HHGT: Hierarchical Heterogeneous Graph Transformer for Heterogeneous Graph Representation Learning
作者: Qiuyu Zhu, Liang Zhang, Qianxiong Xu, Kaijun Liu, Cheng Long, Xiaoyang Wang
分类: cs.LG, cs.DB
发布日期: 2024-07-18
💡 一句话要点
提出HHGT:一种用于异构图表示学习的分层异构图Transformer模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 异构图神经网络 图Transformer 异构信息网络 表示学习 分层Transformer
📋 核心要点
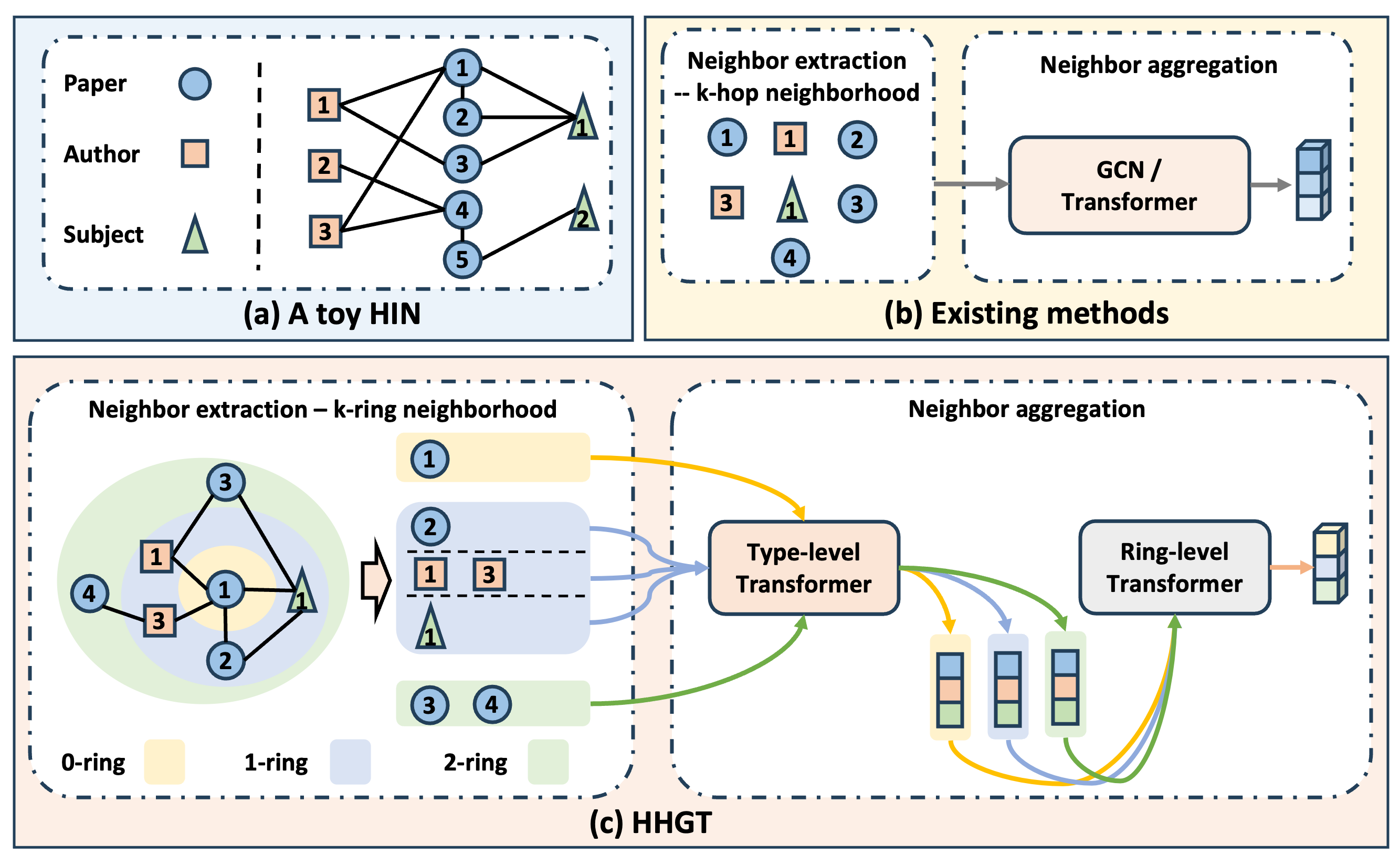
- 现有异构图Transformer方法忽略了不同距离邻居的语义差异,以及不同类型节点间的关联。
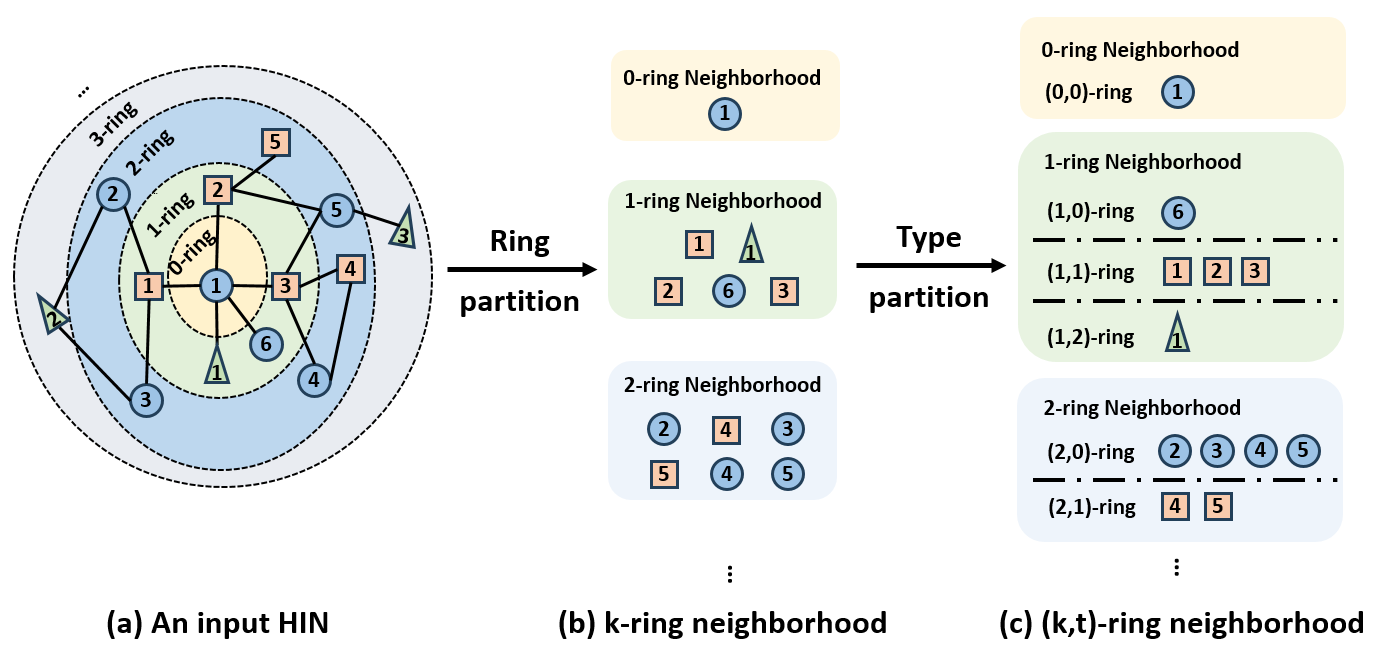
- 论文提出(k,t)-ring邻域结构,区分距离和类型异构性,并设计分层Transformer进行聚合。
- 实验表明,HHGT在节点聚类等任务上显著优于现有方法,NMI和ARI指标提升明显。
📝 摘要(中文)
异构图神经网络(HGNNs)在建模现实世界的异构信息网络(HINs)方面取得了成功,但其表达能力有限和过度平滑等挑战促使研究人员探索图Transformer(GTs)以增强HIN表示学习。然而,HINs中GT的研究仍然有限,现有工作存在两个主要缺点:(1)HINs中不同距离的节点的邻居传达不同的语义。然而,现有方法忽略了这种差异,粗略地统一对待给定距离内的邻居,导致语义混淆。(2)HINs中的节点具有各种类型,每种类型具有独特的语义。然而,现有方法在邻居聚合期间混合了不同类型的节点,阻碍了捕获不同类型节点之间的适当相关性。为了弥合这些差距,我们设计了一种名为(k,t)-ring neighborhood的创新结构,其中节点最初按其距离组织,为每个距离形成不同的非重叠k-ring邻域。在每个k-ring结构中,节点根据其类型进一步分类为不同的组,从而自然地强调了HINs中距离和类型的异构性。基于这种结构,我们提出了一种新颖的分层异构图Transformer(HHGT)模型,该模型无缝集成了类型级Transformer,用于聚合每个k-ring邻域内不同类型的节点,然后是环级Transformer,用于以分层方式聚合不同的k-ring邻域。在下游任务上进行了广泛的实验,以验证HHGT相对于14个基线的优越性,与最佳基线相比,在ACM数据集上的节点聚类任务中,NMI显着提高了24.75%,ARI提高了29.25%。
