Scalify: scale propagation for efficient low-precision LLM training
作者: Paul Balança, Sam Hosegood, Carlo Luschi, Andrew Fitzgibbon
分类: cs.LG
发布日期: 2024-07-24
备注: 11 pages, 5 figures, ICML 2024 WANT workshop
🔗 代码/项目: GITHUB
💡 一句话要点
Scalify:面向低精度LLM训练的规模传播方法,提升计算效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低精度训练 规模传播 大型语言模型 计算效率 float8 张量缩放 JAX 优化器
📋 核心要点
- 低精度训练能提升效率,但现有技术复杂且难以保证精度,限制了其广泛应用。
- Scalify通过规模传播范式,泛化并形式化张量缩放方法,简化低精度训练流程。
- 实验表明,Scalify能有效支持float8矩阵运算和梯度表示,并兼容float16优化器。
📝 摘要(中文)
为了提高大型语言模型训练和推理的计算效率,机器学习加速硬件中引入了诸如float8之类的低精度格式。然而,由于需要复杂且有时脆弱的技术来匹配更高精度训练的准确性,ML社区的采用受到了阻碍。本文提出了Scalify,一种用于计算图的端到端规模传播范例,它概括并形式化了现有的张量缩放方法。实验结果表明,Scalify支持开箱即用的float8矩阵乘法和梯度表示,以及float16优化器状态存储。Scalify的JAX实现已开源。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)低精度训练方法,例如使用float8格式,虽然可以提升计算效率,但往往需要复杂的张量缩放和调整策略,以避免精度损失,保证模型收敛到与高精度训练相当的性能。这些复杂的技术使得低精度训练的门槛较高,阻碍了其在ML社区中的普及。
核心思路:Scalify的核心思路是通过在计算图中传播张量的尺度信息,动态地调整计算过程中的数值范围,从而避免溢出和下溢,保证低精度计算的稳定性和准确性。它将现有的张量缩放方法进行泛化和形式化,形成一个统一的规模传播框架。
技术框架:Scalify的整体框架基于计算图,在图中的每个节点上,Scalify会维护一个尺度因子(scale factor),用于调整输入和输出张量的数值范围。在计算过程中,尺度因子会随着计算图的传播而更新,以适应不同操作对数值范围的影响。Scalify主要包含以下阶段:1. 初始化:为每个张量分配初始尺度因子。2. 前向传播:在计算图中进行前向传播,同时更新尺度因子。3. 反向传播:在计算图中进行反向传播,计算梯度并更新尺度因子。
关键创新:Scalify的关键创新在于其端到端的规模传播范式,它将张量缩放过程集成到计算图中,实现了自动化的尺度调整。与现有的手动调整或启发式缩放方法相比,Scalify更加通用、灵活和易于使用。此外,Scalify还形式化了尺度传播的规则,使其更易于理解和扩展。
