Recursive Introspection: Teaching Language Model Agents How to Self-Improve
作者: Yuxiao Qu, Tianjun Zhang, Naman Garg, Aviral Kumar
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-07-25 (更新: 2024-07-26)
💡 一句话要点
提出RISE:通过递归自省提升语言模型在复杂推理任务中的自我改进能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自省 递归 微调 数学推理 模仿学习 强化学习
📋 核心要点
- 现有大型语言模型缺乏在推理过程中持续自省和纠正错误的能力,限制了其在复杂任务中的表现。
- RISE方法通过迭代微调,使模型能够递归地检测并纠正之前的错误,从而实现自我改进。
- 实验结果表明,RISE能够显著提升Llama2、Llama3和Mistral等模型在数学推理任务中的性能,且具有良好的扩展性。
📝 摘要(中文)
本文提出了一种名为RISE(Recursive IntroSpEction,递归自省)的方法,旨在通过微调使大型语言模型(LLMs)具备自省能力,从而能够推理并纠正自身错误。即使是最强大的专有LLM,也难以持续改进其顺序响应,尤其是在明确告知其犯错的情况下。RISE通过迭代微调过程,教导模型在先前尝试失败后,如何改变其响应以解决难题,并可选择性地加入环境反馈。RISE将单轮提示的微调视为解决多轮马尔可夫决策过程(MDP),其中初始状态为提示。受在线模仿学习和强化学习原则的启发,本文提出了多轮数据收集和训练策略,使LLM能够递归地检测和纠正后续迭代中的先前错误。实验表明,RISE使Llama2、Llama3和Mistral模型能够在数学推理任务中通过更多轮次改进自身,优于给定相同推理时间计算量的单轮策略。RISE还具有良好的扩展性,通常在更强大的模型上获得更大的收益。分析表明,RISE对响应进行了有意义的改进,从而为具有挑战性的提示找到了正确的解决方案,而不会因表达更复杂的分布而扰乱单轮能力。
🔬 方法详解
问题定义:现有的大型语言模型在复杂推理任务中,即使被告知犯错,也难以在后续推理步骤中有效地纠正错误,缺乏持续改进的能力。这限制了它们在需要多步推理和反馈的场景中的应用。现有方法通常是单轮的,无法利用多次尝试的机会来提升性能。
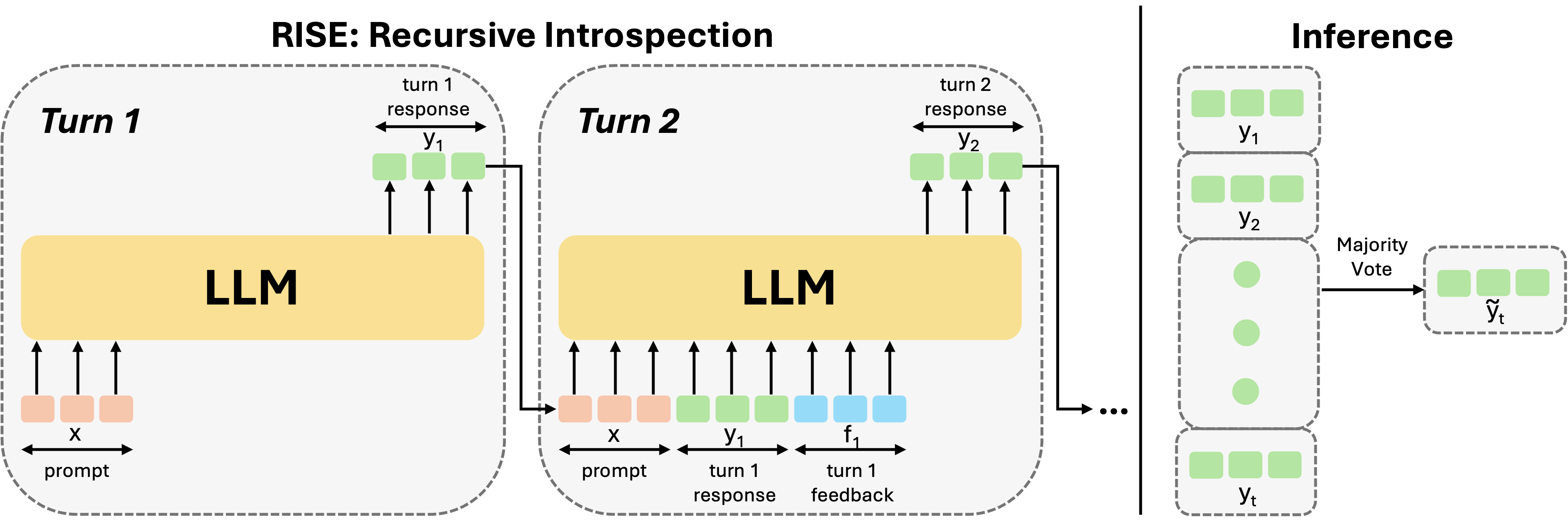
核心思路:RISE的核心思路是将单轮提示的微调过程视为一个多轮马尔可夫决策过程(MDP),模型在每一轮尝试后,可以根据之前的错误和环境反馈来调整其响应。通过模仿学习和强化学习的策略,训练模型在后续迭代中递归地检测和纠正之前的错误,从而实现自我改进。这种迭代式的自省和纠错机制使得模型能够逐步逼近正确的解决方案。
技术框架:RISE方法包含以下主要阶段:1) 数据收集:构建多轮对话数据集,其中包含模型在解决问题时的多次尝试和相应的反馈。2) 模型微调:使用收集到的数据对LLM进行微调,使其能够根据之前的错误和反馈来调整其响应。3) 迭代推理:在推理阶段,模型进行多次尝试,并在每次尝试后进行自省和纠错,直到达到预定的迭代次数或找到正确的解决方案。
关键创新:RISE的关键创新在于引入了递归自省的概念,将单轮推理转化为多轮迭代的自省和纠错过程。与传统的单轮方法相比,RISE能够充分利用多次尝试的机会,逐步改进模型的响应。此外,RISE还借鉴了在线模仿学习和强化学习的策略,有效地训练模型进行自省和纠错。
关键设计:在数据收集方面,论文设计了特定的提示模板和反馈机制,以引导模型进行自省和纠错。在模型微调方面,论文采用了特定的损失函数和优化策略,以确保模型能够有效地学习到自省和纠错的能力。具体的技术细节包括:使用特定的prompt引导模型进行反思,例如询问模型“你之前的尝试哪里出错了?”;使用模仿学习损失来鼓励模型模仿正确的纠错行为;使用强化学习奖励来鼓励模型找到正确的解决方案。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RISE能够显著提升Llama2、Llama3和Mistral等模型在数学推理任务中的性能。例如,在某些任务上,RISE可以将模型的准确率提高10%以上。此外,RISE还具有良好的扩展性,通常在更强大的模型上获得更大的收益。重要的是,RISE在提升模型复杂推理能力的同时,并没有损害其单轮推理能力。
🎯 应用场景
