Path Following and Stabilisation of a Bicycle Model using a Reinforcement Learning Approach
作者: Sebastian Weyrer, Peter Manzl, A. L. Schwab, Johannes Gerstmayr
分类: cs.LG, cs.RO
发布日期: 2024-07-24
💡 一句话要点
提出基于强化学习的自行车模型路径跟踪与稳定控制方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 自行车模型 路径跟踪 稳定控制 课程学习 多体系统动力学 机器人控制
📋 核心要点
- 传统自行车控制方法复杂,而强化学习为机械系统控制提供了一种易于部署的替代方案。
- 本文利用强化学习,直接输出转向角控制虚拟自行车模型,实现路径跟踪和横向稳定。
- 实验验证了该方法在复杂路径和不同速度下的有效性,并使用可解释机器学习方法分析了智能体的行为。
📝 摘要(中文)
本文提出了一种基于强化学习(RL)的方法,用于实现虚拟自行车模型的路径跟踪,并同时稳定其横向运动。该自行车模型采用Whipple基准模型,并使用多体系统动力学进行建模,没有任何稳定辅助装置。智能体仅通过输出转向角(通过PD控制器转换为转向扭矩)来成功实现路径跟踪和自行车模型的稳定。采用课程学习作为一种先进的训练策略。研究并比较了所实现的RL框架的不同设置。使用不同类型的路径和测量方法评估了部署的智能体的性能。结果表明,部署的智能体能够在2m/s到7m/s的速度范围内,沿着包括完整圆圈、蛇形机动和车道变换等复杂路径进行路径跟踪和自行车模型的稳定。最后,使用机器学习的可解释方法来分析已部署智能体的功能,并将所提出的RL方法与自行车动力学领域的研究联系起来。
🔬 方法详解
问题定义:论文旨在解决自行车模型在无任何辅助稳定装置的情况下,如何仅通过控制转向来实现精确的路径跟踪和横向稳定问题。现有控制方法通常较为复杂,需要精确的动力学模型和复杂的控制策略,难以适应各种复杂环境和速度变化。
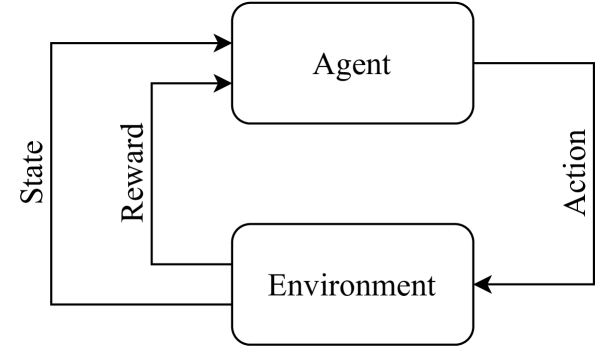
核心思路:论文的核心思路是利用强化学习训练一个智能体,使其能够学习到最优的转向控制策略,从而在不需要精确模型的情况下实现路径跟踪和稳定。通过让智能体与自行车模型在虚拟环境中交互,并根据其行为给予奖励或惩罚,智能体能够逐步学习到如何在不同状态下采取合适的转向动作。
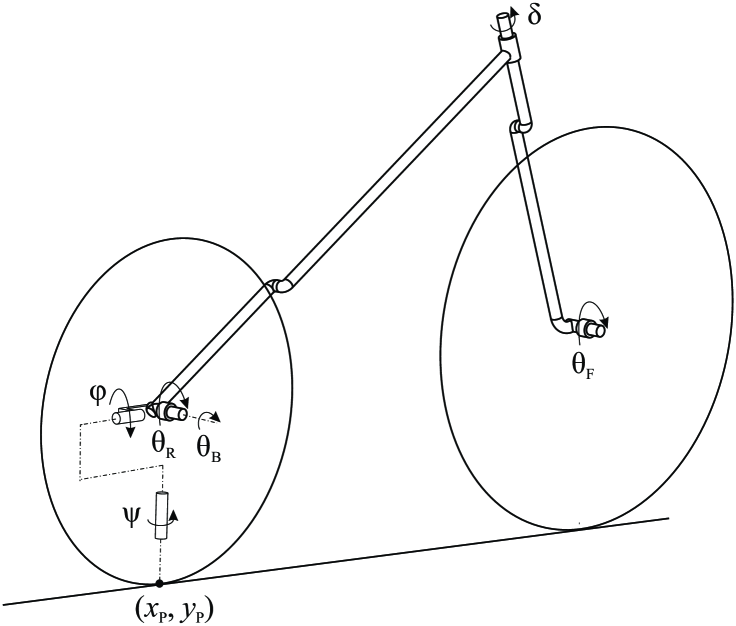
技术框架:整体框架包括以下几个主要模块:1) 自行车模型:使用Whipple基准模型,采用多体系统动力学进行建模。2) 强化学习智能体:采用深度强化学习算法(具体算法未知),负责根据当前状态输出转向角。3) PD控制器:将智能体输出的转向角转换为转向扭矩,作用于自行车模型。4) 训练环境:模拟各种复杂的路径和速度,为智能体提供训练数据。5) 课程学习:逐步增加训练难度,提高智能体的泛化能力。
关键创新:该方法的主要创新在于将强化学习应用于自行车模型的路径跟踪和稳定控制,无需精确的动力学模型,能够适应复杂环境和速度变化。此外,采用课程学习策略,提高了智能体的训练效率和泛化能力。
关键设计:论文中关键的设计细节包括:1) 奖励函数的设计:奖励函数需要能够引导智能体学习到既能精确跟踪路径,又能保持横向稳定的控制策略。2) 状态空间的设计:状态空间需要包含足够的信息,以便智能体能够做出正确的决策,例如自行车的位置、速度、姿态等。3) 动作空间的设计:动作空间为转向角,通过PD控制器转换为转向扭矩。4) 课程学习策略:逐步增加路径的复杂度和速度范围,提高智能体的鲁棒性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法训练的智能体能够在2m/s到7m/s的速度范围内,沿着包括完整圆圈、蛇形机动和车道变换等复杂路径进行有效的路径跟踪和稳定控制。通过可解释机器学习方法分析,揭示了智能体的控制策略与自行车动力学之间的联系,验证了该方法的有效性和合理性。具体性能数据(如跟踪误差、稳定时间等)未知。