🔬 方法详解
问题定义:现有异构图Transformer方法在处理异构信息网络时,无法有效区分不同距离邻居的语义信息,并且在聚合过程中混合了不同类型的节点,导致无法充分捕捉节点间的复杂关系。这限制了模型在下游任务中的性能。
核心思路:论文的核心思路是设计一种能够同时考虑节点距离和类型异构性的图Transformer模型。通过引入(k,t)-ring邻域结构,将节点按照距离和类型进行分组,从而在聚合过程中更好地利用异构信息。然后,使用分层Transformer结构,先聚合同一(k,t)-ring内的节点,再聚合不同(k,t)-ring的信息。
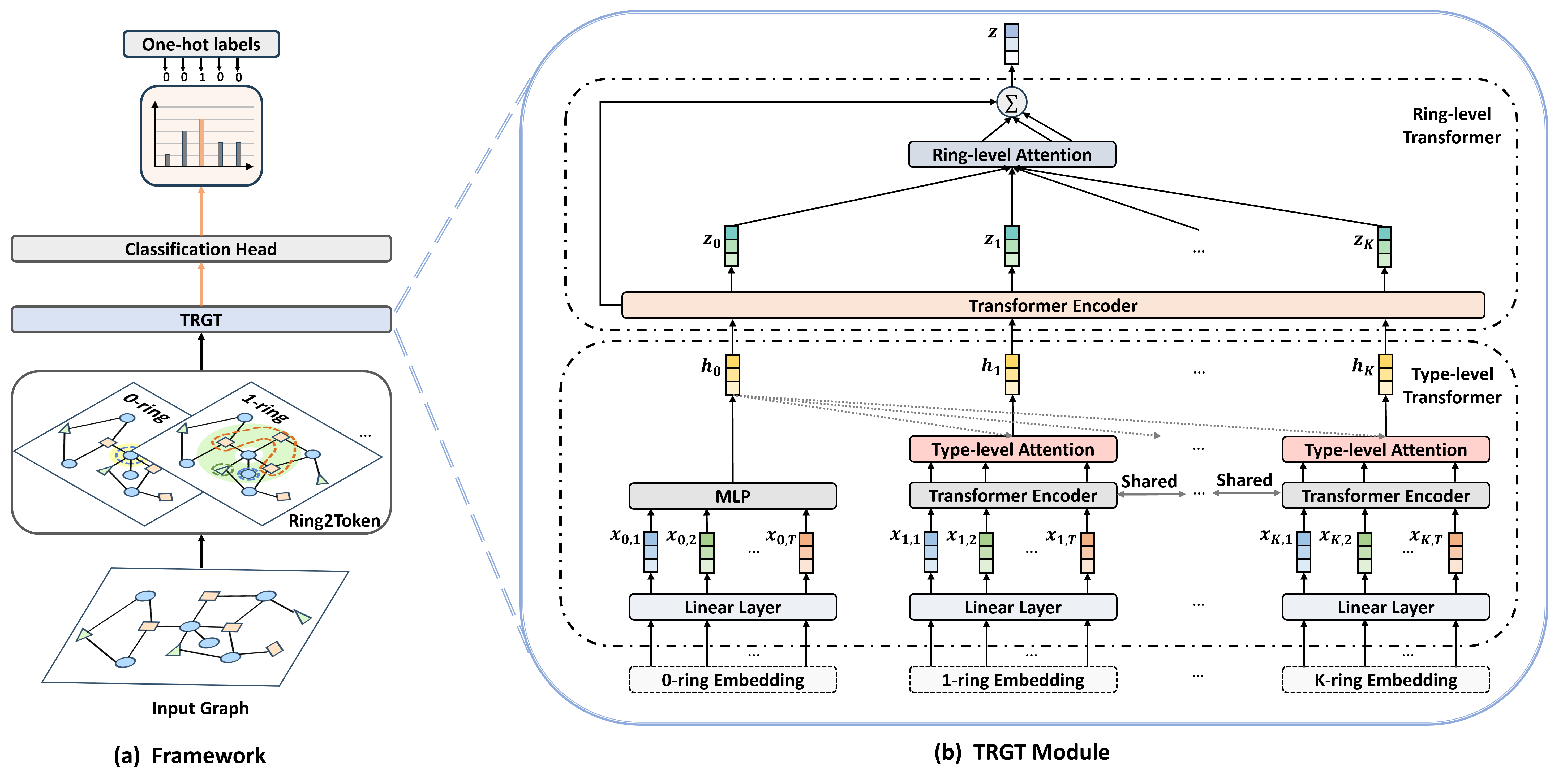
技术框架:HHGT模型主要包含以下几个阶段: 1. (k,t)-ring邻域构建:根据节点之间的距离和类型,构建(k,t)-ring邻域结构。 2. 类型级Transformer:在每个(k,t)-ring内,使用类型级Transformer聚合不同类型节点的信息。 3. 环级Transformer:使用环级Transformer聚合来自不同(k,t)-ring的信息,形成最终的节点表示。 4. 下游任务:将学习到的节点表示应用于下游任务,如节点分类或聚类。
关键创新:论文的关键创新在于提出了(k,t)-ring邻域结构和分层Transformer聚合方式。 (k,t)-ring邻域结构能够有效地捕捉节点距离和类型上的异构性,而分层Transformer则能够逐步聚合不同粒度的信息,从而更好地学习节点表示。与现有方法相比,HHGT能够更有效地利用异构信息,从而提高模型性能。
关键设计: * (k,t)-ring邻域:k表示距离,t表示节点类型。通过调整k和t的值,可以控制邻域的大小和类型。 * 类型级Transformer:使用标准的Transformer结构,但输入是同一(k,t)-ring内的不同类型节点。 * 环级Transformer:同样使用标准的Transformer结构,但输入是来自不同(k,t)-ring的节点表示。 * 损失函数:根据下游任务选择合适的损失函数,例如交叉熵损失或对比学习损失。
🖼️ 关键图片
📊 实验亮点
