Mamba-PTQ: Outlier Channels in Recurrent Large Language Models
作者: Alessandro Pierro, Steven Abreu
分类: cs.LG, cs.AI, cs.NE
发布日期: 2024-07-17
备注: Work presented at the Efficient Systems for Foundation Models Workshop @ ICML2024
💡 一句话要点
Mamba-PTQ:揭示循环LLM中激活异常通道问题并初步探索量化方案
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Mamba模型 循环神经网络 量化 训练后量化 激活异常值 模型压缩 大型语言模型
📋 核心要点
- 现有LLM压缩技术在循环神经网络上的效果研究不足,尤其是在量化方面。
- 该研究发现Mamba模型存在与Transformer类似的激活异常通道问题,影响量化效果。
- 论文初步探索了Mamba模型的训练后量化,并提出了针对异常值的量化思路。
📝 摘要(中文)
现代循环层正在成为在边缘设备上部署基础模型(特别是大型语言模型LLM)的一种有前景的途径。通过将整个输入序列压缩成有限维表示,循环层能够对长程依赖关系进行建模,同时保持每个token的恒定推理成本和固定的内存需求。然而,在资源受限环境中实际部署LLM通常需要进一步的模型压缩,例如量化和剪枝。虽然这些技术对于基于注意力机制的模型来说已经很成熟,但它们对循环层的影响仍未被充分探索。在这项初步工作中,我们专注于循环LLM的训练后量化,并表明Mamba模型表现出与基于注意力机制的LLM中观察到的相同的异常通道模式。我们表明,量化SSM的困难是由于激活异常值引起的,类似于在基于Transformer的LLM中观察到的那些。我们报告了Mamba的训练后量化的基线结果,这些结果没有考虑激活异常值,并提出了异常值感知量化的初步步骤。
🔬 方法详解
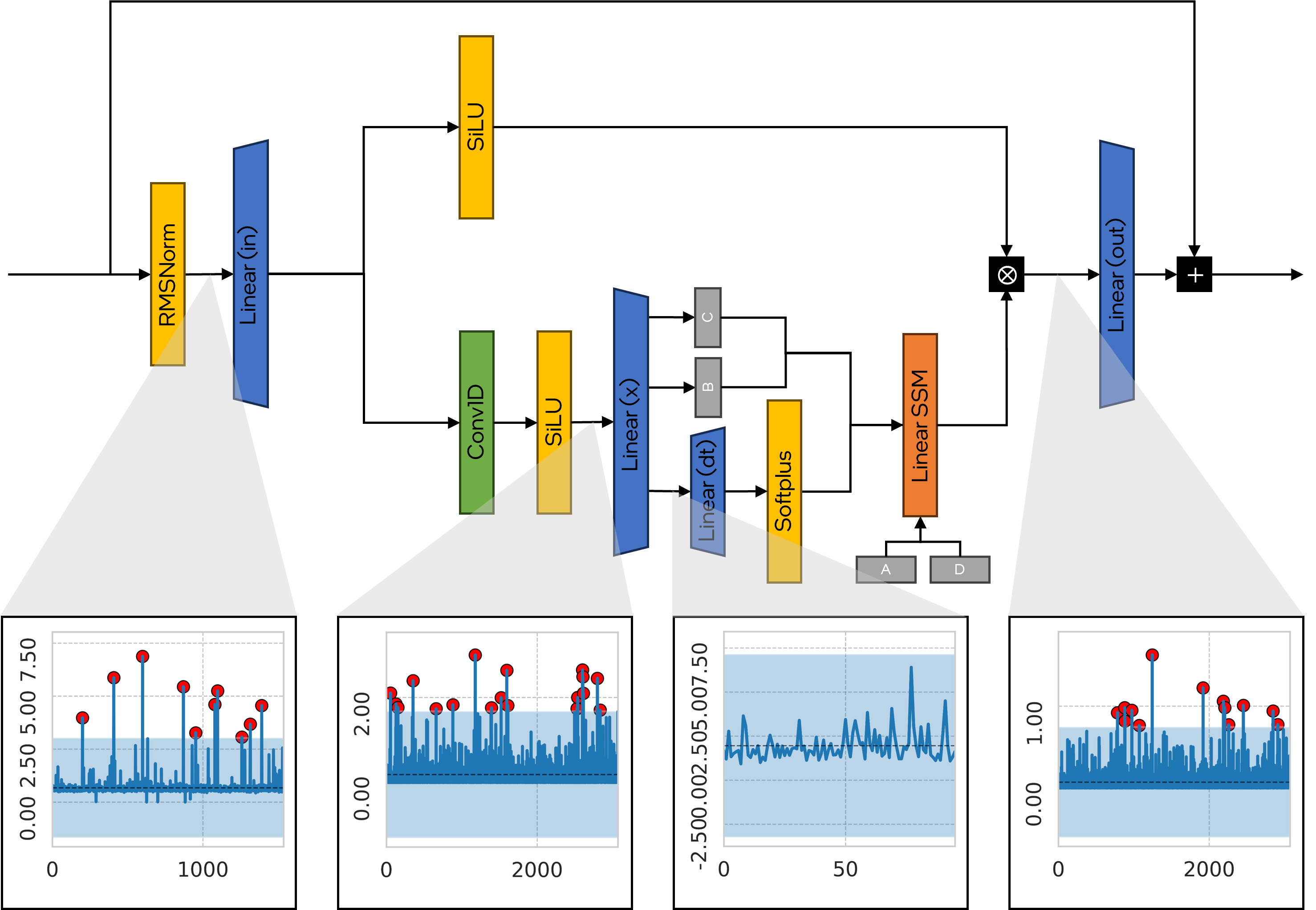
问题定义:论文旨在解决循环大型语言模型(LLM)在资源受限设备上部署时,模型量化所面临的挑战。现有方法在基于注意力机制的模型上表现良好,但对循环LLM(如Mamba)的量化效果不佳,主要原因是激活中存在异常值通道。
核心思路:论文的核心思路是识别并解决Mamba模型中存在的激活异常值问题,类似于Transformer模型中观察到的现象。通过分析激活分布,发现某些通道的激活值远大于其他通道,导致量化时信息损失严重。针对这些异常值,需要采取特殊的量化策略。
技术框架:该研究主要关注Mamba模型的训练后量化(PTQ)。首先,对Mamba模型进行前向推理,收集激活值统计信息。然后,分析激活值的分布,识别出异常值通道。最后,探索针对异常值通道的量化方法,例如调整量化范围或使用不同的量化策略。目前的工作主要集中在识别问题和提供初步的解决方案思路。
关键创新:该研究的关键创新在于首次揭示了Mamba模型中存在与Transformer类似的激活异常值问题,并将其与量化困难联系起来。这为后续研究Mamba模型的量化提供了新的方向。
关键设计:论文目前处于初步研究阶段,主要关注问题的识别和分析。未来的工作将涉及设计具体的异常值感知量化算法,例如:1)针对异常值通道使用更大的量化范围;2)对异常值通道进行单独的量化;3)在量化前对激活值进行预处理,以减小异常值的影响。具体的参数设置、损失函数和网络结构与原始Mamba模型保持一致,重点在于量化策略的调整。
