SuperPADL: Scaling Language-Directed Physics-Based Control with Progressive Supervised Distillation
作者: Jordan Juravsky, Yunrong Guo, Sanja Fidler, Xue Bin Peng
分类: cs.LG, cs.AI, cs.CL, cs.GR
发布日期: 2024-07-15
💡 一句话要点
SuperPADL:通过渐进式监督蒸馏扩展语言驱动的物理控制
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱八:物理动画 (Physics-based Animation)
关键词: 物理动画 强化学习 监督学习 蒸馏训练 文本到运动 人机交互 运动控制
📋 核心要点
- 现有基于强化学习的物理动画方法难以扩展到大规模、多样化的动作数据集。
- SuperPADL通过渐进式监督蒸馏,结合强化学习和监督学习,训练可扩展的控制器。
- SuperPADL在包含5000多个技能的数据集上训练,并在消费级GPU上实时运行,性能优于RL基线。
📝 摘要(中文)
用于人体运动的物理模拟模型能够生成高质量、响应迅速的角色动画,通常是实时的。自然语言作为控制这些模型的灵活接口,允许专家和非专业用户快速创建和编辑动画。许多最新的基于物理的动画方法,包括那些使用文本界面的方法,都使用强化学习(RL)来训练控制策略。然而,将这些方法扩展到数百个动作以上仍然具有挑战性。同时,运动学动画模型能够通过利用监督学习方法成功地从数千个不同的动作中学习。受这些成功的启发,本文提出了SuperPADL,这是一个可扩展的物理文本到运动框架,它利用强化学习和监督学习在数千个不同的运动片段上训练控制器。SuperPADL通过渐进式蒸馏分阶段训练,首先使用大量的强化学习专家。然后,使用强化学习和监督学习相结合的方式,将这些专家迭代地提炼成更大、更强大的策略。最终的SuperPADL控制器在包含超过5000个技能的数据集上进行训练,并在消费级GPU上实时运行。此外,该策略可以自然地在技能之间转换,允许用户交互式地制作多阶段动画。实验结果表明,SuperPADL在这种大数据规模下明显优于基于强化学习的基线方法。
🔬 方法详解
问题定义:现有基于强化学习的物理动画方法,虽然能生成高质量的动画,但在处理大规模、多样化的动作数据集时面临挑战。强化学习训练成本高,难以扩展到数千个不同的运动片段。因此,如何高效地训练能够处理大量技能的物理动画控制器是一个关键问题。
核心思路:SuperPADL的核心思路是结合强化学习和监督学习的优势,通过渐进式蒸馏的方式,将多个强化学习训练的专家策略提炼成一个更通用、更强大的策略。利用强化学习训练专家策略,然后利用监督学习加速策略的学习和泛化能力。
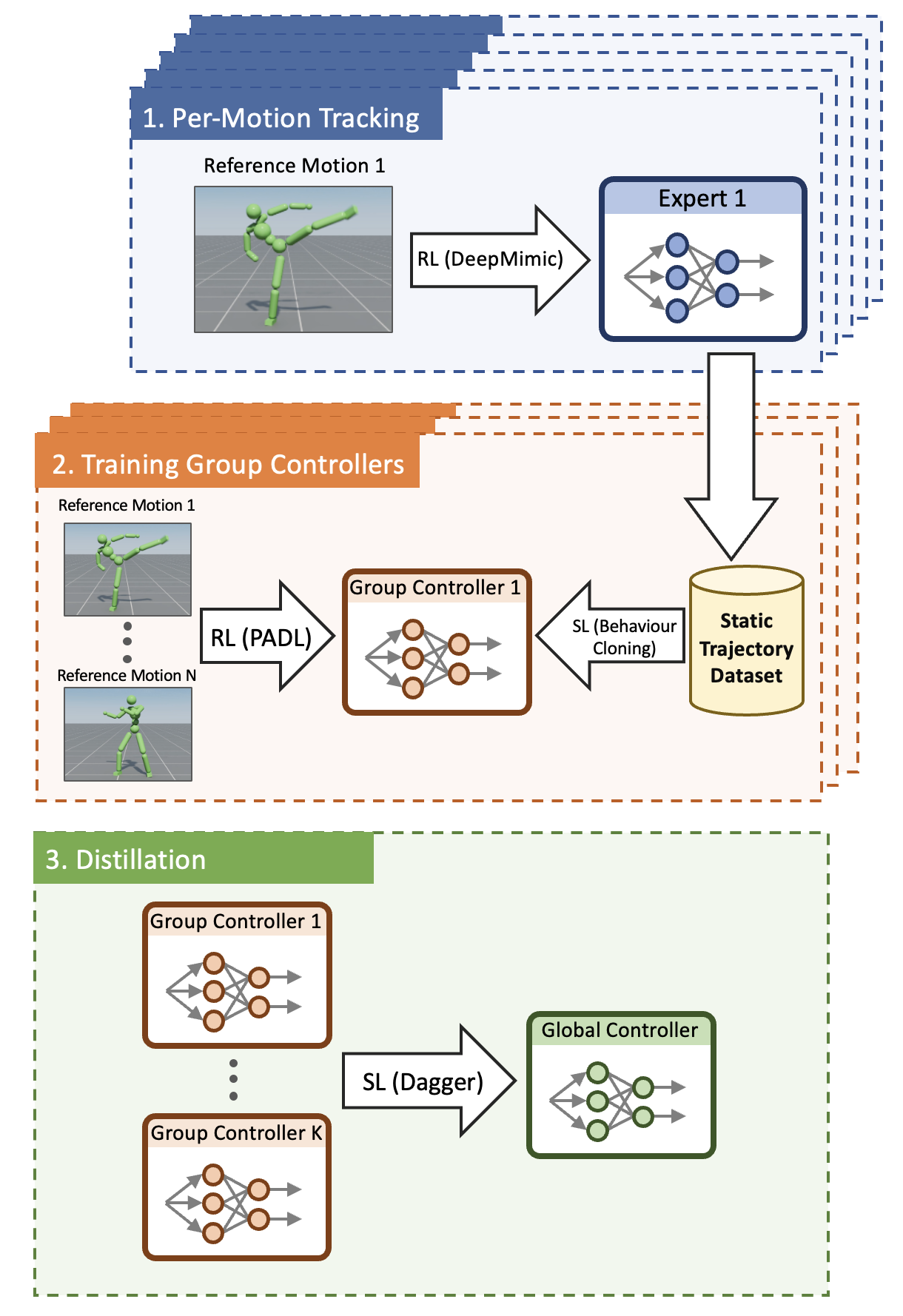
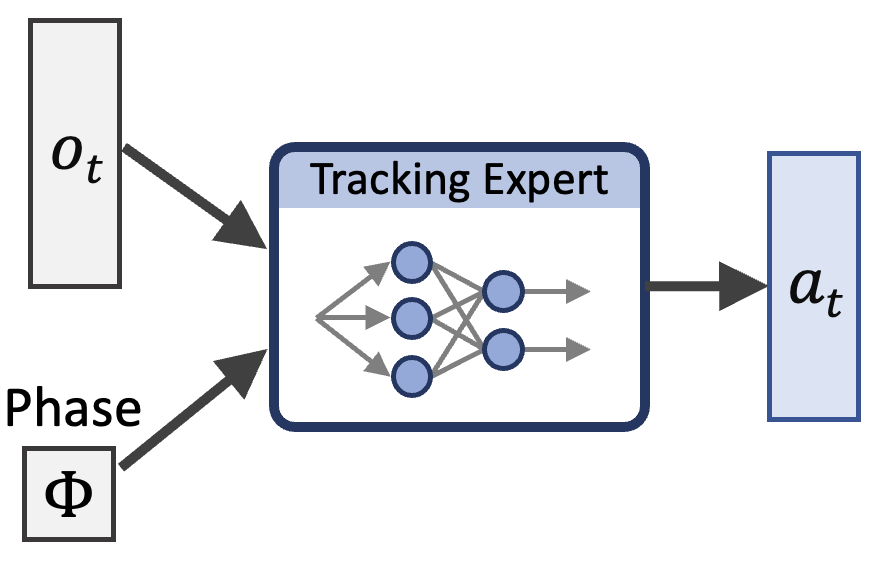
技术框架:SuperPADL的整体框架包含以下几个阶段: 1. 专家策略训练:使用强化学习训练多个针对特定技能的专家策略。 2. 渐进式蒸馏:将这些专家策略迭代地蒸馏成更大的、更鲁棒的策略。这个过程结合了强化学习和监督学习。 3. 最终控制器训练:在包含大量技能的数据集上,训练最终的SuperPADL控制器。
关键创新:SuperPADL的关键创新在于其渐进式监督蒸馏框架,它有效地结合了强化学习和监督学习的优势。通过先训练专家策略,再进行蒸馏,可以避免直接在大规模数据集上训练强化学习策略的困难。此外,使用监督学习加速了策略的学习和泛化能力,使得控制器能够处理大量技能。
关键设计:SuperPADL的关键设计包括: 1. 专家策略的强化学习训练方法:具体使用的强化学习算法(例如PPO)以及奖励函数的设计。 2. 蒸馏过程中的损失函数设计:如何结合强化学习的奖励和监督学习的损失,以平衡策略的探索和模仿能力。 3. 网络结构设计:控制器的网络结构,例如使用循环神经网络(RNN)来处理时序信息,以及如何将文本信息融入到网络中。
🖼️ 关键图片

📊 实验亮点
