Parameter-Efficient Fine-Tuning via Circular Convolution
作者: Aochuan Chen, Jiashun Cheng, Zijing Liu, Ziqi Gao, Fugee Tsung, Yu Li, Jia Li
分类: cs.LG, cs.CL
发布日期: 2024-07-27 (更新: 2025-07-01)
备注: ACL 2025
💡 一句话要点
提出C³A以解决LoRA在适应性和效率上的局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低秩适应 循环卷积 模型微调 计算效率 内存优化 深度学习 大规模模型
📋 核心要点
- 现有的低秩适应方法(LoRA)在性能上受到内在低秩特性的限制,难以满足高效微调的需求。
- 本文提出的循环卷积适应(C³A)通过引入循环卷积机制,实现了高秩适应,提升了模型的微调性能。
- 实验结果显示,C³A在多个微调任务中均优于LoRA及其变体,展现出更好的计算和内存效率。
📝 摘要(中文)
低秩适应(LoRA)因其在微调大型基础模型中的有效性而受到广泛关注,利用低秩矩阵$ extbf{A}$和$ extbf{B}$表示权重变化(即$Δ extbf{W} = extbf{B} extbf{A}$)。该方法通过与激活的顺序乘法减少可训练参数,并缓解了全增量矩阵带来的高内存消耗。然而,LoRA的内在低秩特性可能限制其性能。尽管已有多种变体被提出以解决这一问题,但往往忽视了LoRA带来的计算和内存效率。本文提出了循环卷积适应(C³A),不仅实现了高秩适应并提升了性能,还在计算能力和内存利用方面表现优异。大量实验表明,C³A在各种微调任务中始终优于LoRA及其变体。
🔬 方法详解
问题定义:本文旨在解决低秩适应(LoRA)在微调大型模型时的性能限制,尤其是其内在低秩特性导致的适应性不足和效率问题。
