Data-Driven Estimation of Conditional Expectations, Application to Optimal Stopping and Reinforcement Learning
作者: George V. Moustakides
分类: stat.ML, cs.LG
发布日期: 2024-07-18
备注: 20 pages, 6 figures
💡 一句话要点
提出一种纯数据驱动的条件期望估计方法,并应用于最优停止和强化学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 条件期望估计 数据驱动方法 最优停止 强化学习 随机优化 函数逼近 非线性方程组
📋 核心要点
- 现有方法在条件密度未知时难以准确估计条件期望,依赖于对底层分布的假设。
- 论文提出一种直接从数据中学习条件期望的方法,无需预先了解条件密度函数。
- 该方法应用于最优停止和强化学习问题,验证了其在随机优化问题中的有效性。
📝 摘要(中文)
在已知潜在条件密度的情况下,条件期望可以通过解析或数值方法计算。然而,当缺乏这种知识,而只有训练数据时,本研究旨在提出一种简单且纯粹数据驱动的方法,用于直接估计所需的条件期望。由于条件期望出现在许多随机优化问题的描述中,并且相应的最优解满足非线性方程组,因此我们将数据驱动方法扩展到这些情况。我们通过将其应用于最优停止和强化学习中的最优动作策略来测试我们的方法。
🔬 方法详解
问题定义:论文旨在解决在条件密度未知的情况下,如何仅利用训练数据有效估计条件期望的问题。现有方法通常需要假设或估计条件密度,这在实际应用中可能不准确或计算成本高昂。因此,需要一种直接从数据中学习条件期望的方法,避免对底层分布的依赖。
核心思路:论文的核心思路是直接从数据中学习条件期望的估计函数,而无需显式地估计条件密度。通过构建合适的函数逼近器(例如神经网络),并利用训练数据进行训练,可以直接预测给定条件下的期望值。这种方法避免了对条件密度进行建模的复杂性,并且可以适应各种数据分布。
技术框架:该方法主要包含以下几个步骤:1. 收集训练数据,包括条件变量和对应的目标变量。2. 选择合适的函数逼近器,例如神经网络或核方法。3. 定义损失函数,例如均方误差或交叉熵损失,用于衡量估计值与真实值之间的差距。4. 利用训练数据优化函数逼近器的参数,使其能够准确地预测条件期望。5. 将训练好的函数逼近器应用于实际问题,例如最优停止或强化学习。
关键创新:该方法最重要的创新在于其纯数据驱动的特性,它避免了对条件密度的显式建模,从而简化了问题并提高了鲁棒性。与传统的基于模型的方法相比,该方法更加灵活,可以适应各种复杂的数据分布。此外,该方法还能够处理高维数据和非线性关系,使其在实际应用中具有更广泛的适用性。
关键设计:论文中,函数逼近器的选择和损失函数的定义是关键的设计要素。例如,可以使用多层感知机作为函数逼近器,并使用均方误差作为损失函数。此外,还可以采用正则化技术来防止过拟合,并使用优化算法(例如梯度下降)来训练模型。具体的参数设置需要根据实际问题进行调整。
🖼️ 关键图片
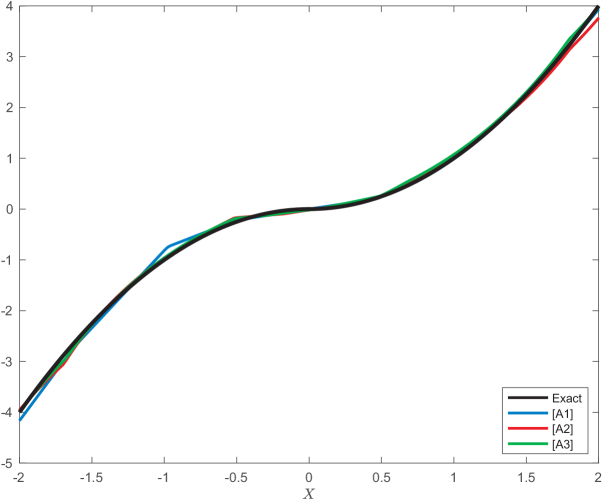


📊 实验亮点
论文通过实验验证了该方法在最优停止和强化学习问题中的有效性。实验结果表明,该方法能够准确地估计条件期望,并获得接近最优的策略。与传统的基于模型的方法相比,该方法在某些情况下能够取得更好的性能,尤其是在条件密度未知或难以估计的情况下。具体的性能提升幅度取决于具体的问题和数据集。
🎯 应用场景
该研究成果可广泛应用于金融工程、风险管理、控制理论和决策优化等领域。例如,在金融领域,可以用于期权定价、投资组合优化和信用风险评估。在控制理论中,可以用于设计最优控制器和状态估计器。在决策优化中,可以用于解决资源分配、调度和路径规划等问题。该方法具有很强的通用性和实用价值,有望在各个领域得到广泛应用。
📄 摘要(原文)
When the underlying conditional density is known, conditional expectations can be computed analytically or numerically. When, however, such knowledge is not available and instead we are given a collection of training data, the goal of this work is to propose simple and purely data-driven means for estimating directly the desired conditional expectation. Because conditional expectations appear in the description of a number of stochastic optimization problems with the corresponding optimal solution satisfying a system of nonlinear equations, we extend our data-driven method to cover such cases as well. We test our methodology by applying it to Optimal Stopping and Optimal Action Policy in Reinforcement Learning.