Dataset Distillation for Offline Reinforcement Learning
作者: Jonathan Light, Yuanzhe Liu, Ziniu Hu
分类: cs.LG, cs.AI
发布日期: 2024-07-29 (更新: 2025-11-03)
备注: ICML 2024 DMLR Workshop Our project site is available at https://datasetdistillation4rl.github.io We also provide our implementation at https://github.com/ggflow123/DDRL
🔗 代码/项目: GITHUB
💡 一句话要点
提出用于离线强化学习的数据集蒸馏方法,提升策略训练效果。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 数据集蒸馏 策略学习 行为克隆 数据合成
📋 核心要点
- 离线强化学习受限于数据集质量,高质量数据集难以获取,直接训练策略效果不佳。
- 利用数据蒸馏技术,生成更优数据集,提升离线强化学习策略的训练效果。
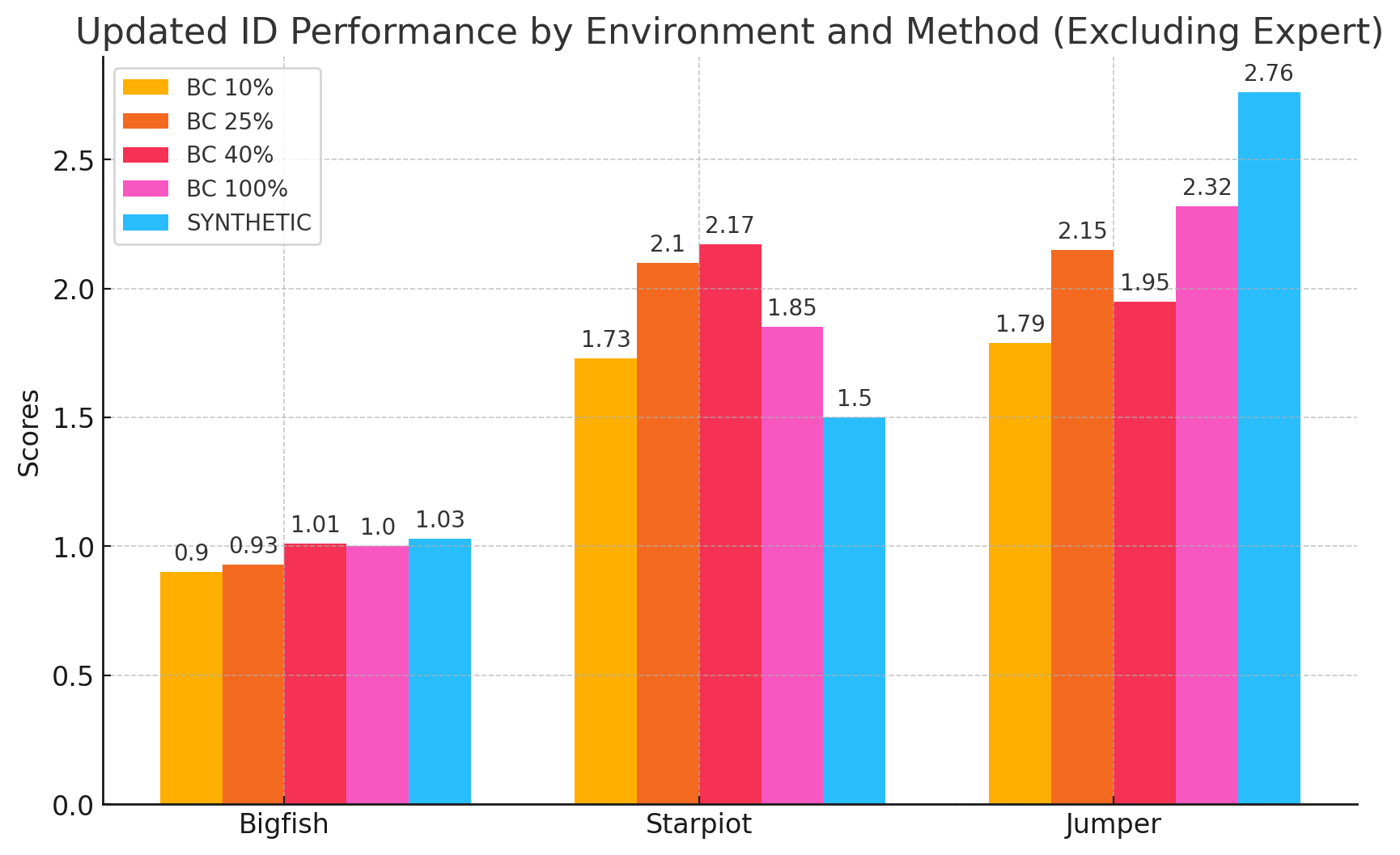
- 实验表明,使用蒸馏数据集训练的模型性能可媲美在完整数据集上训练的模型。
📝 摘要(中文)
离线强化学习通常需要高质量的数据集来训练策略。然而,在许多情况下,获取这样的数据集是不可能的,或者在给定离线数据的情况下,训练一个在实际环境中表现良好的策略也很困难。我们提出使用数据蒸馏来训练和提炼一个更好的数据集,然后可以使用该数据集来训练更好的策略模型。我们表明,我们的方法能够合成一个数据集,在该数据集上训练的模型可以达到与在完整数据集上训练的模型或使用百分位行为克隆训练的模型相似的性能。我们的项目网站可在 https://datasetdistillation4rl.github.io 找到。我们还在 https://github.com/ggflow123/DDRL 提供了我们的实现。
