Diffusion Models as Optimizers for Efficient Planning in Offline RL
作者: Renming Huang, Yunqiang Pei, Guoqing Wang, Yangming Zhang, Yang Yang, Peng Wang, Hengtao Shen
分类: cs.LG, cs.AI, cs.CV, cs.RO
发布日期: 2024-07-23
备注: The paper was accepted by ECCV2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出Trajectory Diffuser,解耦轨迹生成与优化,加速离线强化学习规划。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 扩散模型 轨迹生成 轨迹优化 序列建模
📋 核心要点
- 现有离线强化学习方法,特别是基于扩散模型的序列生成方法,推理速度慢,限制了其在实际场景中的应用。
- 论文提出Trajectory Diffuser,将扩散模型的采样过程解耦为轨迹生成和轨迹优化两个子过程,分别处理以提升效率。
- 实验结果表明,Trajectory Diffuser在D4RL基准测试中,推理速度提升3-10倍,同时保持甚至超越了现有方法的性能。
📝 摘要(中文)
扩散模型在离线强化学习任务中表现出强大的竞争力,它将决策制定建模为序列生成。然而,这些方法的实用性受到其漫长推理过程的限制。本文通过将扩散模型的采样过程分解为两个解耦的子过程来解决这个问题:1)生成可行的轨迹(耗时过程),2)优化轨迹。通过这种分解方法,我们能够部分地分离效率和质量因素,从而同时获得效率优势并确保质量保证。我们提出了轨迹扩散器(Trajectory Diffuser),它利用更快的自回归模型来处理可行轨迹的生成,同时保留扩散模型的轨迹优化过程。这使我们能够在不牺牲能力的情况下实现更有效的规划。为了评估轨迹扩散器的有效性和效率,我们在D4RL基准上进行了实验。结果表明,与之前的序列建模方法相比,我们的方法实现了3-10倍的更快推理速度,并且在整体性能方面也优于它们。
🔬 方法详解
问题定义:离线强化学习旨在利用预先收集好的数据集来学习策略,而无需与环境进行交互。基于扩散模型的离线强化学习方法将决策过程建模为序列生成,但其采样过程计算量大,导致推理速度慢,难以应用于实际场景。现有方法难以在效率和性能之间取得平衡。
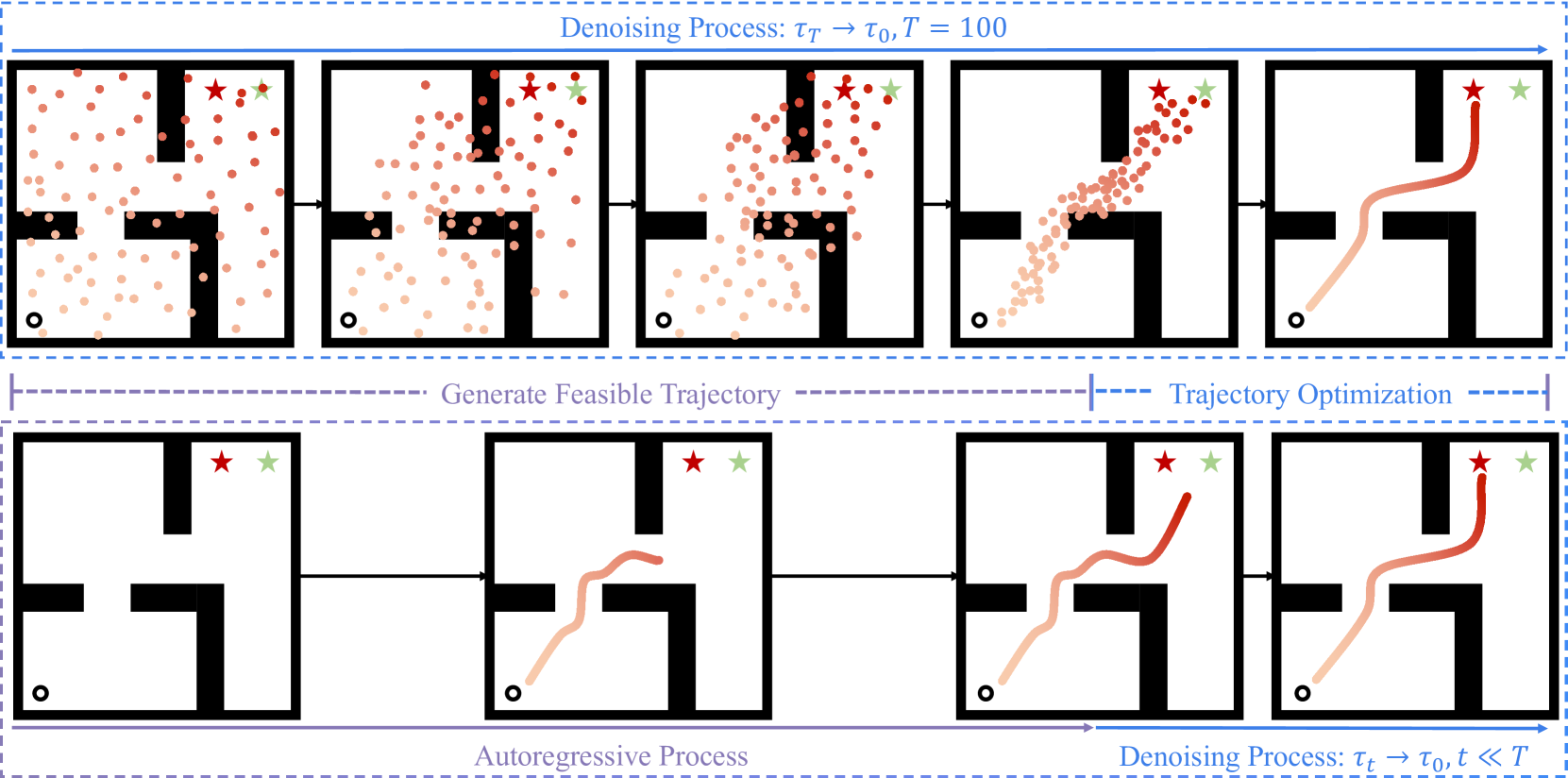
核心思路:论文的核心思路是将扩散模型的采样过程解耦为两个独立的子过程:轨迹生成和轨迹优化。轨迹生成负责快速生成一个可行的轨迹,而轨迹优化则利用扩散模型对该轨迹进行优化,以提高其性能。通过这种解耦,可以使用更高效的模型(如自回归模型)进行轨迹生成,从而显著提高推理速度。
技术框架:Trajectory Diffuser包含两个主要模块:轨迹生成器和轨迹优化器。轨迹生成器使用自回归模型(例如Transformer)来预测轨迹中的下一个状态和动作,从而快速生成一个可行的轨迹。轨迹优化器则使用扩散模型,通过迭代地添加和去除噪声来优化轨迹,使其更符合离线数据集中的最优行为。整体流程是:首先,轨迹生成器生成初始轨迹;然后,轨迹优化器对该轨迹进行优化;最后,输出优化后的轨迹。
关键创新:最重要的技术创新点在于将扩散模型的采样过程解耦为轨迹生成和轨迹优化两个子过程。与现有方法相比,Trajectory Diffuser能够更有效地利用计算资源,从而在保证性能的同时显著提高推理速度。本质区别在于,现有方法通常将轨迹生成和优化耦合在一起,而Trajectory Diffuser则将它们分离,从而可以使用不同的模型和技术来分别处理这两个子过程。
