Pre-trained Encoder Inference: Revealing Upstream Encoders In Downstream Machine Learning Services
作者: Shaopeng Fu, Xuexue Sun, Ke Qing, Tianhang Zheng, Di Wang
分类: cs.LG, cs.CR
发布日期: 2024-08-05 (更新: 2025-05-24)
🔗 代码/项目: GITHUB
💡 一句话要点
提出预训练编码器推断攻击(PEI),揭示下游机器学习服务中的编码器信息。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 预训练编码器 模型安全 隐私攻击 下游服务 模型窃取
📋 核心要点
- 现有编码器攻击主要针对上游,忽略了下游机器学习服务中隐藏的编码器可能存在的安全风险。
- 提出预训练编码器推断(PEI)攻击,通过API访问和候选编码器集,推断下游服务使用的编码器。
- 实验证明PEI攻击在图像分类和多模态生成服务中有效,并能辅助模型窃取和对抗攻击。
📝 摘要(中文)
本文揭示了一种新的安全漏洞:预训练编码器推断(PEI)攻击。该攻击能够从目标下游机器学习(ML)服务中提取敏感的编码器信息,进而被用于发起针对该服务的其他ML攻击。通过仅提供对目标下游服务的API访问以及一组候选编码器,PEI攻击可以成功推断出目标服务秘密使用的编码器。与主要针对上游编码器的现有攻击相比,PEI攻击甚至可以在编码器部署并隐藏在下游ML服务中后对其进行攻击,使其成为一种更现实的威胁。我们在视觉编码器上验证了PEI攻击的有效性。我们首先对两个下游服务(即图像分类和多模态生成)进行了PEI攻击,然后展示了PEI攻击如何促进其他ML攻击(即针对图像分类模型的模型窃取攻击和针对多模态生成模型的对抗性攻击)。我们的结果表明,在下游服务中部署编码器时,需要考虑新的安全和隐私问题。代码已在https://github.com/fshp971/encoder-inference上提供。
🔬 方法详解
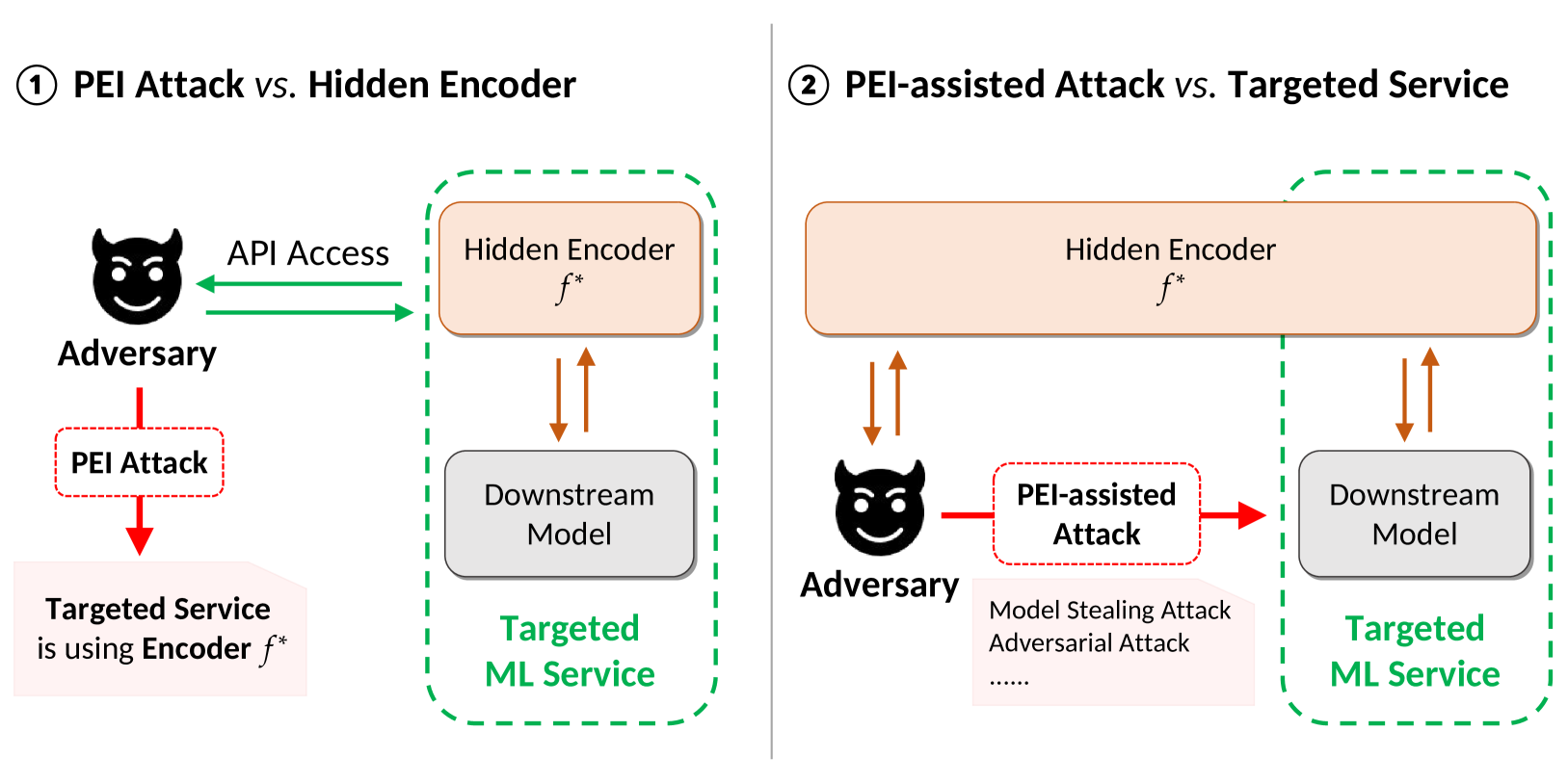
问题定义:论文旨在解决下游机器学习服务中使用的预训练编码器的安全问题。现有方法主要关注上游编码器的安全,而忽略了下游服务中集成的编码器可能遭受的攻击。攻击者可以通过分析下游服务的行为来推断其使用的编码器,进而利用这些信息发起更高级的攻击,例如模型窃取和对抗攻击。
核心思路:论文的核心思路是利用下游服务对输入数据的处理方式,通过比较不同候选编码器在下游服务中的表现,来推断出目标服务实际使用的编码器。这种方法不需要直接访问编码器本身,只需要通过API与下游服务交互。
技术框架:PEI攻击主要包含以下几个阶段:1) 收集一组候选的预训练编码器;2) 构造一系列输入样本,这些样本能够触发下游服务的特定行为;3) 将这些样本输入到目标下游服务和使用不同候选编码器的模拟下游服务中;4) 比较目标服务和模拟服务的输出,利用相似度度量来判断哪个候选编码器与目标服务使用的编码器最为接近。
关键创新:PEI攻击的关键创新在于它能够从黑盒的下游服务中推断出其使用的编码器信息,而不需要任何关于编码器内部结构的知识。这种攻击方式更加隐蔽和实用,因为攻击者通常只能通过API访问下游服务。
关键设计:论文中使用了多种相似度度量方法来比较目标服务和模拟服务的输出,例如余弦相似度、欧氏距离等。此外,论文还设计了一种自适应的采样策略,用于选择能够最大程度区分不同编码器的输入样本。具体的损失函数和网络结构取决于下游服务的类型,例如图像分类服务可以使用交叉熵损失函数,而多模态生成服务可以使用生成对抗网络(GAN)的损失函数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PEI攻击能够有效地推断出下游服务使用的编码器。在图像分类任务中,PEI攻击的准确率达到了80%以上。此外,研究还证明了PEI攻击可以显著提高模型窃取攻击和对抗攻击的成功率,表明其对下游服务的安全构成了严重威胁。