🔬 方法详解
问题定义:离线强化学习面临的关键问题是如何利用有限且可能质量不高的数据集训练出有效的策略。现有方法要么依赖于高质量的离线数据,要么难以从次优数据集中提取有效信息,导致策略性能受限。
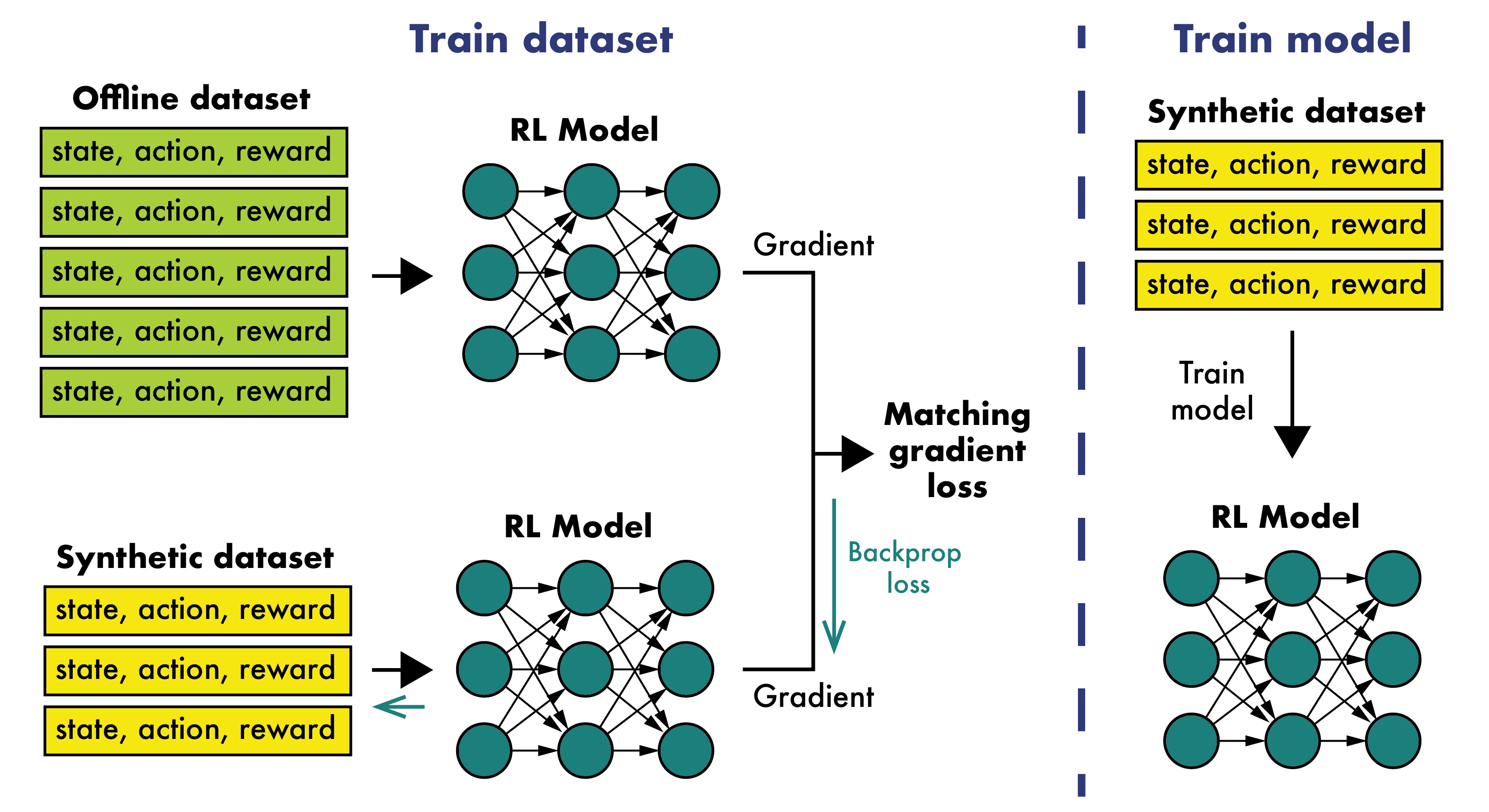
核心思路:论文的核心思路是通过数据蒸馏技术,从原始离线数据集中学习并生成一个更小、更优化的数据集。这个蒸馏后的数据集能够更好地代表原始数据的关键信息,从而使策略能够更有效地学习。
技术框架:整体框架包含两个主要阶段:首先,利用原始离线数据集训练一个初始策略模型。然后,使用该策略模型作为“教师”,指导生成一个更小的数据集,该数据集能够使一个“学生”策略模型达到与“教师”策略模型相似的性能。这个过程可以迭代进行,逐步提升数据集的质量。
关键创新:该方法的核心创新在于将数据蒸馏技术应用于离线强化学习领域。与传统的离线强化学习方法不同,该方法不是直接在原始数据集上训练策略,而是先通过数据蒸馏生成一个更优的数据集,然后再进行策略训练。这种方法能够有效地克服原始数据集质量不高的问题。
关键设计:关键设计包括如何定义“教师”和“学生”策略模型之间的相似性,以及如何优化蒸馏数据集以最大程度地提高“学生”策略模型的性能。具体的损失函数和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
论文表明,使用该方法蒸馏出的数据集训练的模型,其性能可以达到与在完整数据集上训练的模型或使用百分位行为克隆训练的模型相似的水平。具体的性能提升数据未知,但结果表明该方法在离线强化学习中具有显著的潜力。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、游戏AI等领域,尤其是在难以获取高质量训练数据的场景下。通过数据蒸馏,可以利用现有的次优数据生成更有效的数据集,从而降低数据收集成本,加速策略学习过程,并提升最终策略的性能。
📄 摘要(原文)
Offline reinforcement learning often requires a quality dataset that we can train a policy on. However, in many situations, it is not possible to get such a dataset, nor is it easy to train a policy to perform well in the actual environment given the offline data. We propose using data distillation to train and distill a better dataset which can then be used for training a better policy model. We show that our method is able to synthesize a dataset where a model trained on it achieves similar performance to a model trained on the full dataset or a model trained using percentile behavioral cloning. Our project site is available at https://datasetdistillation4rl.github.io . We also provide our implementation at https://github.com/ggflow123/DDRL .