SuperPADL在包含超过5000个技能的数据集上进行了实验,结果表明,SuperPADL明显优于基于强化学习的基线方法。SuperPADL控制器能够在消费级GPU上实时运行,并且可以自然地在技能之间转换,允许用户交互式地制作多阶段动画。这些结果表明,SuperPADL是一种可扩展的、高效的物理动画控制方法。
🎯 应用场景
SuperPADL具有广泛的应用前景,例如在游戏开发中,可以根据玩家的自然语言指令,实时生成高质量的角色动画。在虚拟现实和增强现实应用中,可以创建更逼真、更具交互性的虚拟角色。此外,该技术还可以应用于机器人控制领域,使机器人能够根据自然语言指令执行复杂的物理任务。
📄 摘要(原文)
Physically-simulated models for human motion can generate high-quality responsive character animations, often in real-time. Natural language serves as a flexible interface for controlling these models, allowing expert and non-expert users to quickly create and edit their animations. Many recent physics-based animation methods, including those that use text interfaces, train control policies using reinforcement learning (RL). However, scaling these methods beyond several hundred motions has remained challenging. Meanwhile, kinematic animation models are able to successfully learn from thousands of diverse motions by leveraging supervised learning methods. Inspired by these successes, in this work we introduce SuperPADL, a scalable framework for physics-based text-to-motion that leverages both RL and supervised learning to train controllers on thousands of diverse motion clips. SuperPADL is trained in stages using progressive distillation, starting with a large number of specialized experts using RL. These experts are then iteratively distilled into larger, more robust policies using a combination of reinforcement learning and supervised learning. Our final SuperPADL controller is trained on a dataset containing over 5000 skills and runs in real time on a consumer GPU. Moreover, our policy can naturally transition between skills, allowing for users to interactively craft multi-stage animations. We experimentally demonstrate that SuperPADL significantly outperforms RL-based baselines at this large data scale.