🎯 应用场景
该研究成果可应用于自动驾驶自行车、机器人导航、虚拟现实等领域。例如,可以开发能够自动行驶的自行车,提高骑行的安全性与便捷性。在机器人导航领域,该方法可以用于控制轮式机器人在复杂环境中进行路径跟踪。此外,该方法还可以应用于虚拟现实游戏中,提高自行车的操控体验。
📄 摘要(原文)
Over the years, complex control approaches have been developed to control the motion of a bicycle. Reinforcement Learning (RL), a branch of machine learning, promises easy deployment of so-called agents. Deployed agents are increasingly considered as an alternative to controllers for mechanical systems. The present work introduces an RL approach to do path following with a virtual bicycle model while simultaneously stabilising it laterally. The bicycle, modelled as the Whipple benchmark model and using multibody system dynamics, has no stabilisation aids. The agent succeeds in both path following and stabilisation of the bicycle model exclusively by outputting steering angles, which are converted into steering torques via a PD controller. Curriculum learning is applied as a state-of-the-art training strategy. Different settings for the implemented RL framework are investigated and compared to each other. The performance of the deployed agents is evaluated using different types of paths and measurements. The ability of the deployed agents to do path following and stabilisation of the bicycle model travelling between 2m/s and 7m/s along complex paths including full circles, slalom manoeuvres, and lane changes is demonstrated. Explanatory methods for machine learning are used to analyse the functionality of a deployed agent and link the introduced RL approach with research in the field of bicycle dynamics.