Enhancing Graph Neural Networks with Limited Labeled Data by Actively Distilling Knowledge from Large Language Models
作者: Quan Li, Tianxiang Zhao, Lingwei Chen, Junjie Xu, Suhang Wang
分类: cs.LG, cs.AI
发布日期: 2024-07-19 (更新: 2024-09-04)
备注: 10 pages, 3 Figures
💡 一句话要点
提出基于图神经网络和主动蒸馏的知识增强方法,解决少样本节点分类问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图神经网络 大型语言模型 主动学习 知识蒸馏 少样本学习 节点分类 零样本学习
📋 核心要点
- 传统GNN在少样本节点分类任务中面临挑战,现有方法如元学习和迁移学习存在对先验知识的依赖或未充分利用未标记节点的问题。
- 该论文提出了一种结合LLM和GNN的新方法,利用LLM的零样本推理能力,并通过图-LLM的主动学习范式来提升GNN的性能。
- 实验结果表明,该模型在标记数据极少的情况下,显著提升了节点分类的准确率,优于现有最佳方法。
📝 摘要(中文)
本文提出了一种新颖的方法,该方法集成了大型语言模型(LLM)和图神经网络(GNN),利用LLM的零样本推理能力,并采用基于图-LLM的主动学习范式来增强GNN的性能。传统GNN在标记节点稀少的情况下表现不佳,而本文方法旨在解决这一挑战。传统元学习和迁移学习方法通常需要来自基类的先验知识,或者未能充分利用未标记节点的潜力。基于LLM的方法可能忽略LLM的零样本能力,并且过度依赖于生成的上下文质量。大量实验表明,该模型在极有限的标记数据下,显著提高了节点分类的准确性,超越了最先进的基线。
🔬 方法详解
问题定义:论文旨在解决图神经网络在节点分类任务中,当标记节点数量极少时性能显著下降的问题。现有的方法,如传统的元学习和迁移学习,往往需要大量的先验知识或者无法有效利用未标记节点的信息。而直接使用大型语言模型的方法又容易受到生成上下文质量的影响,并且可能忽略了LLM本身强大的零样本学习能力。
核心思路:论文的核心思路是结合大型语言模型(LLM)的零样本推理能力和图神经网络(GNN)的图结构学习能力,通过主动学习的方式,让LLM指导GNN的学习过程,从而在少量标记数据的情况下,提升GNN的节点分类性能。这样设计的目的是为了充分利用LLM的知识和推理能力,同时克服GNN在少样本情况下的局限性。
技术框架:整体框架包含以下几个主要模块:1) LLM上下文生成模块:利用节点信息生成LLM可以理解的上下文描述。2) LLM零样本推理模块:利用LLM对未标记节点进行初步的类别预测。3) 主动学习模块:根据LLM的预测结果,选择信息量最大的节点进行标记。4) GNN训练模块:利用少量标记数据和图结构信息训练GNN。5) 知识蒸馏模块:利用LLM的预测结果作为软标签,对GNN进行知识蒸馏,进一步提升GNN的性能。
关键创新:该方法最关键的创新在于将LLM的零样本推理能力与GNN的图结构学习能力相结合,并引入了主动学习范式。与现有方法相比,该方法不需要大量的先验知识,能够有效利用未标记节点的信息,并且能够克服LLM对上下文质量的依赖。通过主动学习,能够选择最有价值的节点进行标记,从而在少量标记数据的情况下,最大化GNN的性能提升。
关键设计:在LLM上下文生成模块中,需要设计合适的提示词模板,将节点信息转化为LLM可以理解的自然语言描述。在主动学习模块中,需要选择合适的采样策略,例如基于不确定性的采样或基于多样性的采样。在知识蒸馏模块中,需要选择合适的损失函数,例如交叉熵损失或KL散度损失。GNN的网络结构可以选择常用的GCN、GAT等。
🖼️ 关键图片
