LeanQuant: Accurate and Scalable Large Language Model Quantization with Loss-error-aware Grid
作者: Tianyi Zhang, Anshumali Shrivastava
分类: cs.LG
发布日期: 2024-07-14 (更新: 2026-01-01)
备注: Published in ICLR 2025
💡 一句话要点
LeanQuant:提出损失误差感知网格,实现准确且可扩展的大语言模型量化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型量化 后训练量化 损失误差感知 模型压缩 低精度推理
📋 核心要点
- 现有PTQ方法依赖特定计算或数据格式,兼容性差,需定制推理内核,阻碍广泛应用,且计算开销大,难以扩展到千亿参数模型。
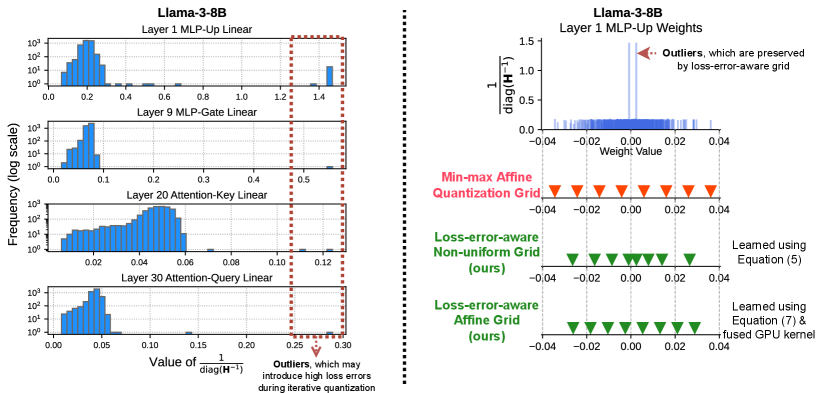
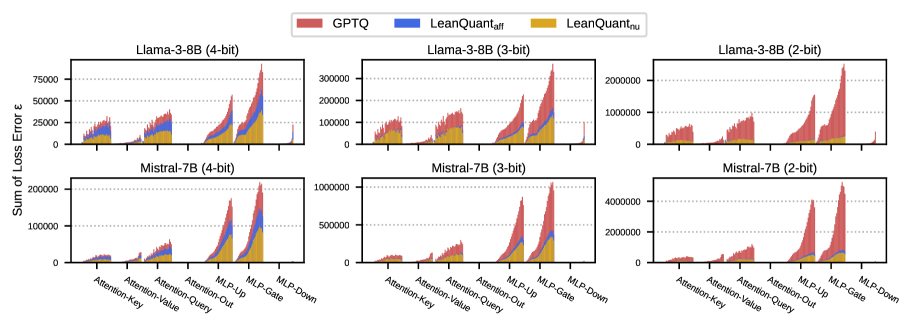
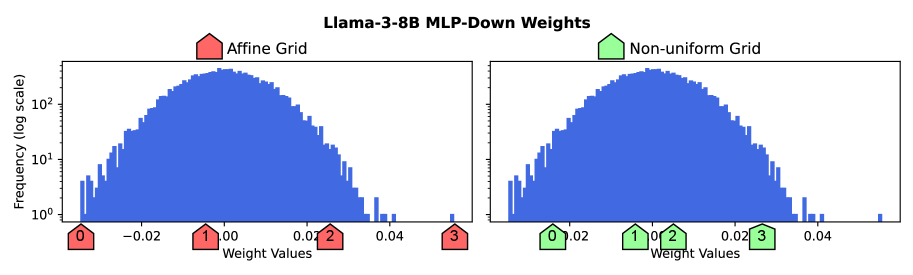
- LeanQuant提出损失误差感知网格,替代非自适应的最小-最大仿射网格,提升量化精度,并能推广到多种量化类型,增强框架兼容性。
- 实验表明,LeanQuant在模型质量上优于现有方法,并成功量化了Llama-3.1 405B模型,仅用两块GPU在21小时内完成。
📝 摘要(中文)
大语言模型(LLMs)在各个领域展现出巨大潜力,但其高内存需求和推理成本仍然是部署的关键挑战。后训练量化(PTQ)已成为一种有前景的技术,可以降低内存需求和解码延迟。然而,最近的精确量化方法通常依赖于专门的计算或自定义数据格式来实现更好的模型质量,这限制了它们与流行框架的兼容性,因为它们需要针对特定硬件和软件平台量身定制的专用推理内核,从而阻碍了更广泛的应用。此外,许多有竞争力的方法在量化模型时具有高资源需求和计算开销,使得将它们扩展到数千亿参数具有挑战性。为了应对这些挑战,我们提出了一种新颖的量化方法LeanQuant(损失误差感知网络量化),该方法准确、通用且可扩展。在现有的流行的基于迭代损失误差的量化框架中,我们发现先前方法的一个关键限制:由于逆Hessian对角线中的异常值,最小-最大仿射量化网格无法保持模型质量。为了克服这个根本问题,我们建议学习损失误差感知网格,而不是使用非自适应最小-最大仿射网格。我们的方法不仅产生更准确的量化模型,而且可以推广到更广泛的量化类型,包括仿射和非均匀量化,从而增强与更多框架的兼容性。对最近的LLM进行的大量实验表明,LeanQuant非常准确,在模型质量方面与有竞争力的基线相比具有优势,并且可扩展,使用两个Quadro RTX 8000-48GB GPU在21小时内实现了对Llama-3.1 405B(迄今为止最大的开源LLM之一)的非常准确的量化。
🔬 方法详解
问题定义:现有后训练量化(PTQ)方法为了追求更高的量化精度,往往需要定制化的计算和数据格式,导致与主流深度学习框架的兼容性较差,需要针对特定硬件和软件平台开发专门的推理内核。此外,这些方法的计算资源需求高,难以扩展到更大规模的语言模型(如千亿参数模型)。
核心思路:LeanQuant的核心思路是学习一个损失误差感知的量化网格,而不是使用传统的非自适应的最小-最大仿射网格。作者发现,现有方法中使用的最小-最大仿射网格容易受到逆Hessian对角线中异常值的影响,导致量化后的模型质量下降。通过学习一个能够感知损失误差的网格,可以更好地适应模型参数的分布,从而提高量化精度。
技术框架:LeanQuant沿用了迭代的损失误差量化框架,主要包含以下几个阶段:1) 初始化量化参数;2) 计算量化误差;3) 根据量化误差更新量化网格;4) 重复2和3,直到收敛。与现有方法的关键区别在于,LeanQuant使用可学习的损失误差感知网格来替代固定的最小-最大仿射网格。
关键创新:LeanQuant最关键的创新点在于提出了损失误差感知网格。与传统的最小-最大仿射网格相比,损失误差感知网格能够更好地适应模型参数的分布,从而提高量化精度。此外,LeanQuant的设计使其能够兼容多种量化类型,包括仿射量化和非均匀量化,从而增强了其通用性。
关键设计:LeanQuant的关键设计在于如何学习损失误差感知网格。具体来说,作者使用一个小的神经网络来预测每个参数的量化步长,该网络的输入是参数的梯度和Hessian信息。损失函数被设计为最小化量化误差,同时鼓励量化步长尽可能均匀。此外,作者还使用了一些正则化技术来防止过拟合。
🖼️ 关键图片
📊 实验亮点
LeanQuant在多个大语言模型上进行了实验,结果表明其量化精度优于现有方法。例如,在Llama-3.1 405B模型上,LeanQuant仅使用两块Quadro RTX 8000-48GB GPU,在21小时内完成了量化,并且保持了较高的模型质量。这证明了LeanQuant在准确性和可扩展性方面的优势。
