Reconstruct the Pruned Model without Any Retraining
作者: Pingjie Wang, Ziqing Fan, Shengchao Hu, Zhe Chen, Yanfeng Wang, Yu Wang
分类: cs.LG
发布日期: 2024-07-18
备注: 18 pages
💡 一句话要点
提出LIAR框架以无须重训练重构剪枝模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 结构化剪枝 模型重构 线性插值 深度学习 语言模型
📋 核心要点
- 现有的剪枝方法往往强调剪枝标准,而重构技术缺乏通用性,导致性能恢复效果有限。
- 本文提出的LIAR框架通过线性插值对保留权重进行自适应重构,无需重训练,兼容多种剪枝标准。
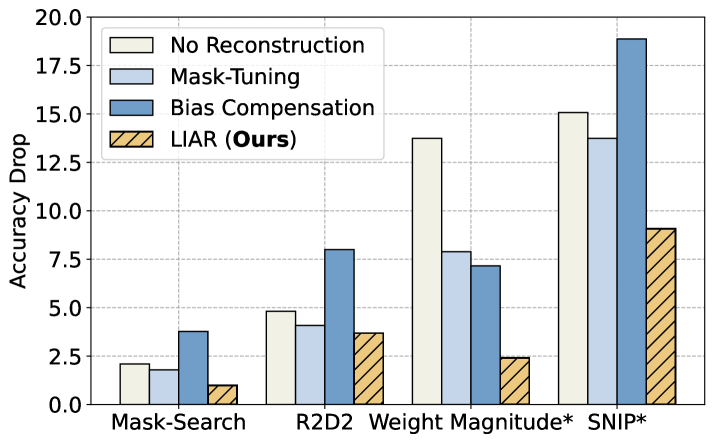
- 实验结果显示,LIAR使BERT模型在去除50%参数后仍保持98%准确率,并在短时间内提升LLaMA性能。
📝 摘要(中文)
结构化剪枝是一种有前景的硬件友好型压缩技术,旨在降低大型语言模型的计算成本。现有方法往往侧重于剪枝标准,而重构技术则局限于特定模块,缺乏通用性。为此,本文提出了基于线性插值的自适应重构框架(LIAR),该框架高效且有效,无需反向传播或重训练,兼容多种剪枝标准。通过对保留权重应用线性插值,LIAR最小化重构误差,有效重构剪枝后的输出。实验结果表明,LIAR使BERT模型在去除50%参数后仍能保持98%的准确率,并在几分钟内实现LLaMA的最佳性能。
🔬 方法详解
问题定义:本文旨在解决现有结构化剪枝方法在重构性能方面的不足,现有方法往往依赖于特定模块的重构技术,缺乏普适性和效率。
核心思路:LIAR框架通过线性插值对保留的权重进行自适应重构,避免了重训练的高昂成本,同时兼容多种剪枝标准,提升了重构的灵活性和有效性。
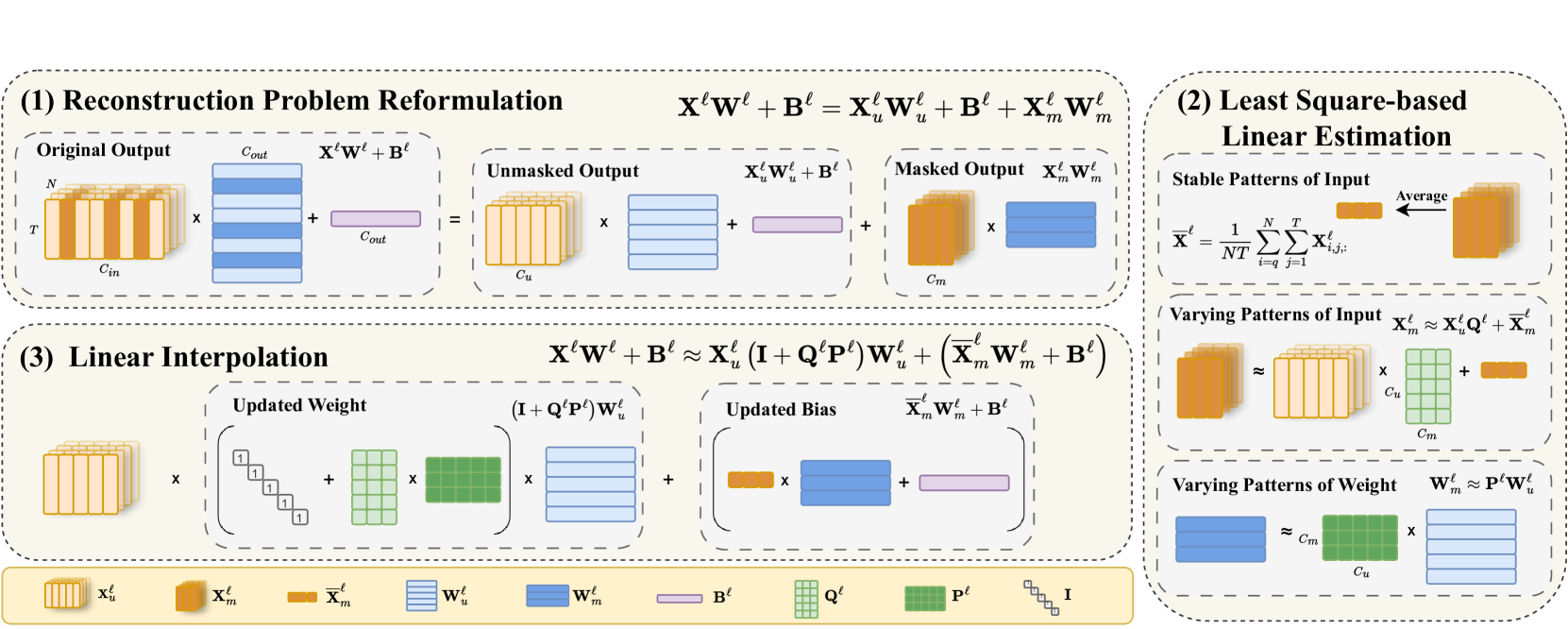
技术框架:LIAR框架主要包括两个阶段:首先根据剪枝标准进行模型剪枝,其次应用线性插值技术对剪枝后的模型进行重构,以最小化重构误差。
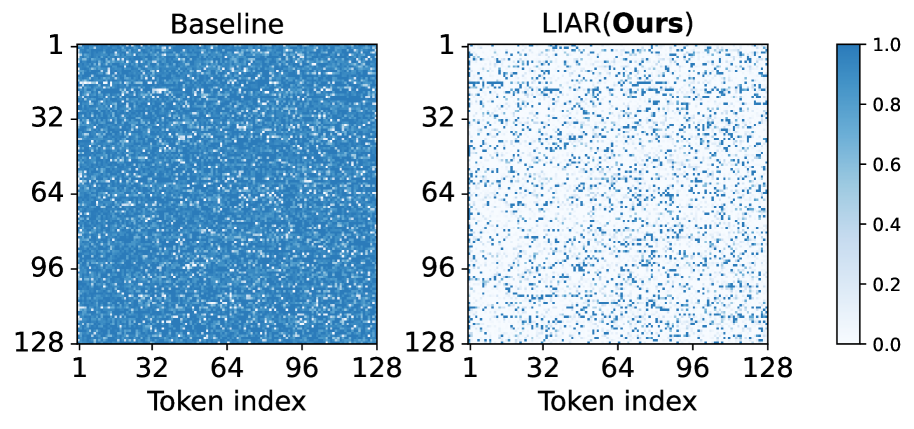
关键创新:LIAR的核心创新在于其自适应重构机制,能够在不依赖于特定模块的情况下,广泛适用于不同的剪枝标准,显著提升了重构的效果和效率。
关键设计:LIAR框架中,线性插值的具体实现细节包括对保留权重的选择和插值参数的设定,确保在重构过程中尽可能保留原模型的性能特征。通过这些设计,LIAR能够有效减少重构误差。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LIAR框架使BERT模型在去除50%参数后仍能保持98%的准确率,显示出其在模型压缩中的有效性。此外,LIAR在几分钟内实现了LLaMA模型的最佳性能,展现了其高效的重构能力。
🎯 应用场景