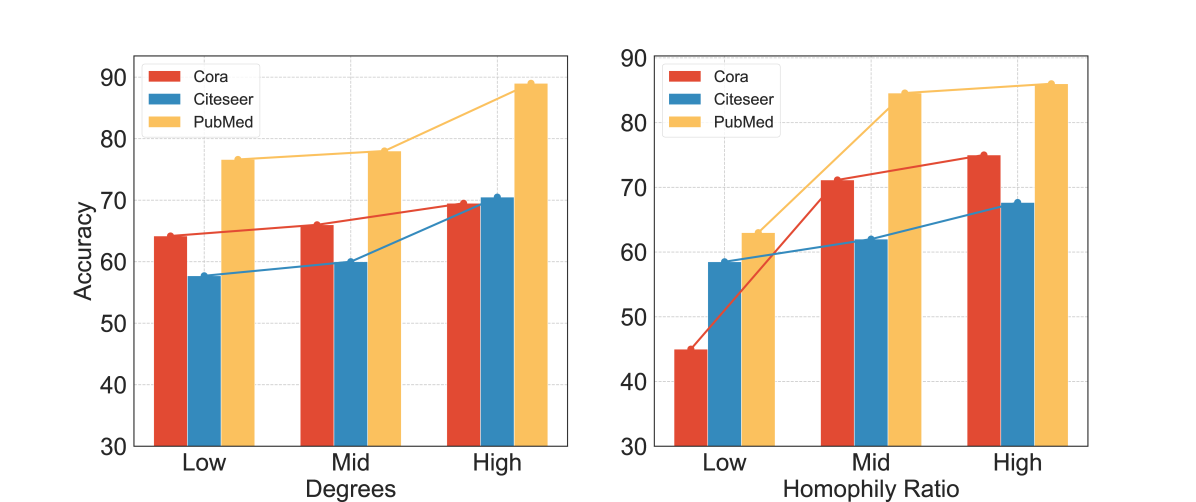


📊 实验亮点
实验结果表明,该方法在节点分类任务中,使用极少量标记数据的情况下,显著超越了现有的最先进基线方法。具体的性能提升幅度取决于数据集和实验设置,但总体而言,该方法能够将节点分类的准确率提升显著的百分比,证明了其在少样本学习场景下的有效性。实验还验证了主动学习和知识蒸馏模块的有效性,证明了它们对整体性能提升的贡献。
🎯 应用场景
该研究成果可广泛应用于社交网络分析、生物信息学、知识图谱等领域,尤其是在节点标记成本高昂或难以获取的情况下,具有重要的实际应用价值。例如,在社交网络中识别恶意用户,在生物信息学中预测蛋白质功能,在知识图谱中补全实体关系等。该方法能够有效降低人工标注成本,提高节点分类的准确性和效率,具有广阔的应用前景。
📄 摘要(原文)
Graphs are pervasive in the real-world, such as social network analysis, bioinformatics, and knowledge graphs. Graph neural networks (GNNs) have great ability in node classification, a fundamental task on graphs. Unfortunately, conventional GNNs still face challenges in scenarios with few labeled nodes, despite the prevalence of few-shot node classification tasks in real-world applications. To address this challenge, various approaches have been proposed, including graph meta-learning, transfer learning, and methods based on Large Language Models (LLMs). However, traditional meta-learning and transfer learning methods often require prior knowledge from base classes or fail to exploit the potential advantages of unlabeled nodes. Meanwhile, LLM-based methods may overlook the zero-shot capabilities of LLMs and rely heavily on the quality of generated contexts. In this paper, we propose a novel approach that integrates LLMs and GNNs, leveraging the zero-shot inference and reasoning capabilities of LLMs and employing a Graph-LLM-based active learning paradigm to enhance GNNs' performance. Extensive experiments demonstrate the effectiveness of our model in improving node classification accuracy with considerably limited labeled data, surpassing state-of-the-art baselines by significant margins.