CoMMIT: Coordinated Multimodal Instruction Tuning
作者: Xintong Li, Junda Wu, Tong Yu, Yu Wang, Xiang Chen, Jiuxiang Gu, Lina Yao, Julian McAuley, Jingbo Shang
分类: cs.LG, cs.CL
发布日期: 2024-07-29 (更新: 2025-09-08)
备注: 9 pages
💡 一句话要点
CoMMIT:通过协同多模态指令调优提升MLLM性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 指令调优 大型语言模型 协同学习 平衡学习
📋 核心要点
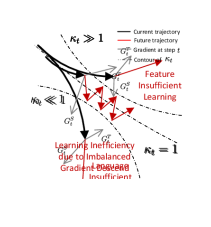
- 现有MLLM指令调优中,LLM和特征编码器学习不平衡,导致振荡和有偏学习,影响模型收敛。
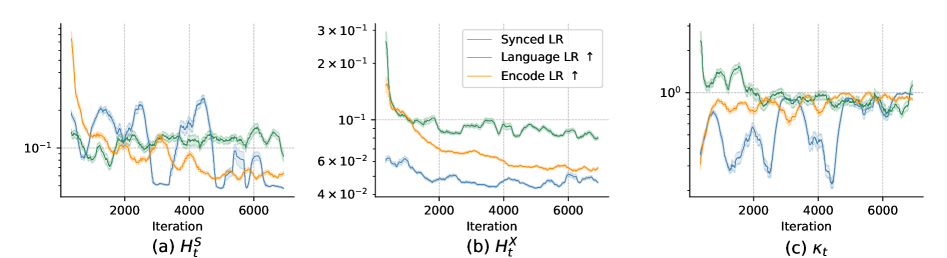
- 提出CoMMIT,通过多模态平衡系数定量衡量学习平衡,并设计动态学习调度器协调LLM和特征编码器。
- 引入梯度正则化,使用更大步长更新,更准确估计平衡系数,提升训练充分性,实验证明CoMMIT优于基线。
📝 摘要(中文)
多模态大型语言模型(MLLM)中的指令调优通常涉及骨干LLM与非文本输入模态的特征编码器之间的协同学习。主要的挑战在于如何有效地找到这两个模块之间的协同作用,以便LLM能够将其推理能力适应于下游任务,同时特征编码器可以调整以提供关于其模态的更具任务特定性的信息。本文从理论和实证角度分析了MLLM指令调优,发现特征编码器和LLM之间不平衡的学习会导致振荡和有偏学习的问题,从而导致次优收敛。受此启发,我们提出了一个多模态平衡系数,可以对学习的平衡进行定量测量。在此基础上,我们进一步设计了一个动态学习调度器,更好地协调LLM和特征编码器之间的学习,缓解振荡和有偏学习的问题。此外,我们引入了梯度上的辅助正则化,以促进使用更大的步长进行更新,这可能允许更准确地估计所提出的多模态平衡系数,并进一步提高训练的充分性。我们提出的方法与LLM和特征编码器的架构无关,因此可以通用地与各种MLLM集成。我们在具有各种MLLM的多个下游任务上进行了实验,证明了所提出的方法比MLLM指令调优中的基线更有效。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)指令调优过程中,LLM和特征编码器之间学习不平衡的问题。现有方法通常独立优化两个模块,忽略了它们之间的相互依赖关系,导致训练过程中的振荡和有偏学习,最终影响模型在下游任务上的性能。
核心思路:论文的核心思路是通过协调LLM和特征编码器之间的学习,实现更有效的指令调优。具体而言,论文提出了一个多模态平衡系数,用于定量衡量LLM和特征编码器学习的平衡程度。基于此,设计了一个动态学习调度器,根据平衡系数调整LLM和特征编码器的学习率,从而缓解振荡和有偏学习的问题。
技术框架:CoMMIT方法可以集成到各种MLLM架构中。其主要流程包括:1) 计算多模态平衡系数,衡量LLM和特征编码器学习的平衡程度;2) 使用动态学习调度器,根据平衡系数调整LLM和特征编码器的学习率;3) 引入梯度正则化,促进使用更大的步长进行更新。
关键创新:论文的关键创新在于提出了多模态平衡系数和动态学习调度器。多模态平衡系数能够定量衡量LLM和特征编码器学习的平衡程度,为动态调整学习率提供了依据。动态学习调度器能够根据平衡系数自适应地调整LLM和特征编码器的学习率,从而实现更有效的协同学习。与现有方法相比,CoMMIT方法能够更好地协调LLM和特征编码器之间的学习,从而提高模型在下游任务上的性能。
关键设计:多模态平衡系数的具体计算方式未知,但其核心思想是衡量LLM和特征编码器在训练过程中梯度变化的相对大小。动态学习调度器根据平衡系数调整LLM和特征编码器的学习率,具体调整策略未知,但目标是使LLM和特征编码器能够以更协调的方式进行学习。梯度正则化的具体形式未知,但其目标是促进使用更大的步长进行更新,从而提高训练的效率和稳定性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CoMMIT方法在多个下游任务上优于基线方法。具体性能提升数据未知,但论文强调CoMMIT能够有效缓解振荡和有偏学习的问题,从而提高模型的收敛速度和最终性能。CoMMIT的有效性验证了协同学习在MLLM指令调优中的重要性。
🎯 应用场景
CoMMIT方法可广泛应用于各种多模态任务,例如图像描述、视觉问答、多模态对话等。通过协调LLM和特征编码器之间的学习,CoMMIT能够提升MLLM在这些任务上的性能,从而实现更智能、更高效的多模态应用。未来,CoMMIT有望推动多模态人工智能的发展,为人类提供更便捷、更智能的服务。
📄 摘要(原文)
Instruction tuning in multimodal large language models (MLLMs) generally involves cooperative learning between a backbone LLM and a feature encoder of non-text input modalities. The major challenge is how to efficiently find the synergy between the two modules so that LLMs can adapt their reasoning abilities to downstream tasks while feature encoders can adjust to provide more task-specific information about its modality. In this paper, we analyze the MLLM instruction tuning from both theoretical and empirical perspectives, where we find the unbalanced learning between the feature encoder and the LLM can cause problems of oscillation and biased learning that lead to sub-optimal convergence. Inspired by our findings, we propose a Multimodal Balance Coefficient that enables quantitative measurement of the balance of learning. Based on this, we further design a dynamic learning scheduler that better coordinates the learning between the LLM and feature encoder, alleviating the problems of oscillation and biased learning. In addition, we introduce an auxiliary regularization on the gradient to promote updating with larger step sizes, which potentially allows for a more accurate estimation of the proposed MultiModal Balance Coefficient and further improves the training sufficiency. Our proposed approach is agnostic to the architecture of LLM and feature encoder, so it can be generically integrated with various MLLMs. We conduct experiments on multiple downstream tasks with various MLLMs, demonstrating that the proposed method is more effective than the baselines in MLLM instruction tuning.