FMamba: Mamba based on Fast-attention for Multivariate Time-series Forecasting
作者: Shusen Ma, Yu Kang, Peng Bai, Yun-Bo Zhao
分类: cs.LG
发布日期: 2024-07-20
💡 一句话要点
FMamba:结合快速注意力机制的Mamba模型用于多元时间序列预测
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多元时间序列预测 Mamba模型 快速注意力机制 状态空间模型 时间依赖性 变量间关系 深度学习
📋 核心要点
- Transformer模型在多元时间序列预测中表现出色,但其计算复杂度高,效率较低。
- FMamba结合快速注意力机制和Mamba模型,旨在提取变量间关系和时间依赖性,提升预测性能。
- 实验结果表明,FMamba在多个数据集上实现了最先进的性能,并保持了较低的计算开销。
📝 摘要(中文)
在多元时间序列预测(MTSF)中,提取输入序列的时间相关性至关重要。虽然流行的基于Transformer的预测模型表现良好,但其二次计算复杂度导致效率低下和高开销。最近出现的选择性状态空间模型Mamba,由于其强大的时间特征提取能力和线性计算复杂度,在许多领域显示出前景。然而,由于Mamba的单向性,基于Mamba的通道独立预测模型无法像基于Transformer的模型那样关注所有变量之间的关系。为了解决这个问题,我们将快速注意力机制与Mamba相结合,引入了一个名为FMamba的MTSF新框架。在技术上,我们首先通过嵌入层提取输入变量的时间特征,然后通过快速注意力模块计算输入变量之间的依赖关系。随后,我们使用Mamba选择性地处理输入特征,并通过多层感知器块(MLP-block)进一步提取变量的时间依赖性。最后,FMamba通过投影层(一个线性层)获得预测结果。在八个公共数据集上的实验结果表明,FMamba可以在保持低计算开销的同时实现最先进的性能。
🔬 方法详解
问题定义:多元时间序列预测旨在根据多个变量的历史数据预测未来值。现有基于Transformer的方法虽然有效,但计算复杂度是输入序列长度的平方级别,导致处理长序列时效率低下。Mamba模型虽然具有线性复杂度,但其单向性使其难以捕捉不同变量之间的依赖关系。
核心思路:FMamba的核心思路是将快速注意力机制与Mamba模型相结合。快速注意力机制用于捕捉不同变量之间的依赖关系,而Mamba模型则用于提取时间序列中的时间依赖关系。通过这种结合,FMamba既能保持较低的计算复杂度,又能有效地捕捉多元时间序列中的复杂关系。
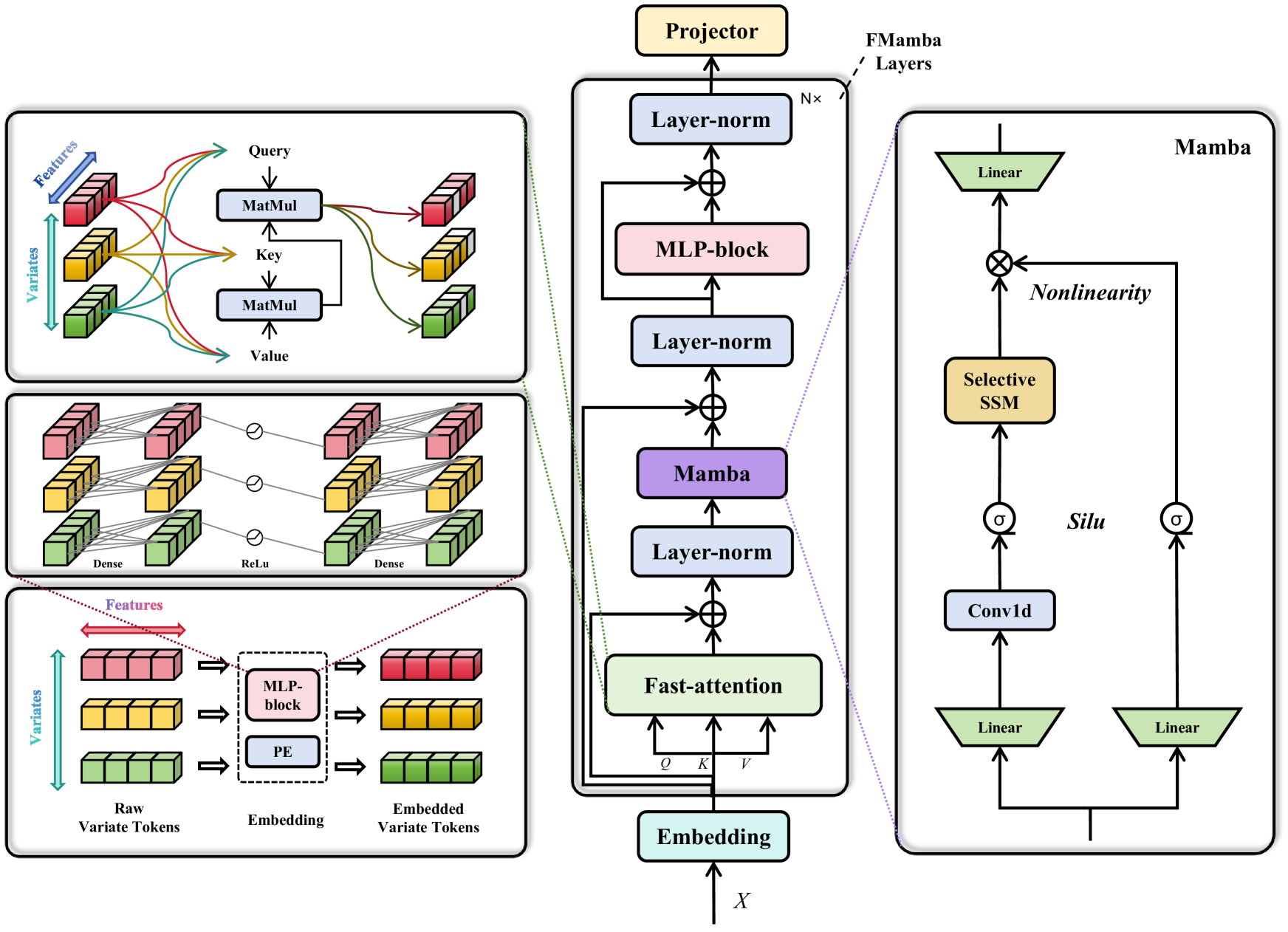
技术框架:FMamba的整体架构包括以下几个主要模块:1) 嵌入层:用于提取输入变量的时间特征。2) 快速注意力模块:用于计算输入变量之间的依赖关系。3) Mamba模块:用于选择性地处理输入特征,并提取时间依赖性。4) MLP-block:进一步提取变量的时间依赖性。5) 投影层:用于将提取的特征映射到预测结果。
关键创新:FMamba的关键创新在于将快速注意力机制与Mamba模型相结合,从而在保持低计算复杂度的同时,有效地捕捉多元时间序列中的变量间依赖关系和时间依赖关系。与传统的基于Transformer的模型相比,FMamba具有更高的效率。与单独使用Mamba的模型相比,FMamba能够更好地捕捉变量间的关系。
关键设计:快速注意力模块的具体实现方式未知,但可以推测其目标是降低注意力计算的复杂度。Mamba模块的具体参数设置未知,但其核心是选择性状态空间模型。MLP-block的具体结构未知,但其作用是进一步提取时间依赖性。损失函数和优化器的选择未知,但通常会选择均方误差或类似的损失函数,并使用Adam等优化器进行训练。
🖼️ 关键图片


