Global Reinforcement Learning: Beyond Linear and Convex Rewards via Submodular Semi-gradient Methods
作者: Riccardo De Santi, Manish Prajapat, Andreas Krause
分类: cs.LG
发布日期: 2024-07-13
备注: ICML 2024
💡 一句话要点
提出基于次模半梯度方法的全局强化学习,解决传统RL在复杂奖励建模上的局限性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 全局强化学习 次模优化 半梯度方法 非线性奖励 状态交互
📋 核心要点
- 传统强化学习依赖加性奖励函数,无法有效建模状态间的复杂交互关系,限制了其在许多实际场景中的应用。
- 论文提出全局强化学习(GRL)框架,利用次模性、超模性等概念,对轨迹上的全局奖励进行建模,捕捉状态间的正负交互。
- 通过将GRL问题转化为一系列经典RL问题,并结合次模优化理论,实现了高效求解,并在实验中验证了方法的有效性。
📝 摘要(中文)
经典强化学习(RL)中,智能体通常最大化访问状态的加性目标,例如价值函数。然而,这种目标无法模拟许多现实世界的应用,如实验设计、探索、模仿学习和风险规避RL等。这是因为加性目标忽略了状态之间的交互,而这些交互对于某些任务至关重要。为了解决这个问题,我们引入了全局强化学习(GRL),其中奖励是全局定义的,基于轨迹而非局部状态。全局奖励可以通过次模性捕获状态之间的负交互(例如,在探索中),通过超模性捕获正交互(例如,协同效应),并通过它们的组合捕获混合交互。通过利用次模优化的思想,我们提出了一种新颖的算法方案,该方案将任何GRL问题转换为一系列经典RL问题,并以依赖于曲率的近似保证有效地解决它。我们还提供了近似硬度结果,并通过几个GRL实例在经验上证明了我们方法的有效性。
🔬 方法详解
问题定义:传统强化学习方法主要依赖于加性奖励函数,即智能体获得的奖励是各个状态奖励的简单加总。这种方式忽略了不同状态之间的相互作用,例如,在探索过程中,访问不同状态可能存在互斥性或协同性。因此,传统方法难以处理需要考虑状态间复杂关系的强化学习问题,如实验设计、探索、模仿学习等。现有方法的痛点在于无法有效建模和利用状态之间的非线性关系,导致在某些任务中表现不佳。
核心思路:论文的核心思路是将强化学习的奖励函数从局部状态奖励扩展到全局轨迹奖励。通过引入全局奖励函数,可以显式地建模状态之间的交互关系。具体而言,论文利用次模函数来捕捉状态之间的负交互(例如,探索中的互斥性),利用超模函数来捕捉状态之间的正交互(例如,协同效应)。通过这种方式,GRL能够更灵活地表达复杂的奖励结构,从而解决传统RL方法的局限性。
技术框架:GRL的整体框架包含以下几个主要阶段:1) 将GRL问题转化为一系列经典的RL问题。2) 利用现有的RL算法(例如,Q-learning、SARSA)求解转化后的经典RL问题。3) 基于次模优化理论,对求解结果进行近似保证。具体而言,论文提出了一种基于半梯度的算法,该算法通过迭代地选择轨迹,并更新价值函数,最终找到一个近似最优的策略。
关键创新:论文最重要的技术创新点在于将次模优化理论引入到强化学习中,并提出了相应的算法框架。通过利用次模函数的性质,论文能够为GRL问题提供近似保证,这在之前的强化学习研究中是很少见的。此外,论文还提出了一种将GRL问题转化为经典RL问题的方法,使得可以利用现有的RL算法来解决GRL问题。
关键设计:论文的关键设计包括:1) 全局奖励函数的定义,需要根据具体的应用场景选择合适的次模函数或超模函数。2) 将GRL问题转化为经典RL问题的具体方法,需要保证转化后的问题能够有效地近似原始的GRL问题。3) 半梯度算法的设计,需要选择合适的步长和更新策略,以保证算法的收敛性和近似性能。
🖼️ 关键图片
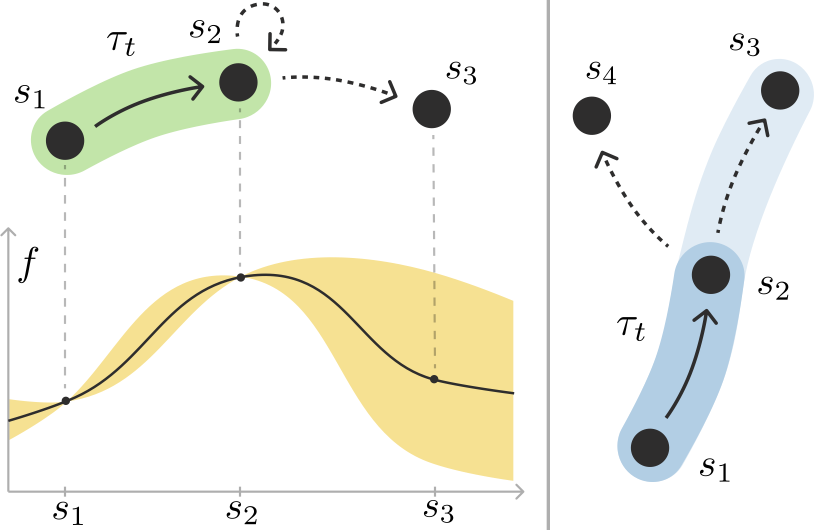


📊 实验亮点
论文通过实验验证了GRL方法的有效性。在多个GRL实例中,GRL方法都取得了优于传统RL方法的性能。例如,在探索任务中,GRL方法能够更快地探索到未知的区域,并获得更高的奖励。此外,实验结果还表明,GRL方法的性能与次模函数的曲率有关,曲率越小,性能越好。论文还提供了近似硬度结果,表明GRL问题的求解难度较高,需要设计高效的近似算法。
🎯 应用场景
全局强化学习在多个领域具有广泛的应用前景。例如,在实验设计中,可以利用GRL选择信息量最大的实验组合。在机器人探索中,GRL可以鼓励机器人探索未知的区域,同时避免重复访问已探索的区域。在模仿学习中,GRL可以学习专家轨迹中的复杂交互模式。此外,GRL还可以应用于风险规避强化学习,通过考虑不同状态之间的风险依赖关系,制定更加稳健的策略。未来,GRL有望在更多需要考虑状态间复杂关系的强化学习任务中发挥重要作用。
📄 摘要(原文)
In classic Reinforcement Learning (RL), the agent maximizes an additive objective of the visited states, e.g., a value function. Unfortunately, objectives of this type cannot model many real-world applications such as experiment design, exploration, imitation learning, and risk-averse RL to name a few. This is due to the fact that additive objectives disregard interactions between states that are crucial for certain tasks. To tackle this problem, we introduce Global RL (GRL), where rewards are globally defined over trajectories instead of locally over states. Global rewards can capture negative interactions among states, e.g., in exploration, via submodularity, positive interactions, e.g., synergetic effects, via supermodularity, while mixed interactions via combinations of them. By exploiting ideas from submodular optimization, we propose a novel algorithmic scheme that converts any GRL problem to a sequence of classic RL problems and solves it efficiently with curvature-dependent approximation guarantees. We also provide hardness of approximation results and empirically demonstrate the effectiveness of our method on several GRL instances.