该研究的潜在应用领域包括大型语言模型的压缩与优化,尤其是在资源受限的环境中,如移动设备和边缘计算。LIAR框架的高效性和无重训练特性使其在实际应用中具有重要价值,能够帮助开发者在保持模型性能的同时,降低计算资源的消耗。未来,LIAR有望在更多深度学习模型的剪枝与重构中得到广泛应用。
📄 摘要(原文)
Structured pruning is a promising hardware-friendly compression technique for large language models (LLMs), which is expected to be retraining-free to avoid the enormous retraining cost. This retraining-free paradigm involves (1) pruning criteria to define the architecture and (2) distortion reconstruction to restore performance. However, existing methods often emphasize pruning criteria while using reconstruction techniques that are specific to certain modules or criteria, resulting in limited generalizability. To address this, we introduce the Linear Interpolation-based Adaptive Reconstruction (LIAR) framework, which is both efficient and effective. LIAR does not require back-propagation or retraining and is compatible with various pruning criteria and modules. By applying linear interpolation to the preserved weights, LIAR minimizes reconstruction error and effectively reconstructs the pruned output. Our evaluations on benchmarks such as GLUE, SQuAD, WikiText, and common sense reasoning show that LIAR enables a BERT model to maintain 98% accuracy even after removing 50% of its parameters and achieves top performance for LLaMA in just a few minutes.