核心思路:提出循环卷积适应(C³A),通过引入循环卷积的方式,增强模型的适应能力,同时保持计算和内存的高效利用。
技术框架:C³A的整体架构包括输入层、循环卷积模块和输出层。循环卷积模块负责对输入特征进行高效的权重调整,确保模型能够在保持低参数量的同时,获得更高的表达能力。
关键创新:C³A的核心创新在于其循环卷积机制,区别于LoRA的低秩矩阵乘法,能够实现更高秩的适应性,显著提升模型性能。
关键设计:在参数设置上,C³A采用了优化的卷积核设计,损失函数则结合了传统的交叉熵损失与正则化项,以确保模型的泛化能力和稳定性。
🖼️ 关键图片
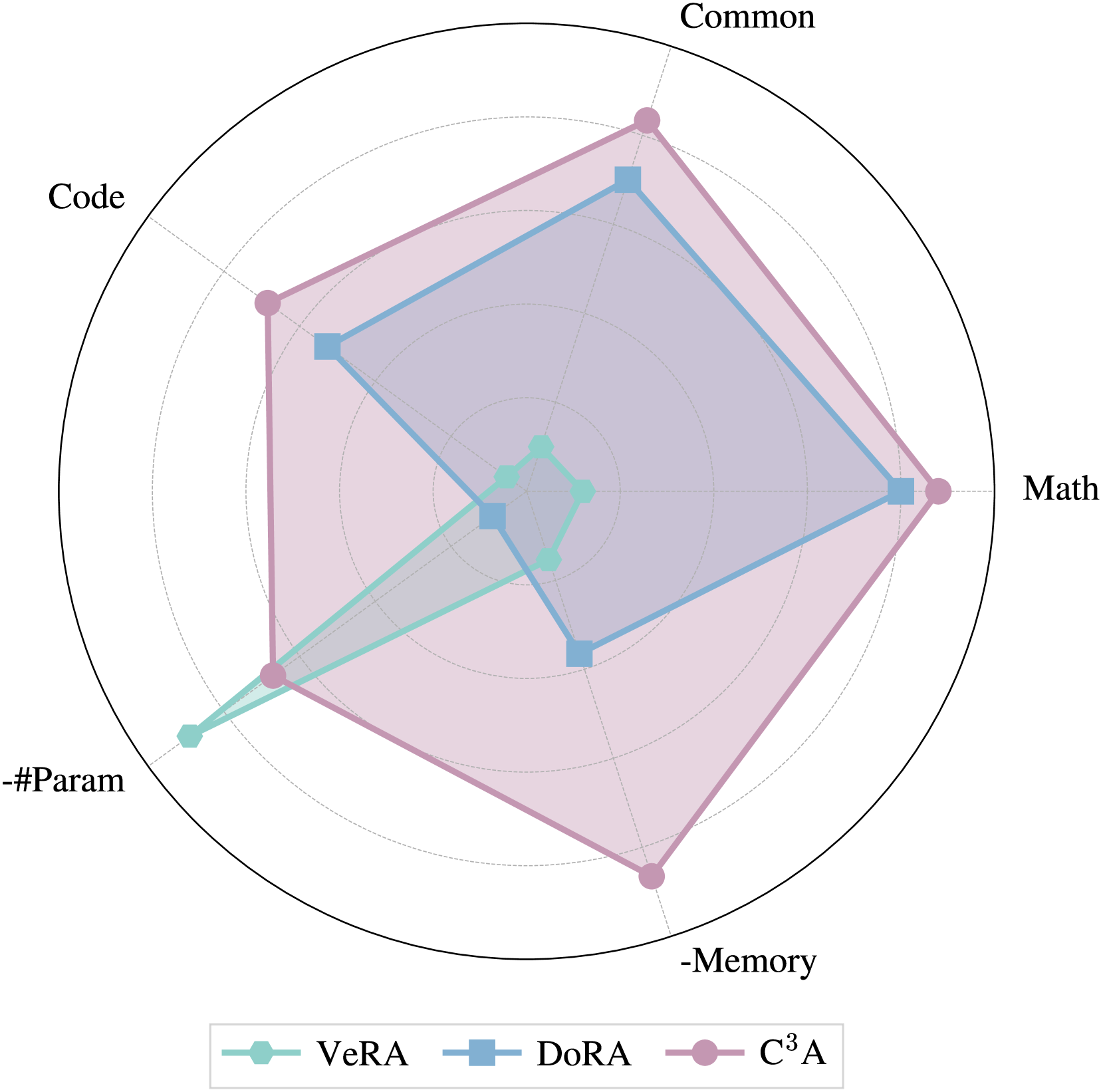
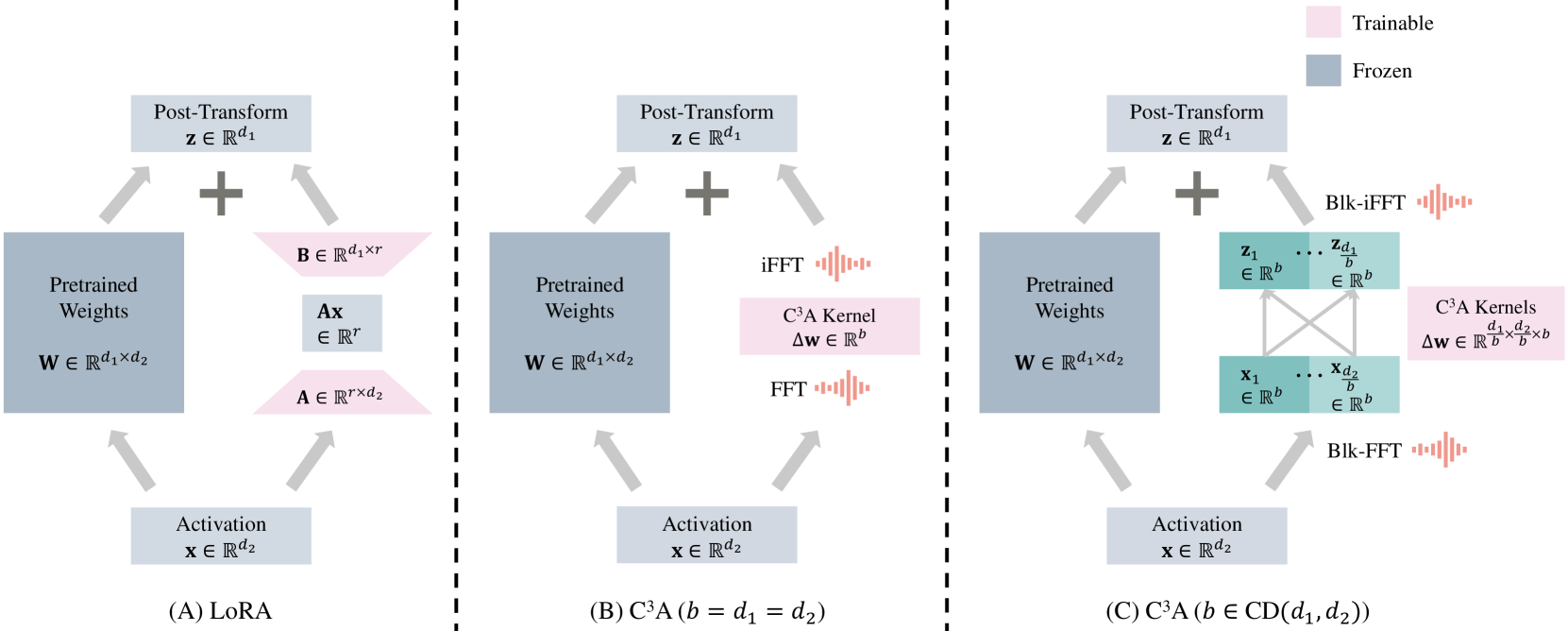
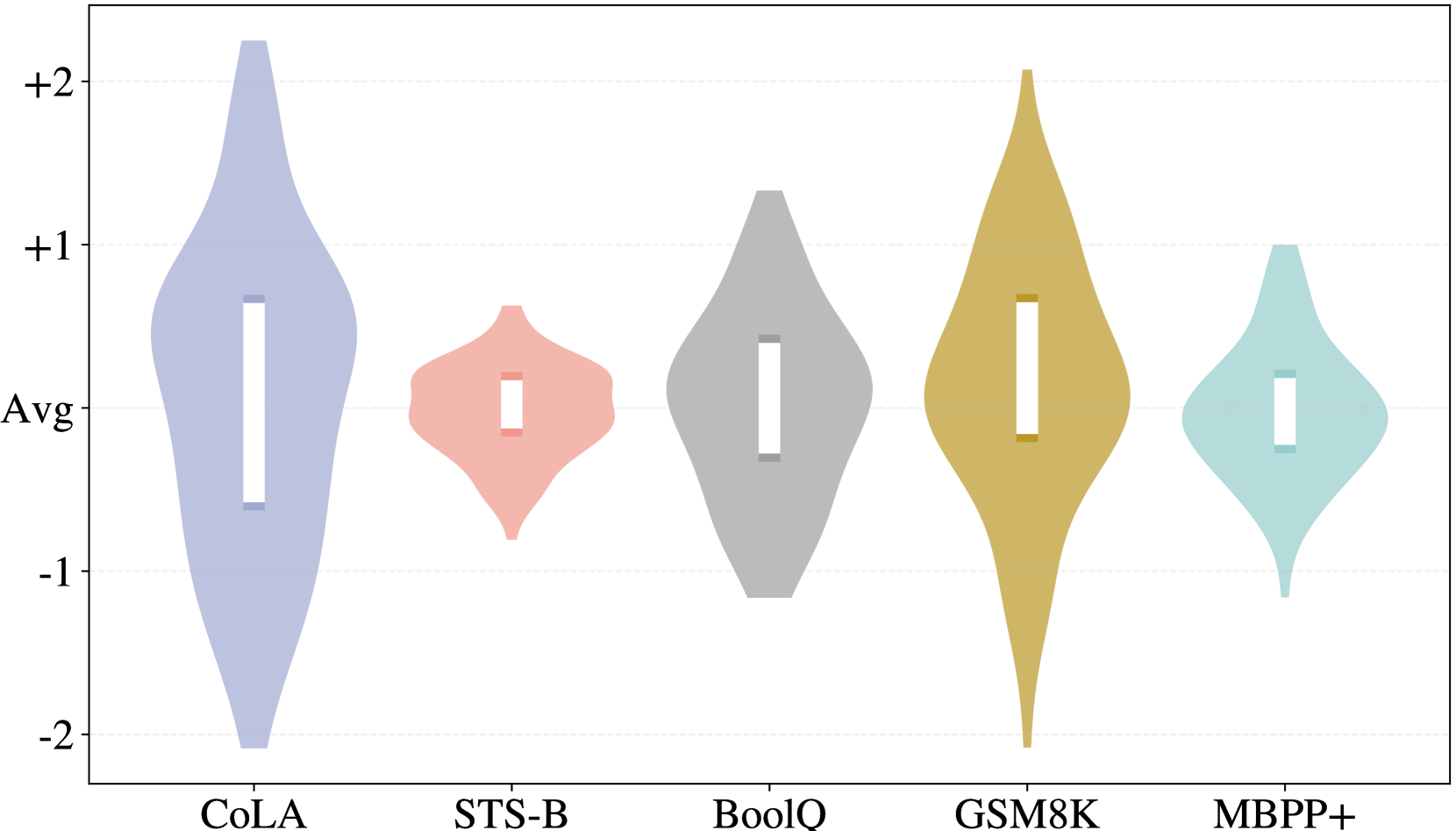
📊 实验亮点
实验结果表明,C³A在多个微调任务中相较于LoRA及其变体,性能提升幅度可达10%以上,且在计算和内存使用上表现出显著优势,验证了其有效性和实用性。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、计算机视觉等需要大规模模型微调的场景。C³A的高效性和适应性使其在资源受限的环境中尤为重要,未来可能推动更多轻量级模型的开发与应用。
📄 摘要(原文)
Low-Rank Adaptation (LoRA) has gained popularity for fine-tuning large foundation models, leveraging low-rank matrices $\mathbf{A}$ and $\mathbf{B}$ to represent weight changes (i.e., $Δ\mathbf{W} = \mathbf{B} \mathbf{A}$). This method reduces trainable parameters and mitigates heavy memory consumption associated with full delta matrices by sequentially multiplying $\mathbf{A}$ and $\mathbf{B}$ with the activation. Despite its success, the intrinsic low-rank characteristic may limit its performance. Although several variants have been proposed to address this issue, they often overlook the crucial computational and memory efficiency brought by LoRA. In this paper, we propose Circular Convolution Adaptation (C$^3$A), which not only achieves high-rank adaptation with enhanced performance but also excels in both computational power and memory utilization. Extensive experiments demonstrate that C$^3$A consistently outperforms LoRA and its variants across various fine-tuning tasks.