SOAP-RL: Sequential Option Advantage Propagation for Reinforcement Learning in POMDP Environments
作者: Shu Ishida, João F. Henriques
分类: cs.LG, cs.AI
发布日期: 2024-07-26 (更新: 2024-10-11)
🔗 代码/项目: GITHUB
💡 一句话要点
SOAP-RL:在POMDP环境中利用序列化选项优势传播进行强化学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 部分可观察马尔可夫决策过程 选项 优势传播 策略梯度 时间反向传播 POMDP 序列决策
📋 核心要点
- 现有方法难以在部分可观察环境中学习时间一致的选项和子策略,缺乏有效的选项发现机制。
- SOAP-RL通过扩展广义优势估计(GAE)来传播选项优势,实现选项策略梯度的时间反向传播。
- 实验表明,SOAP-RL在POMDP环境、Atari和MuJoCo基准测试中均优于其他方法,展现了更强的鲁棒性。
📝 摘要(中文)
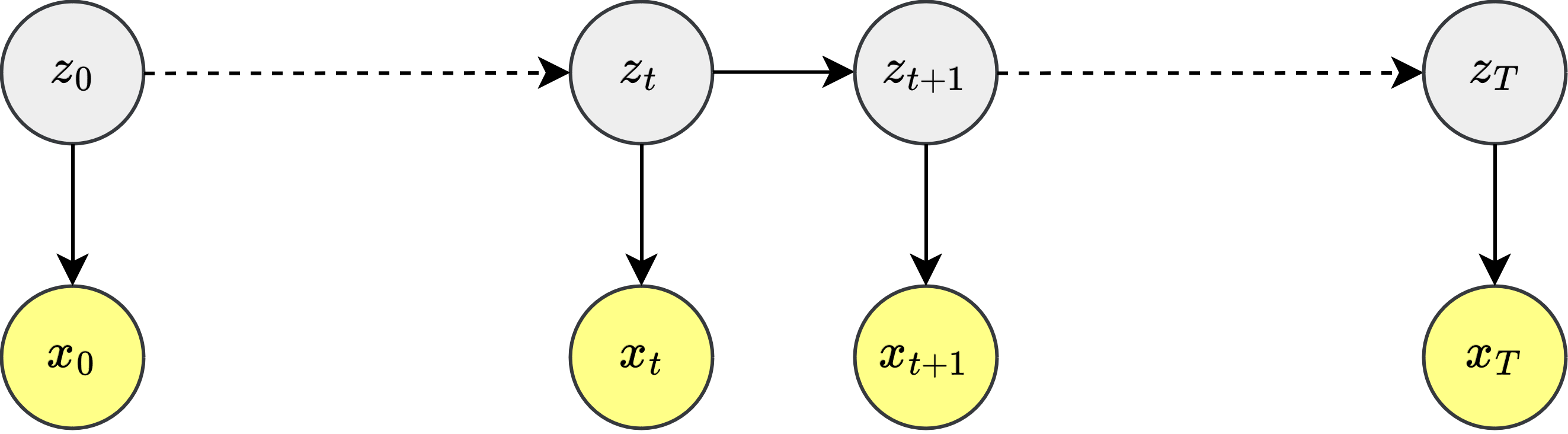
本研究比较了将强化学习算法扩展到具有选项的部分可观察马尔可夫决策过程(POMDP)的方法。选项可以被视为时间扩展的动作,它可以通过记忆来使智能体保留超出策略上下文窗口的历史信息。虽然选项分配可以使用启发式方法和手工设计的优化目标来处理,但在没有显式监督的情况下学习时间一致的选项和相关的子策略是一个挑战。论文提出了两种算法,PPOEM和SOAP,并深入研究以解决这个问题。PPOEM应用前向-后向算法(用于隐马尔可夫模型)来优化选项增强策略的预期回报。然而,这种学习方法在on-policy rollout期间不稳定。它也不适合在不知道未来轨迹的情况下学习因果策略,因为选项分配是针对离线序列进行优化的,在离线序列中可以获得整个episode。作为一种替代方法,SOAP评估了最优选项分配的策略梯度。它将广义优势估计(GAE)的概念扩展到随时间传播选项优势,这在分析上等同于执行选项策略梯度的时间反向传播。这种选项策略仅取决于智能体的历史,而不取决于未来的动作。与竞争基线相比,SOAP表现出最稳健的性能,正确地发现了POMDP走廊环境的选项,以及包括Atari和MuJoCo在内的标准基准,优于PPOEM以及LSTM和Option-Critic基线。开源代码可在https://github.com/shuishida/SoapRL获得。
