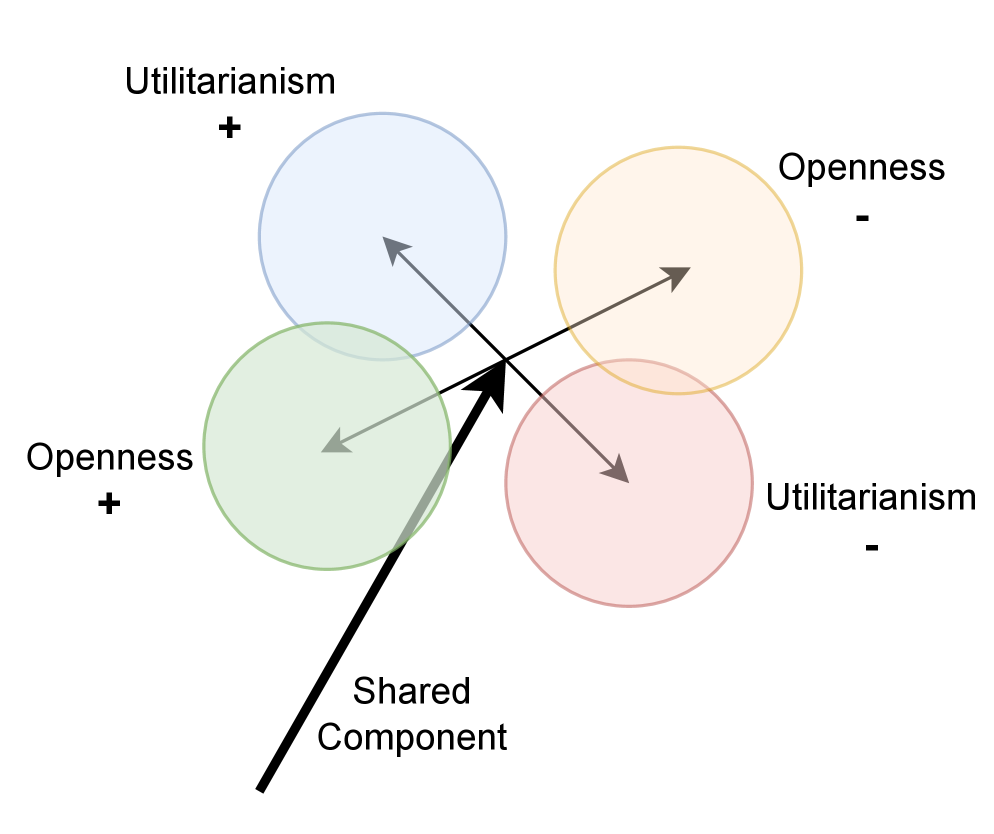
📊 实验亮点
论文通过实验验证了理论框架的有效性,在当代LLM上进行了实证分析,表明理论预测与实际结果相符。实验结果表明,价值观多样性越高,模型泛化所需的样本数量也越多。此外,实验还验证了奖励边际与泛化误差之间的关系,进一步证实了理论框架的准确性。
🎯 应用场景
该研究成果可应用于提升大型语言模型在各种场景下的对齐效果,例如:个性化推荐系统、公平性评估、以及涉及伦理道德判断的AI应用。通过理解价值观多样性对模型泛化的影响,可以更好地设计训练数据和优化算法,从而构建更安全、可靠和符合人类价值观的AI系统。该研究还有助于推动AI伦理和公平性领域的发展。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable capabilities but often struggle to align with human preferences, leading to harmful or undesirable outputs. Preference learning, which trains models to distinguish between preferred and non-preferred responses based on human feedback, has become a crucial component for ensuring that LLMs align with human values. An essential part of ensuring that LLMs are aligned for all people is accounting for a diverse set of values. This paper introduces a new theoretical framework to analyze how generalization scales with value diversity and sample quantity in models trained with direct preference optimization. Our framework rigorously assesses how well models generalize after a finite number of gradient steps, reflecting real-world LLM training practices. By analyzing the reward margin associated with each sample and its trajectory throughout training, we provide a bound on the generalization error that demonstrates the challenges of effectively learning a wide set of concepts or values. These insights are empirically validated on contemporary LLMs, underscoring the practical relevance of our theory.