关键设计:轨迹生成器可以使用Transformer等自回归模型,损失函数为标准的序列预测损失。轨迹优化器使用扩散模型,损失函数为标准的扩散模型损失,例如均方误差。关键参数包括扩散模型的噪声时间步数、噪声水平以及自回归模型的层数和隐藏单元数。具体网络结构的选择可以根据具体任务进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Trajectory Diffuser在D4RL基准测试中,与之前的序列建模方法相比,实现了3-10倍的更快推理速度,并且在整体性能方面也优于它们。例如,在部分D4RL任务上,Trajectory Diffuser的性能超过了Behavior Cloning和Decision Transformer等基线方法。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、游戏AI等领域。通过提高离线强化学习的推理效率,可以使智能体更快地适应新环境,并做出更优的决策。此外,该方法还可以用于生成高质量的运动轨迹,例如在动画制作和虚拟现实中。
📄 摘要(原文)
Diffusion models have shown strong competitiveness in offline reinforcement learning tasks by formulating decision-making as sequential generation. However, the practicality of these methods is limited due to the lengthy inference processes they require. In this paper, we address this problem by decomposing the sampling process of diffusion models into two decoupled subprocesses: 1) generating a feasible trajectory, which is a time-consuming process, and 2) optimizing the trajectory. With this decomposition approach, we are able to partially separate efficiency and quality factors, enabling us to simultaneously gain efficiency advantages and ensure quality assurance. We propose the Trajectory Diffuser, which utilizes a faster autoregressive model to handle the generation of feasible trajectories while retaining the trajectory optimization process of diffusion models. This allows us to achieve more efficient planning without sacrificing capability. To evaluate the effectiveness and efficiency of the Trajectory Diffuser, we conduct experiments on the D4RL benchmarks. The results demonstrate that our method achieves $\it 3$-$\it 10 \times$ faster inference speed compared to previous sequence modeling methods, while also outperforming them in terms of overall performance. https://github.com/RenMing-Huang/TrajectoryDiffuser Keywords: Reinforcement Learning and Efficient Planning and Diffusion Model