📊 实验亮点
FMamba在八个公共数据集上进行了评估,实验结果表明,FMamba在保持低计算开销的同时,实现了最先进的性能。具体的性能提升幅度未知,但摘要中明确指出其达到了state-of-the-art的水平。这意味着FMamba在这些数据集上的表现优于现有的其他模型。
🎯 应用场景
FMamba可应用于各种多元时间序列预测场景,例如金融市场预测、交通流量预测、能源需求预测、天气预报和供应链管理等。该模型能够高效地处理大规模时间序列数据,并提供准确的预测结果,从而帮助决策者做出更明智的决策,提高运营效率,降低风险。
📄 摘要(原文)
In multivariate time-series forecasting (MTSF), extracting the temporal correlations of the input sequences is crucial. While popular Transformer-based predictive models can perform well, their quadratic computational complexity results in inefficiency and high overhead. The recently emerged Mamba, a selective state space model, has shown promising results in many fields due to its strong temporal feature extraction capabilities and linear computational complexity. However, due to the unilateral nature of Mamba, channel-independent predictive models based on Mamba cannot attend to the relationships among all variables in the manner of Transformer-based models. To address this issue, we combine fast-attention with Mamba to introduce a novel framework named FMamba for MTSF. Technically, we first extract the temporal features of the input variables through an embedding layer, then compute the dependencies among input variables via the fast-attention module. Subsequently, we use Mamba to selectively deal with the input features and further extract the temporal dependencies of the variables through the multi-layer perceptron block (MLP-block). Finally, FMamba obtains the predictive results through the projector, a linear layer. Experimental results on eight public datasets demonstrate that FMamba can achieve state-of-the-art performance while maintaining low computational overhead.