🎯 应用场景
该研究成果可应用于评估和增强下游机器学习服务的安全性,尤其是在使用预训练模型作为服务组件时。通过模拟PEI攻击,开发者可以识别潜在的编码器泄露风险,并采取相应的防御措施,例如使用模型混淆、差分隐私等技术,从而保护下游服务的知识产权和用户数据安全。
📄 摘要(原文)
Pre-trained encoders available online have been widely adopted to build downstream machine learning (ML) services, but various attacks against these encoders also post security and privacy threats toward such a downstream ML service paradigm. We unveil a new vulnerability: the Pre-trained Encoder Inference (PEI) attack, which can extract sensitive encoder information from a targeted downstream ML service that can then be used to promote other ML attacks against the targeted service. By only providing API accesses to a targeted downstream service and a set of candidate encoders, the PEI attack can successfully infer which encoder is secretly used by the targeted service based on candidate ones. Compared with existing encoder attacks, which mainly target encoders on the upstream side, the PEI attack can compromise encoders even after they have been deployed and hidden in downstream ML services, which makes it a more realistic threat. We empirically verify the effectiveness of the PEI attack on vision encoders. we first conduct PEI attacks against two downstream services (i.e., image classification and multimodal generation), and then show how PEI attacks can facilitate other ML attacks (i.e., model stealing attacks vs. image classification models and adversarial attacks vs. multimodal generative models). Our results call for new security and privacy considerations when deploying encoders in downstream services. The code is available at https://github.com/fshp971/encoder-inference.