SAPG: Split and Aggregate Policy Gradients
作者: Jayesh Singla, Ananye Agarwal, Deepak Pathak
分类: cs.LG, cs.AI, cs.CV, cs.RO, eess.SY
发布日期: 2024-07-29
备注: In ICML 2024 (Oral). Website at https://sapg-rl.github.io/
💡 一句话要点
提出SAPG算法,通过分割聚合策略梯度有效利用大规模并行环境
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 策略梯度 并行计算 重要性采样 环境分割 大规模环境
📋 核心要点
- 现有on-policy强化学习方法,如PPO,在大规模并行环境下性能提升受限,无法充分利用算力。
- SAPG算法将环境分割成多个块,然后通过重要性采样将它们融合,从而有效利用大规模环境。
- 实验表明,SAPG在多种复杂环境中显著优于PPO等基线方法,实现了更高的性能。
📝 摘要(中文)
尽管策略梯度等on-policy强化学习方法存在样本效率低下的问题,但它已成为决策问题的基本工具。随着GPU驱动模拟技术的进步,用于强化学习训练的数据收集能力呈指数级增长。然而,我们发现现有的强化学习方法,例如PPO,在超过一定程度后,无法充分利用并行环境的优势,其性能会饱和。为了解决这个问题,我们提出了一种新的on-policy强化学习算法,该算法可以通过将大规模环境分割成块,并通过重要性采样将它们融合在一起来有效地利用这些环境。我们的算法被称为SAPG,在各种具有挑战性的环境中表现出明显更高的性能,而vanilla PPO和其他强大的基线方法无法在这些环境中实现高性能。
🔬 方法详解
问题定义:论文旨在解决现有on-policy强化学习算法(如PPO)在大规模并行环境下的性能瓶颈问题。随着GPU算力的提升,并行模拟环境的数量大幅增加,但现有算法无法有效利用这些并行环境,导致性能饱和。现有方法的痛点在于无法有效整合来自大量并行环境的梯度信息,导致训练效率低下。
