Private prediction for large-scale synthetic text generation
作者: Kareem Amin, Alex Bie, Weiwei Kong, Alexey Kurakin, Natalia Ponomareva, Umar Syed, Andreas Terzis, Sergei Vassilvitskii
分类: cs.LG, cs.CL, cs.CR
发布日期: 2024-07-16 (更新: 2024-10-09)
备注: 20 pages; updated figure + some new experiments from EMNLP 2024 findings camera-ready
💡 一句话要点
提出基于私有预测的大规模合成文本生成方法,提升数据质量与隐私保护水平
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 差分隐私 合成数据生成 大型语言模型 私有预测 文本生成
📋 核心要点
- 现有方法在生成私有文本时,通常生成少量数据,限制了其应用范围,难以满足大规模数据需求。
- 论文提出私有预测框架,利用改进的隐私分析和私有选择机制,以及公共预测方法,提升生成数据质量。
- 实验表明,该方法能够生成数千个高质量的合成数据点,扩展了差分隐私文本生成技术的应用场景。
📝 摘要(中文)
本文提出了一种利用大型语言模型(LLM)通过私有预测生成差分隐私合成文本的方法。与训练生成模型并确保模型本身安全发布的方法不同,该方法仅要求输出的合成数据满足差分隐私保证。我们使用源数据提示预训练的LLM,但确保下一个token的预测是在差分隐私保证下进行的。先前的工作在这个范例中报告了在合理的隐私级别下生成少量示例(<10),这些数据仅对下游上下文学习或提示有用。相比之下,我们进行了改进,可以生成数千个高质量的合成数据点,从而大大扩展了潜在的应用范围。我们的改进来自改进的隐私分析和更好的私有选择机制,该机制利用了LLM中用于采样token的softmax层与指数机制之间的等价性。此外,我们引入了一种通过稀疏向量技术使用公共预测的新方法,在这种方法中,我们不为那些无需敏感数据即可预测的token支付隐私成本;我们发现这对于结构化数据特别有效。
🔬 方法详解
问题定义:论文旨在解决大规模生成具有差分隐私保证的合成文本数据的问题。现有方法,特别是基于训练生成模型的方法,存在模型泄露训练数据隐私的风险。即使采用差分隐私训练,也可能导致模型可用性下降。此外,已有的基于私有预测的方法,通常只能生成少量数据,难以满足实际应用需求。
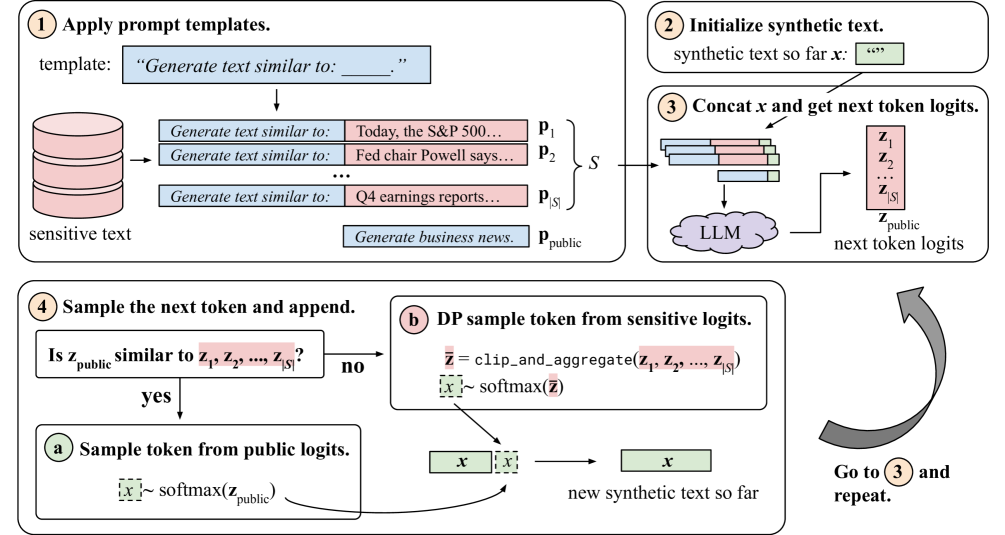
核心思路:论文的核心思路是利用预训练的大型语言模型(LLM)进行私有预测,即在生成文本的每一步,对下一个token的预测都加入差分隐私噪声。关键在于,只对输出的合成数据施加隐私保护,而无需对LLM本身进行隐私训练,从而避免了模型泄露隐私的风险,并能充分利用预训练模型的强大生成能力。
技术框架:整体流程如下:1. 使用源数据提示预训练的LLM。2. 对于每个token的预测,使用改进的私有选择机制(基于softmax层和指数机制的等价性)添加差分隐私噪声。3. 利用稀疏向量技术,对于那些可以从公共数据中预测的token,不支付隐私成本。4. 重复步骤2和3,直到生成完整的合成文本。
关键创新:论文的关键创新在于:1. 改进的隐私分析,更精确地计算隐私损失,从而在相同隐私预算下生成更多数据。2. 更好的私有选择机制,利用softmax层和指数机制的等价性,更高效地添加噪声。3. 引入公共预测方法,通过稀疏向量技术,避免对可公开预测的token支付隐私成本,显著提升了生成数据的质量和数量。
关键设计:1. 私有选择机制:利用softmax输出概率分布,将其转化为指数机制的评分函数,从而实现差分隐私的token选择。2. 稀疏向量技术:维护一个计数器,记录每个token被预测的次数,如果某个token的预测次数超过阈值,则认为该token可以从公共数据中预测,不再支付隐私成本。3. 隐私预算分配:合理分配每个token预测的隐私预算,以平衡生成数据的质量和隐私保护程度。
🖼️ 关键图片
📊 实验亮点
论文通过改进隐私分析、私有选择机制和引入公共预测方法,显著提升了合成文本生成的数据量和质量。实验结果表明,该方法能够在保证差分隐私的前提下,生成数千个高质量的合成数据点,相比之前的工作有显著提升。尤其是在结构化数据上,公共预测方法的应用效果显著。
🎯 应用场景
该研究成果可应用于多种场景,例如:生成具有隐私保护的医疗记录、金融交易记录、用户行为数据等,用于数据分析、模型训练和算法评估。这有助于在保护用户隐私的前提下,促进数据共享和利用,推动相关领域的研究和发展。此外,该方法还可以用于生成合成的对话数据,用于训练聊天机器人和对话系统。
📄 摘要(原文)
We present an approach for generating differentially private synthetic text using large language models (LLMs), via private prediction. In the private prediction framework, we only require the output synthetic data to satisfy differential privacy guarantees. This is in contrast to approaches that train a generative model on potentially sensitive user-supplied source data and seek to ensure the model itself is safe to release. We prompt a pretrained LLM with source data, but ensure that next-token predictions are made with differential privacy guarantees. Previous work in this paradigm reported generating a small number of examples (<10) at reasonable privacy levels, an amount of data that is useful only for downstream in-context learning or prompting. In contrast, we make changes that allow us to generate thousands of high-quality synthetic data points, greatly expanding the set of potential applications. Our improvements come from an improved privacy analysis and a better private selection mechanism, which makes use of the equivalence between the softmax layer for sampling tokens in LLMs and the exponential mechanism. Furthermore, we introduce a novel use of public predictions via the sparse vector technique, in which we do not pay privacy costs for tokens that are predictable without sensitive data; we find this to be particularly effective for structured data.