关键设计:Scalify的关键设计包括:1. 尺度因子的表示:尺度因子通常表示为一个浮点数,用于调整张量的数值范围。2. 尺度传播规则:Scalify定义了一系列尺度传播规则,用于在计算图中更新尺度因子。这些规则考虑了不同操作(如矩阵乘法、激活函数等)对数值范围的影响。3. 优化器集成:Scalify可以与现有的优化器(如Adam)集成,并支持使用更高精度的格式(如float16)存储优化器状态。
🖼️ 关键图片
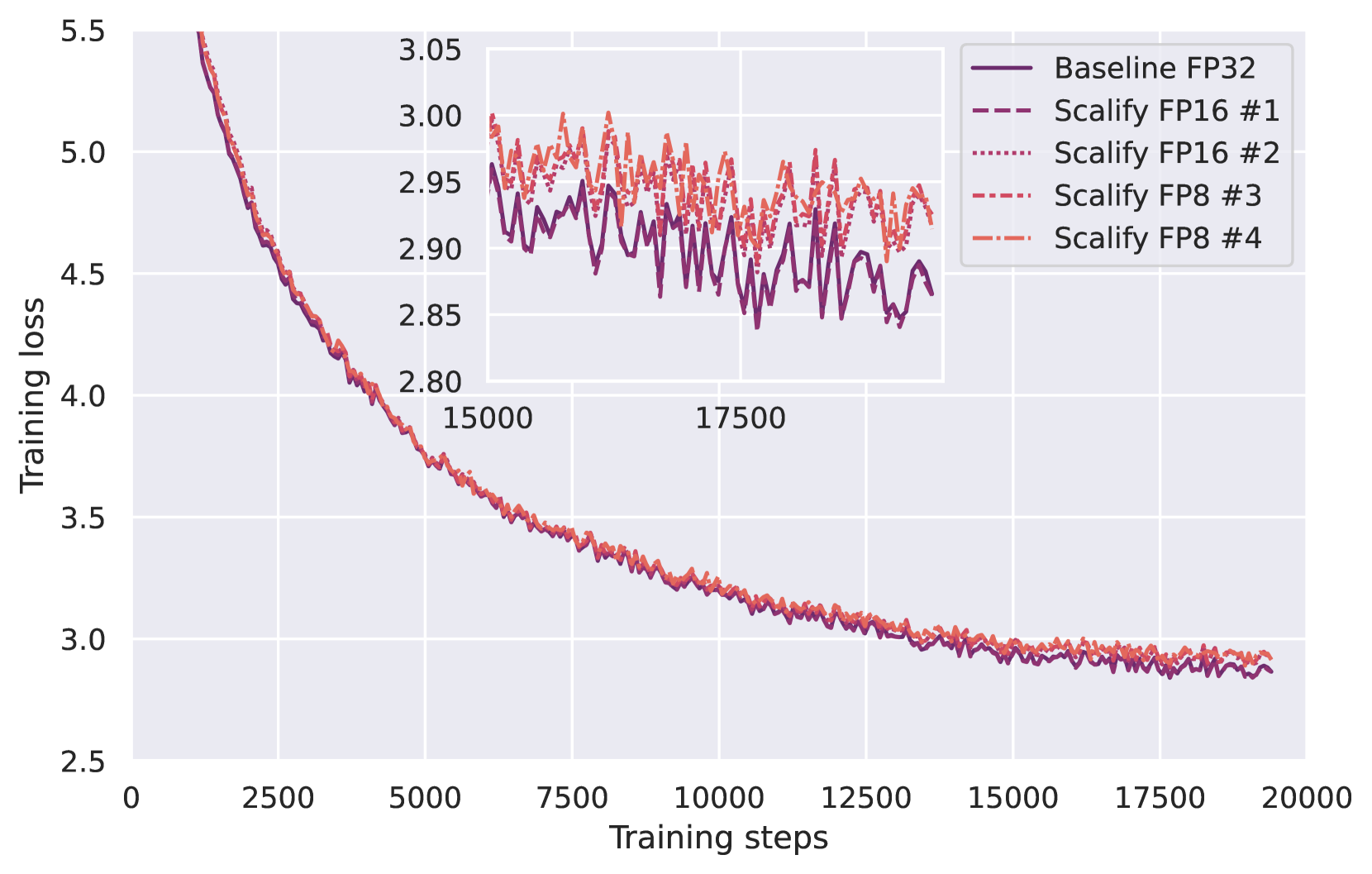
📊 实验亮点
实验结果表明,Scalify能够有效地支持float8矩阵乘法和梯度表示,并且可以与float16优化器状态存储兼容。这意味着Scalify可以在保证模型性能的同时,显著降低计算成本和内存占用。具体的性能数据和对比基线(如使用传统float16训练)的提升幅度需要在论文中查找。
🎯 应用场景
Scalify具有广泛的应用前景,尤其是在资源受限的场景下,例如移动设备和边缘计算。通过使用Scalify,可以在这些平台上高效地训练和部署大型语言模型,从而实现更智能的本地化服务。此外,Scalify还可以应用于其他类型的深度学习模型,例如图像识别和语音识别模型,以提高计算效率和降低功耗。
📄 摘要(原文)
Low-precision formats such as float8 have been introduced in machine learning accelerated hardware to improve computational efficiency for large language models training and inference. Nevertheless, adoption by the ML community has been slowed down by the complex, and sometimes brittle, techniques required to match higher precision training accuracy. In this work, we present Scalify, a end-to-end scale propagation paradigm for computational graphs, generalizing and formalizing existing tensor scaling methods. Experiment results show that Scalify supports out-of-the-box float8 matrix multiplication and gradients representation, as well as float16 optimizer state storage. Our JAX implementation of Scalify is open-sourced at https://github.com/graphcore-research/jax-scalify