LoRA-Pro: Are Low-Rank Adapters Properly Optimized?
作者: Zhengbo Wang, Jian Liang, Ran He, Zilei Wang, Tieniu Tan
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-07-25 (更新: 2025-03-22)
备注: Camera-Ready Version for ICLR 2025; technical corrections to previous version
🔗 代码/项目: GITHUB
💡 一句话要点
LoRA-Pro:通过优化低秩矩阵梯度,显著提升LoRA微调性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低秩适应 参数高效微调 梯度优化 基础模型 自然语言处理
📋 核心要点
- LoRA虽然高效,但性能不如全参数微调,主要挑战在于其低秩梯度对全参数梯度近似不足。
- LoRA-Pro通过调整LoRA中低秩矩阵的梯度,使低秩梯度更准确地逼近全参数微调梯度。
- 实验表明,LoRA-Pro在多个任务上显著提升了LoRA的性能,缩小了与全参数微调的差距。
📝 摘要(中文)
低秩适应(LoRA)已成为基础模型参数高效微调的重要方法。尽管LoRA具有计算效率,但与全参数微调相比,其性能仍然较差。本文首先揭示了LoRA和全参数微调优化过程之间的根本联系:使用LoRA进行优化在数学上等价于使用低秩梯度进行全参数微调。并且,该低秩梯度可以用LoRA中两个低秩矩阵的梯度来表示。基于此,我们提出了LoRA-Pro,一种通过策略性地调整这些低秩矩阵的梯度来增强LoRA性能的方法。这种调整使低秩梯度能够更准确地逼近全参数微调梯度,从而缩小LoRA和全参数微调之间的性能差距。此外,我们从理论上推导出了调整低秩矩阵梯度的最优解,并在LoRA-Pro的微调过程中应用它们。我们在自然语言理解、对话生成、数学推理、代码生成和图像分类任务上进行了广泛的实验,结果表明LoRA-Pro显著提高了LoRA的性能,有效地缩小了与全参数微调的差距。代码已公开。
🔬 方法详解
问题定义:LoRA虽然参数高效,但其微调性能与全参数微调存在差距。现有的LoRA方法在优化过程中,低秩梯度对全参数梯度的近似不够准确,导致模型性能受限。因此,如何提升LoRA的微调性能,使其更接近全参数微调的效果,是本文要解决的核心问题。
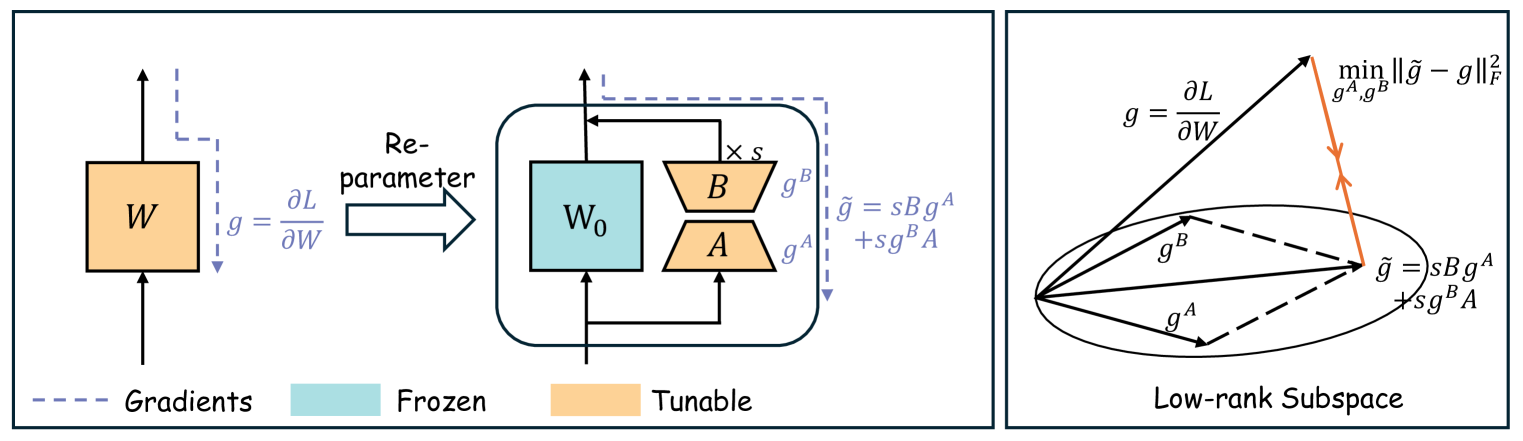