🔬 方法详解
问题定义:论文旨在解决部分可观察马尔可夫决策过程(POMDP)中,强化学习智能体如何有效地学习和利用选项(Options)的问题。现有方法,如直接使用LSTM或Option-Critic,在学习时间一致的选项和子策略方面存在困难,尤其是在缺乏明确监督的情况下。PPOEM虽然尝试使用前向-后向算法,但在on-policy学习中不稳定,且不适用于学习因果策略。
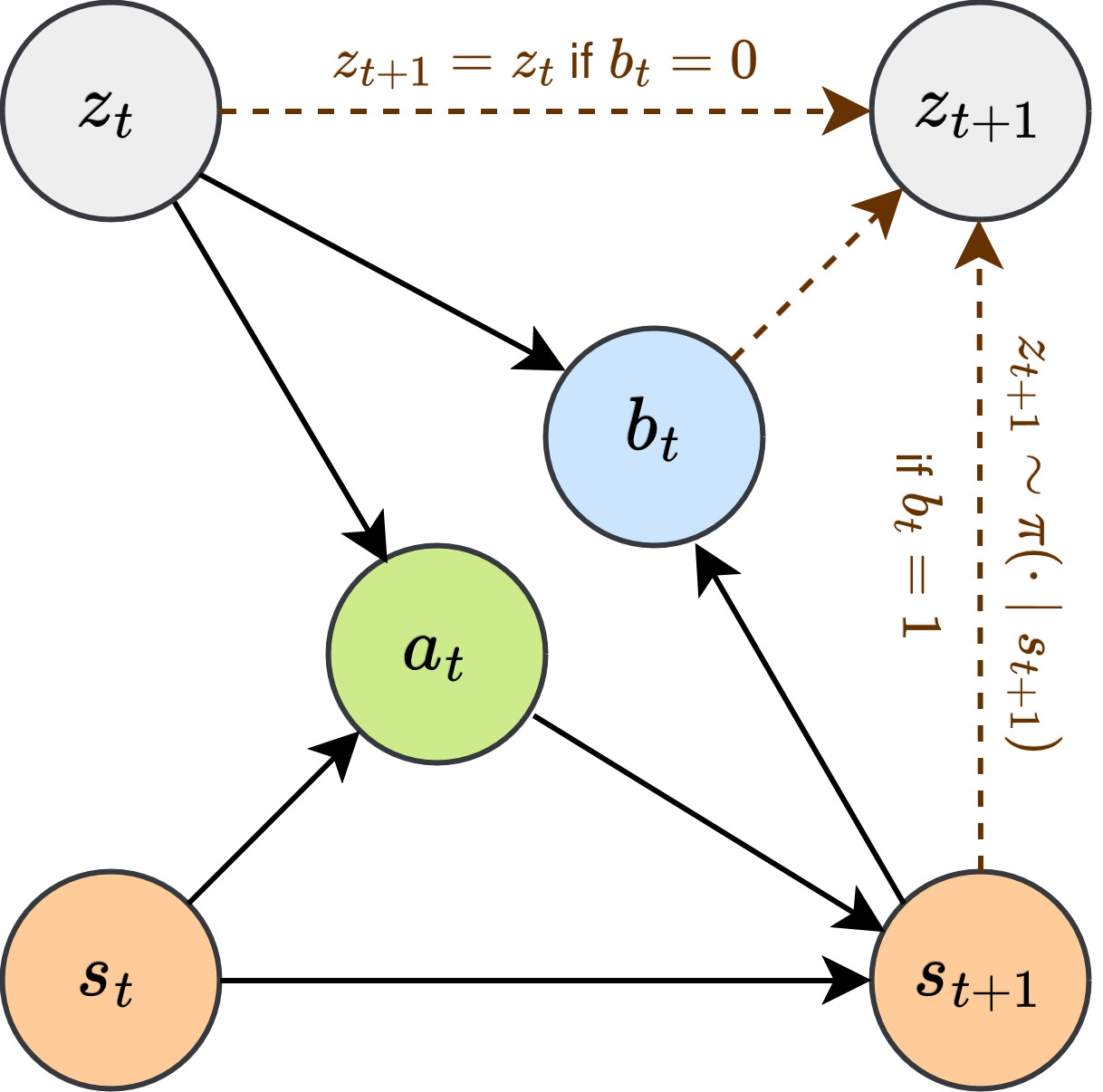
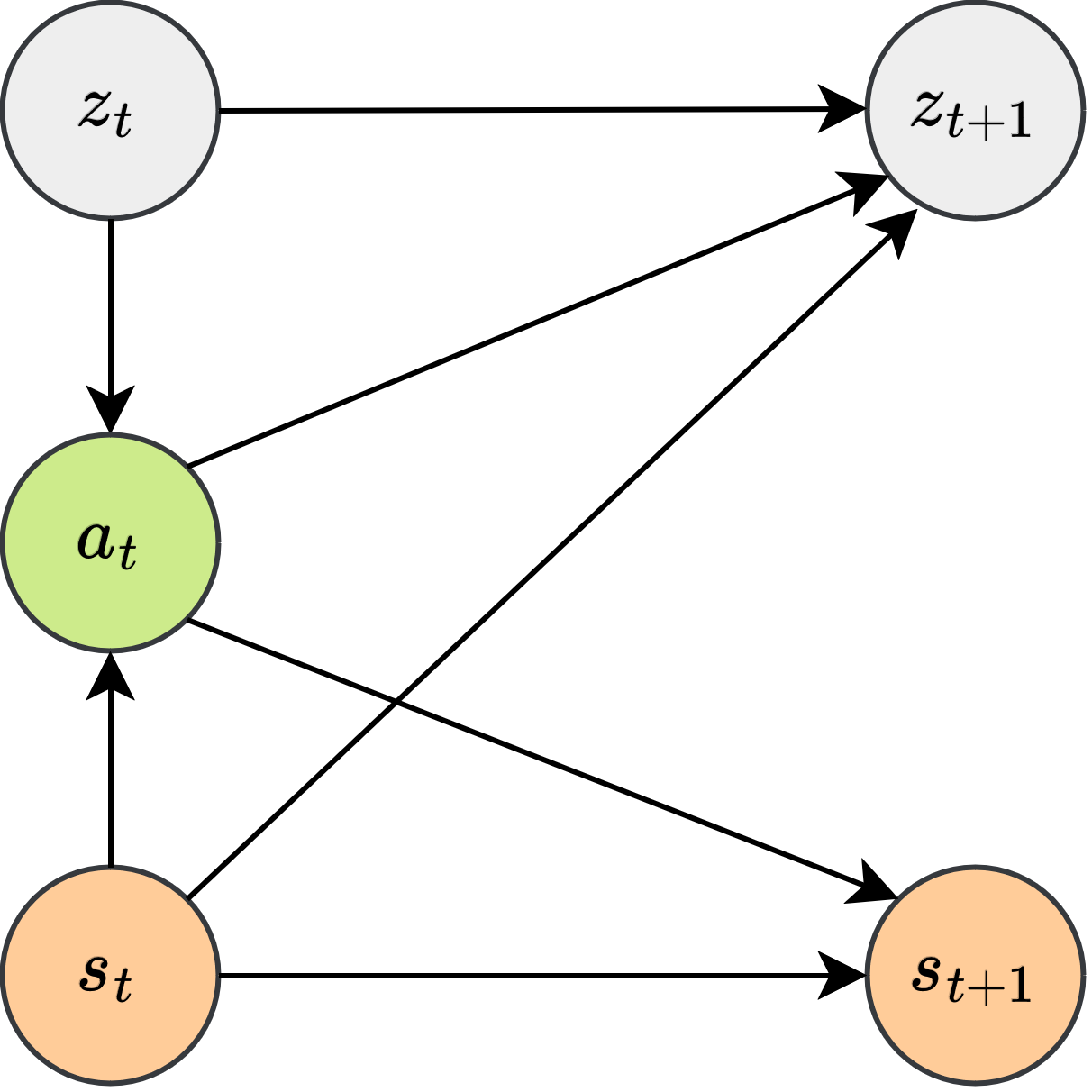
核心思路:SOAP-RL的核心思路是利用序列化的选项优势传播来学习选项策略。它将广义优势估计(GAE)的概念扩展到选项层面,通过时间反向传播选项策略梯度,使得智能体能够根据历史信息而非未来动作来选择合适的选项。这种方法旨在解决PPOEM在on-policy学习中的不稳定性问题,并使其更适合学习因果策略。
技术框架:SOAP-RL的整体框架基于策略梯度方法,并引入了选项的概念。主要包括以下几个阶段:1) 智能体与环境交互,收集经验数据;2) 使用广义优势估计(GAE)计算每个时间步的优势函数,并将其扩展到选项层面;3) 通过时间反向传播选项策略梯度,更新选项策略;4) 使用更新后的策略与环境交互,重复以上过程。
关键创新:SOAP-RL的关键创新在于提出了序列化选项优势传播机制。与传统的优势估计方法不同,SOAP-RL能够将优势信息在选项的时间跨度内进行传播,从而更有效地学习选项策略。这与PPOEM等方法依赖于完整episode信息进行选项分配有本质区别,使得SOAP-RL更适合在线学习和因果策略的学习。
关键设计:SOAP-RL的关键设计包括:1) 使用广义优势估计(GAE)来估计每个时间步的优势函数,并将其扩展到选项层面;2) 设计损失函数,用于优化选项策略,该损失函数基于策略梯度,并考虑了选项优势;3) 网络结构的设计需要能够处理历史信息,并输出选项的选择概率。具体的参数设置和网络结构可能因具体应用而异。
🖼️ 关键图片
📊 实验亮点