实验结果表明,HHGT在节点聚类任务上显著优于14个基线模型。在ACM数据集上,HHGT的NMI指标比最佳基线提高了24.75%,ARI指标提高了29.25%。这些结果验证了HHGT模型在异构图表示学习方面的优越性,表明其能够更有效地捕捉异构信息网络中的复杂关系。
🎯 应用场景
HHGT模型可应用于多种异构信息网络分析任务,例如社交网络分析、推荐系统、生物信息学等。在社交网络中,可以用于用户聚类、好友推荐等;在推荐系统中,可以用于物品推荐、用户画像等;在生物信息学中,可以用于基因功能预测、蛋白质相互作用网络分析等。该研究有助于提升异构信息网络分析的准确性和效率。
📄 摘要(原文)
Despite the success of Heterogeneous Graph Neural Networks (HGNNs) in modeling real-world Heterogeneous Information Networks (HINs), challenges such as expressiveness limitations and over-smoothing have prompted researchers to explore Graph Transformers (GTs) for enhanced HIN representation learning. However, research on GT in HINs remains limited, with two key shortcomings in existing work: (1) A node's neighbors at different distances in HINs convey diverse semantics. Unfortunately, existing methods ignore such differences and uniformly treat neighbors within a given distance in a coarse manner, which results in semantic confusion. (2) Nodes in HINs have various types, each with unique semantics. Nevertheless, existing methods mix nodes of different types during neighbor aggregation, hindering the capture of proper correlations between nodes of diverse types. To bridge these gaps, we design an innovative structure named (k,t)-ring neighborhood, where nodes are initially organized by their distance, forming different non-overlapping k-ring neighborhoods for each distance. Within each k-ring structure, nodes are further categorized into different groups according to their types, thus emphasizing the heterogeneity of both distances and types in HINs naturally. Based on this structure, we propose a novel Hierarchical Heterogeneous Graph Transformer (HHGT) model, which seamlessly integrates a Type-level Transformer for aggregating nodes of different types within each k-ring neighborhood, followed by a Ring-level Transformer for aggregating different k-ring neighborhoods in a hierarchical manner. Extensive experiments are conducted on downstream tasks to verify HHGT's superiority over 14 baselines, with a notable improvement of up to 24.75% in NMI and 29.25% in ARI for node clustering task on the ACM dataset compared to the best baseline.