In Search for Architectures and Loss Functions in Multi-Objective Reinforcement Learning
作者: Mikhail Terekhov, Caglar Gulcehre
分类: cs.LG, cs.AI
发布日期: 2024-07-23
备注: 20 pages, 10 figures, 3 tables
💡 一句话要点
提出MOPPO算法,通过架构探索和损失函数设计提升多目标强化学习性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多目标强化学习 近端策略优化 策略梯度 帕累托前沿 深度学习 函数逼近 消融研究
📋 核心要点
- 现有MORL方法在深度学习函数逼近器下学习动态不稳定,难以有效权衡多个目标。
- 提出MOPPO算法,扩展PPO到多目标场景,并设计MOA2C作为消融研究的基线。
- 实验表明MOPPO能有效捕获帕累托前沿,且消融研究揭示了架构选择的重要性。
📝 摘要(中文)
多目标强化学习(MORL)对于解决现实世界中需要在多个效用函数之间进行权衡的复杂强化学习问题至关重要。然而,由于基于深度学习的函数逼近器带来的不稳定学习动态,MORL面临着挑战。目前的研究主要集中于探索不同的基于价值的MORL损失函数来克服这个问题。本文实证地探索了无模型的策略学习损失函数以及不同架构选择的影响。我们提出了两种不同的方法:多目标近端策略优化(MOPPO),它将PPO扩展到MORL,以及多目标优势Actor-Critic (MOA2C),它作为我们消融研究中的一个简单基线。我们提出的方法易于实现,只需要在函数逼近器层面进行小的修改。我们在MORL Deep Sea Treasure、Minecart和Reacher环境中进行了全面的评估,结果表明MOPPO有效地捕获了帕累托前沿。我们广泛的消融研究和实证分析揭示了不同架构选择的影响,强调了MOPPO在MORL指标(包括超体积和期望效用)方面,相比于流行的MORL方法(如Pareto Conditioned Networks (PCN)和Envelope Q-learning)的鲁棒性和通用性。
🔬 方法详解
问题定义:多目标强化学习旨在寻找在多个目标函数之间进行权衡的策略。现有方法,特别是基于深度学习的MORL方法,面临着学习动态不稳定的问题,导致难以有效地找到帕累托最优策略。现有的研究主要集中在设计不同的基于价值的损失函数,而忽略了策略学习损失函数和架构选择的影响。
核心思路:本文的核心思路是将单目标强化学习中表现良好的近端策略优化(PPO)算法扩展到多目标场景。通过直接优化策略,并结合多目标优化的思想,MOPPO旨在更稳定地学习帕累托前沿。同时,通过消融研究,探索不同的网络架构对MORL性能的影响。
技术框架:MOPPO算法基于Actor-Critic框架。Actor网络负责生成策略,Critic网络负责评估策略的价值。算法流程如下:1. 使用Actor网络生成一组轨迹。2. 使用Critic网络评估这些轨迹的价值,并计算优势函数。3. 使用PPO的策略更新规则,更新Actor网络,使其生成的策略能够更好地权衡多个目标。4. 使用多目标优化的方法,例如标量化,来指导策略的更新方向。MOA2C算法作为基线,采用类似的Actor-Critic框架,但使用A2C的更新规则。
关键创新:本文的关键创新在于将PPO算法成功扩展到多目标强化学习领域。与现有的MORL方法相比,MOPPO直接优化策略,避免了基于价值的方法可能存在的偏差和不稳定性。此外,本文还通过消融研究,系统地分析了不同网络架构对MORL性能的影响,为未来的MORL研究提供了有价值的指导。
关键设计:MOPPO的关键设计包括:1. 使用标量化方法将多个目标函数组合成一个标量目标函数,用于指导策略的更新方向。标量化的权重可以根据不同的需求进行调整,从而控制策略在不同目标之间的权衡。2. 使用PPO的裁剪技巧,限制策略的更新幅度,从而保证学习的稳定性。3. Actor和Critic网络可以使用不同的架构,例如多层感知机或循环神经网络。消融研究表明,合适的网络架构可以显著提高MORL的性能。
🖼️ 关键图片


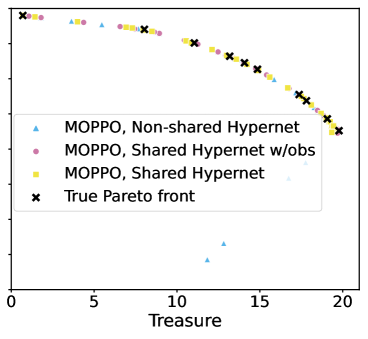
📊 实验亮点
实验结果表明,MOPPO算法在MORL Deep Sea Treasure、Minecart和Reacher等多个环境中均能有效地捕获帕累托前沿,并且在超体积和期望效用等指标上优于PCN和Envelope Q-learning等流行的MORL方法。消融研究还揭示了网络架构对MORL性能的重要影响,为未来的研究提供了指导。
🎯 应用场景
该研究成果可应用于机器人控制、资源分配、自动驾驶等需要同时优化多个目标的实际问题。例如,在机器人控制中,可以同时优化机器人的速度、能耗和稳定性。在自动驾驶中,可以同时优化车辆的安全性、舒适性和效率。该研究为解决复杂现实世界的强化学习问题提供了新的思路和方法。
📄 摘要(原文)
Multi-objective reinforcement learning (MORL) is essential for addressing the intricacies of real-world RL problems, which often require trade-offs between multiple utility functions. However, MORL is challenging due to unstable learning dynamics with deep learning-based function approximators. The research path most taken has been to explore different value-based loss functions for MORL to overcome this issue. Our work empirically explores model-free policy learning loss functions and the impact of different architectural choices. We introduce two different approaches: Multi-objective Proximal Policy Optimization (MOPPO), which extends PPO to MORL, and Multi-objective Advantage Actor Critic (MOA2C), which acts as a simple baseline in our ablations. Our proposed approach is straightforward to implement, requiring only small modifications at the level of function approximator. We conduct comprehensive evaluations on the MORL Deep Sea Treasure, Minecart, and Reacher environments and show that MOPPO effectively captures the Pareto front. Our extensive ablation studies and empirical analyses reveal the impact of different architectural choices, underscoring the robustness and versatility of MOPPO compared to popular MORL approaches like Pareto Conditioned Networks (PCN) and Envelope Q-learning in terms of MORL metrics, including hypervolume and expected utility.