🎯 应用场景
LeanQuant可应用于大语言模型的低成本部署,降低内存占用和推理延迟,使其能够在资源受限的设备上运行,例如移动设备、边缘设备等。该技术还有助于降低云计算成本,加速AI在各行业的落地,例如智能客服、内容生成、机器翻译等。
📄 摘要(原文)
Large language models (LLMs) have shown immense potential across various domains, but their high memory requirements and inference costs remain critical challenges for deployment. Post-training quantization (PTQ) has emerged as a promising technique to reduce memory requirements and decoding latency. However, recent accurate quantization methods often depend on specialized computations or custom data formats to achieve better model quality, which limits their compatibility with popular frameworks, as they require dedicated inference kernels tailored to specific hardware and software platforms, hindering wider adoption. Furthermore, many competitive methods have high resource requirements and computational overhead for quantizing models, making it challenging to scale them to hundreds of billions of parameters. In response to these challenges, we propose LeanQuant (Loss-Error-Aware Network Quantization), a novel quantization method that is accurate, versatile, and scalable. In the existing popular iterative loss-error-based quantization framework, we identify a critical limitation in prior methods: the min-max affine quantization grid fails to preserve model quality due to outliers in inverse Hessian diagonals. To overcome this fundamental issue, we propose learning loss-error-aware grids, instead of using non-adaptive min-max affine grids. Our approach not only produces quantized models that are more accurate but also generalizes to a wider range of quantization types, including affine and non-uniform quantization, enhancing compatibility with more frameworks. Extensive experiments with recent LLMs demonstrate that LeanQuant is highly accurate, comparing favorably against competitive baselines in model quality, and scalable, achieving very accurate quantization of Llama-3.1 405B, one of the largest open-source LLMs to date, using two Quadro RTX 8000-48GB GPUs in 21 hours.