SOAP-RL在POMDP走廊环境、Atari和MuJoCo等多个基准测试中取得了显著的性能提升。实验结果表明,SOAP-RL能够正确地发现POMDP走廊环境中的选项,并在Atari和MuJoCo基准测试中优于PPOEM、LSTM和Option-Critic等基线方法。这表明SOAP-RL具有更强的鲁棒性和泛化能力。
🎯 应用场景
SOAP-RL在机器人导航、游戏AI、自动驾驶等领域具有广泛的应用前景。在这些领域中,智能体需要在部分可观察的环境中做出决策,并利用时间扩展的动作(选项)来提高效率和鲁棒性。SOAP-RL能够帮助智能体学习更有效的选项策略,从而更好地适应复杂环境,完成各种任务。
📄 摘要(原文)
This work compares ways of extending Reinforcement Learning algorithms to Partially Observed Markov Decision Processes (POMDPs) with options. One view of options is as temporally extended action, which can be realized as a memory that allows the agent to retain historical information beyond the policy's context window. While option assignment could be handled using heuristics and hand-crafted objectives, learning temporally consistent options and associated sub-policies without explicit supervision is a challenge. Two algorithms, PPOEM and SOAP, are proposed and studied in depth to address this problem. PPOEM applies the forward-backward algorithm (for Hidden Markov Models) to optimize the expected returns for an option-augmented policy. However, this learning approach is unstable during on-policy rollouts. It is also unsuited for learning causal policies without the knowledge of future trajectories, since option assignments are optimized for offline sequences where the entire episode is available. As an alternative approach, SOAP evaluates the policy gradient for an optimal option assignment. It extends the concept of the generalized advantage estimation (GAE) to propagate option advantages through time, which is an analytical equivalent to performing temporal back-propagation of option policy gradients. This option policy is only conditional on the history of the agent, not future actions. Evaluated against competing baselines, SOAP exhibited the most robust performance, correctly discovering options for POMDP corridor environments, as well as on standard benchmarks including Atari and MuJoCo, outperforming PPOEM, as well as LSTM and Option-Critic baselines. The open-sourced code is available at https://github.com/shuishida/SoapRL.