RISE方法具有广泛的应用前景,可以应用于各种需要复杂推理和问题解决的领域,例如数学推理、代码生成、自然语言理解等。通过提升模型的自我改进能力,RISE可以帮助LLM更好地适应各种任务,并提高其在实际应用中的性能和可靠性。未来,RISE还可以与其他技术相结合,例如知识图谱、外部工具等,以进一步提升LLM的智能水平。
📄 摘要(原文)
A central piece in enabling intelligent agentic behavior in foundation models is to make them capable of introspecting upon their behavior, reasoning, and correcting their mistakes as more computation or interaction is available. Even the strongest proprietary large language models (LLMs) do not quite exhibit the ability of continually improving their responses sequentially, even in scenarios where they are explicitly told that they are making a mistake. In this paper, we develop RISE: Recursive IntroSpEction, an approach for fine-tuning LLMs to introduce this capability, despite prior work hypothesizing that this capability may not be possible to attain. Our approach prescribes an iterative fine-tuning procedure, which attempts to teach the model how to alter its response after having executed previously unsuccessful attempts to solve a hard test-time problem, with optionally additional environment feedback. RISE poses fine-tuning for a single-turn prompt as solving a multi-turn Markov decision process (MDP), where the initial state is the prompt. Inspired by principles in online imitation learning and reinforcement learning, we propose strategies for multi-turn data collection and training so as to imbue an LLM with the capability to recursively detect and correct its previous mistakes in subsequent iterations. Our experiments show that RISE enables Llama2, Llama3, and Mistral models to improve themselves with more turns on math reasoning tasks, outperforming several single-turn strategies given an equal amount of inference-time computation. We also find that RISE scales well, often attaining larger benefits with more capable models. Our analysis shows that RISE makes meaningful improvements to responses to arrive at the correct solution for challenging prompts, without disrupting one-turn abilities as a result of expressing more complex distributions.