核心思路:论文的核心思路是,通过调整LoRA中低秩矩阵的梯度,使得最终的低秩梯度能够更准确地逼近全参数微调的梯度。作者发现LoRA的优化过程本质上等价于使用低秩梯度进行全参数微调,因此优化低秩梯度是提升LoRA性能的关键。
技术框架:LoRA-Pro的整体框架仍然基于LoRA,主要改进在于梯度的计算和更新方式。具体流程如下:1) 使用LoRA进行前向传播和损失计算;2) 计算LoRA中两个低秩矩阵的梯度;3) 根据理论推导的最优解,调整这两个低秩矩阵的梯度;4) 使用调整后的梯度更新LoRA的参数。
关键创新:LoRA-Pro最重要的创新在于,它从理论上推导出了调整低秩矩阵梯度的最优解。这个最优解能够使得低秩梯度更准确地逼近全参数微调的梯度,从而提升LoRA的性能。与现有LoRA方法相比,LoRA-Pro的关键区别在于对梯度的处理方式,它不是直接使用原始梯度,而是通过调整来优化梯度。
关键设计:论文的关键设计在于如何确定调整低秩矩阵梯度的最优解。作者通过数学推导,将这个问题转化为一个优化问题,并找到了闭式解。具体来说,最优解依赖于LoRA中两个低秩矩阵的梯度以及全参数微调的梯度(在实际应用中,全参数微调的梯度可以通过少量样本估计得到)。此外,LoRA-Pro的损失函数与原始LoRA相同,网络结构也保持不变。
🖼️ 关键图片
📊 实验亮点
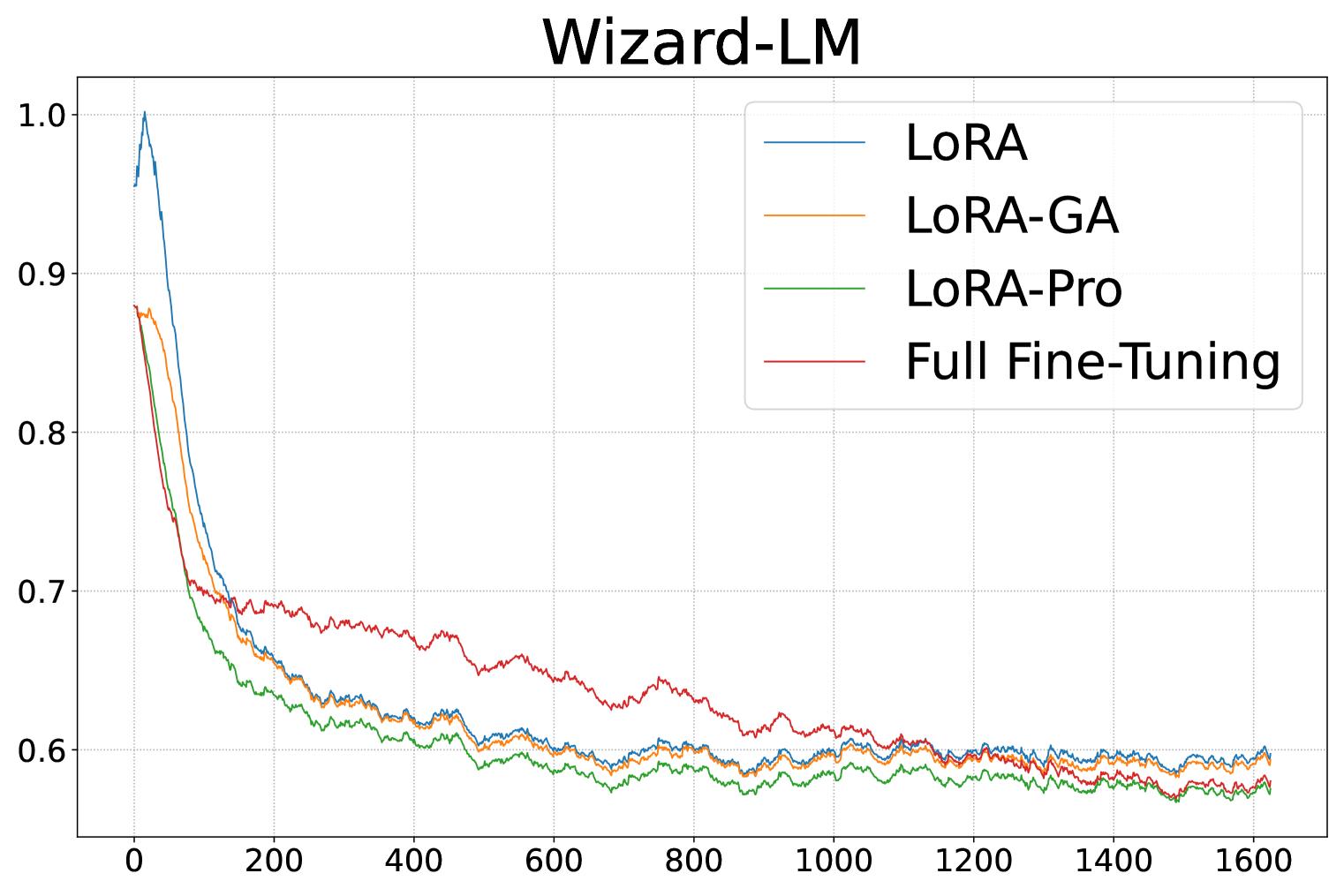
实验结果表明,LoRA-Pro在自然语言理解、对话生成、数学推理、代码生成和图像分类等多个任务上,显著提升了LoRA的性能。例如,在某些任务上,LoRA-Pro能够将LoRA的性能提升到接近全参数微调的水平,有效地缩小了两者之间的差距。这些结果验证了LoRA-Pro的有效性和优越性。
🎯 应用场景
LoRA-Pro具有广泛的应用前景,可以应用于各种需要参数高效微调的场景,例如自然语言处理、计算机视觉等。特别是在资源受限的环境下,LoRA-Pro能够以较小的计算成本,实现接近全参数微调的性能,具有重要的实际价值。未来,LoRA-Pro可以进一步扩展到其他参数高效微调方法中,提升模型的泛化能力和鲁棒性。
📄 摘要(原文)
Low-rank adaptation, also known as LoRA, has emerged as a prominent method for parameter-efficient fine-tuning of foundation models. Despite its computational efficiency, LoRA still yields inferior performance compared to full fine-tuning. In this paper, we first uncover a fundamental connection between the optimization processes of LoRA and full fine-tuning: using LoRA for optimization is mathematically equivalent to full fine-tuning using a low-rank gradient for parameter updates. And this low-rank gradient can be expressed in terms of the gradients of the two low-rank matrices in LoRA. Leveraging this insight, we introduce LoRA-Pro, a method that enhances LoRA's performance by strategically adjusting the gradients of these low-rank matrices. This adjustment allows the low-rank gradient to more accurately approximate the full fine-tuning gradient, thereby narrowing the performance gap between LoRA and full fine-tuning. Furthermore, we theoretically derive the optimal solutions for adjusting the gradients of the low-rank matrices, applying them during fine-tuning in LoRA-Pro. We conduct extensive experiments across natural language understanding, dialogue generation, mathematical reasoning, code generation, and image classification tasks, demonstrating that LoRA-Pro substantially improves LoRA's performance, effectively narrowing the gap with full fine-tuning. Code is publicly available at https://github.com/mrflogs/LoRA-Pro.