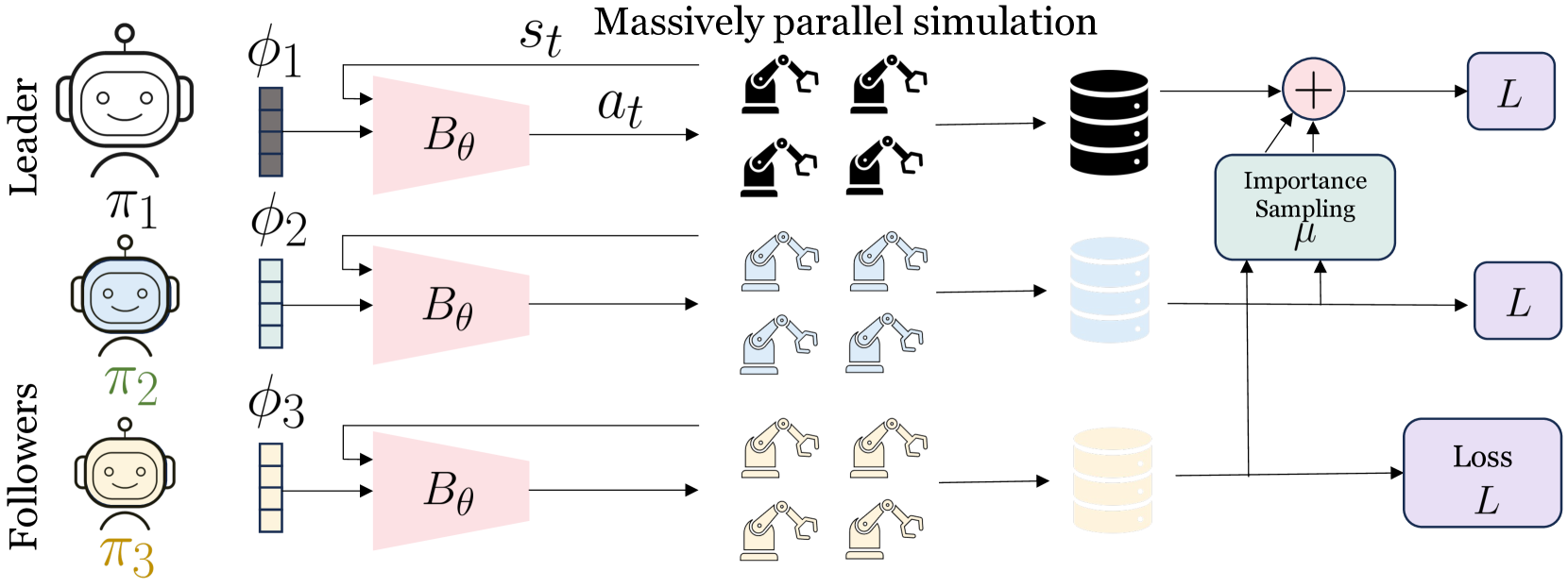
核心思路:SAPG的核心思路是将大规模并行环境分割成多个较小的块,每个块独立进行策略梯度计算,然后通过重要性采样将这些梯度信息聚合起来。这种分割-聚合的策略允许算法更好地利用每个并行环境的信息,避免了梯度信息在大量并行环境中被稀释的问题。
技术框架:SAPG算法的整体框架包括以下几个主要阶段:1) 环境分割:将大规模并行环境分割成多个块。2) 策略梯度计算:在每个块中独立计算策略梯度。3) 重要性采样:使用重要性采样来校正由于环境分割引入的偏差。4) 梯度聚合:将校正后的梯度信息聚合起来,更新策略网络。
关键创新:SAPG最重要的技术创新点在于其分割-聚合的策略梯度计算方法。与传统的PPO等算法直接在整个并行环境上计算梯度不同,SAPG通过分割环境并使用重要性采样进行校正,从而能够更有效地利用大规模并行环境的信息。这种方法可以显著提高训练效率,并实现更高的性能。
关键设计:SAPG的关键设计包括:1) 环境分割策略:如何将大规模环境分割成多个块,需要考虑块的大小和数量。2) 重要性采样权重:如何计算重要性采样权重,以准确校正由于环境分割引入的偏差。3) 梯度聚合方法:如何将校正后的梯度信息聚合起来,需要考虑不同块之间的权重分配。
🖼️ 关键图片
📊 实验亮点
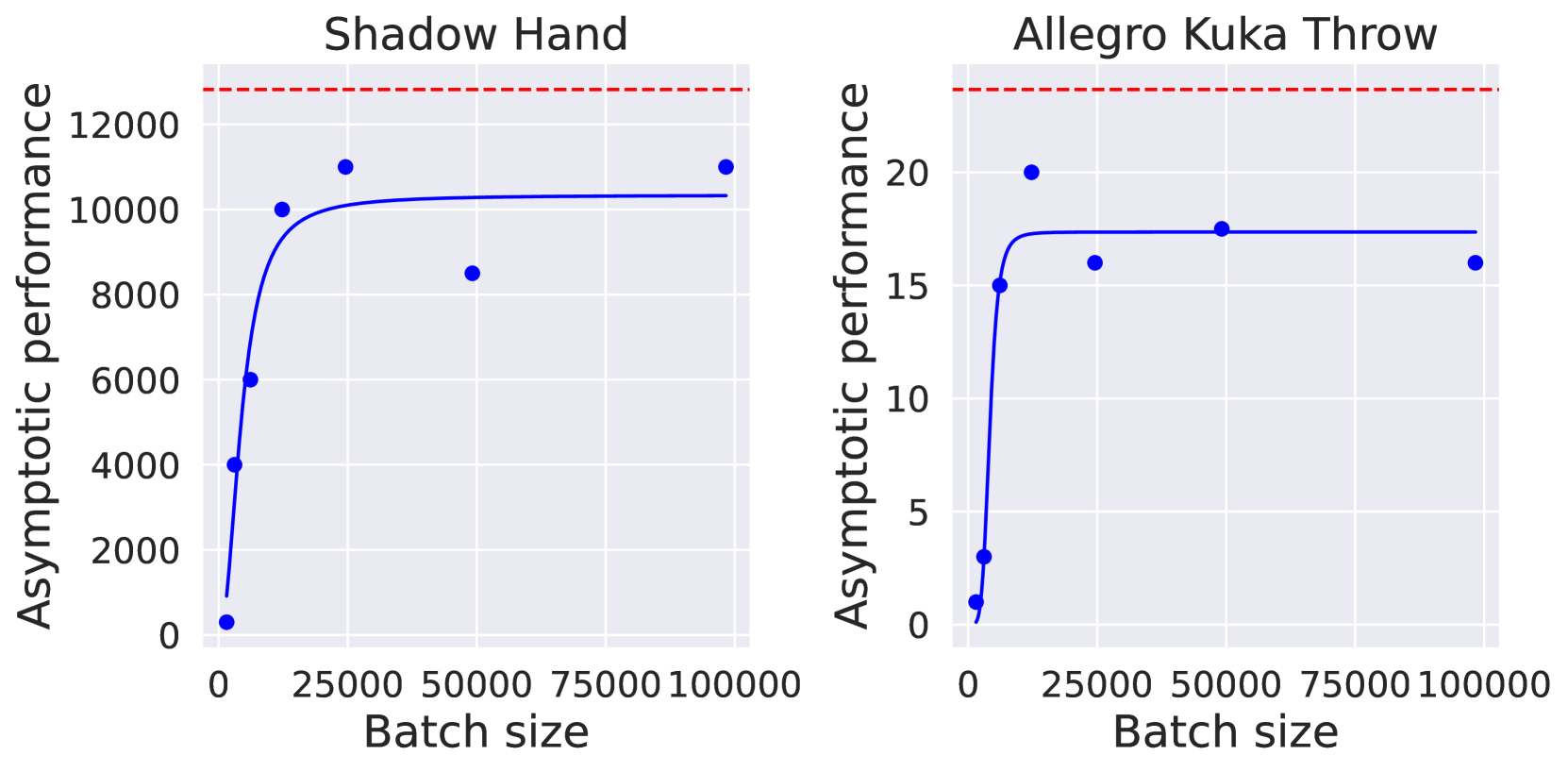
SAPG算法在多个具有挑战性的环境中进行了评估,实验结果表明,SAPG显著优于PPO等基线方法。例如,在某些环境中,SAPG的性能提升幅度超过50%。实验还表明,SAPG能够更好地利用大规模并行环境,随着并行环境数量的增加,SAPG的性能持续提升,而PPO等基线方法则出现性能饱和。
🎯 应用场景
SAPG算法具有广泛的应用前景,可以应用于机器人控制、游戏AI、自动驾驶等需要大规模并行环境进行强化学习训练的领域。该算法能够有效利用高性能计算资源,加速强化学习模型的训练,并提高模型的性能。未来,SAPG可以进一步扩展到更复杂的环境和任务中,例如多智能体强化学习和元强化学习。
📄 摘要(原文)
Despite extreme sample inefficiency, on-policy reinforcement learning, aka policy gradients, has become a fundamental tool in decision-making problems. With the recent advances in GPU-driven simulation, the ability to collect large amounts of data for RL training has scaled exponentially. However, we show that current RL methods, e.g. PPO, fail to ingest the benefit of parallelized environments beyond a certain point and their performance saturates. To address this, we propose a new on-policy RL algorithm that can effectively leverage large-scale environments by splitting them into chunks and fusing them back together via importance sampling. Our algorithm, termed SAPG, shows significantly higher performance across a variety of challenging environments where vanilla PPO and other strong baselines fail to achieve high performance. Website at https://sapg-rl.github.io/