🖼️ 关键图片

📊 实验亮点
论文初步实验结果表明,直接对Mamba模型进行训练后量化会导致显著的性能下降。通过分析激活值分布,发现Mamba模型中存在激活异常值通道,这可能是导致量化困难的原因。论文提出了针对异常值通道的量化思路,为后续研究提供了方向。虽然目前没有给出具体的性能提升数据,但该研究为Mamba模型的量化提供了一个重要的起点。
🎯 应用场景
该研究成果可应用于边缘设备上循环LLM的部署,例如智能手机、嵌入式系统等。通过解决量化难题,可以显著降低模型大小和计算复杂度,从而在资源受限的环境中实现高性能的自然语言处理应用,如语音识别、机器翻译、文本生成等。未来的研究可以进一步探索更有效的量化方法,并将其应用于其他循环神经网络。
📄 摘要(原文)
Modern recurrent layers are emerging as a promising path toward edge deployment of foundation models, especially in the context of large language models (LLMs). Compressing the whole input sequence in a finite-dimensional representation enables recurrent layers to model long-range dependencies while maintaining a constant inference cost for each token and a fixed memory requirement. However, the practical deployment of LLMs in resource-limited environments often requires further model compression, such as quantization and pruning. While these techniques are well-established for attention-based models, their effects on recurrent layers remain underexplored. In this preliminary work, we focus on post-training quantization for recurrent LLMs and show that Mamba models exhibit the same pattern of outlier channels observed in attention-based LLMs. We show that the reason for the difficulty of quantizing SSMs is caused by activation outliers, similar to those observed in transformer-based LLMs. We report baseline results for post-training quantization of Mamba that do not take into account the activation outliers and suggest first steps for outlier-aware quantization.