URRL-IMVC: Unified and Robust Representation Learning for Incomplete Multi-View Clustering
作者: Ge Teng, Ting Mao, Chen Shen, Xiang Tian, Xuesong Liu, Yaowu Chen, Jieping Ye
分类: cs.LG, cs.CL, cs.CV
发布日期: 2024-07-12
备注: Accepted by ACM SIGKDD 2024
💡 一句话要点
提出URRL-IMVC,通过统一鲁棒表示学习解决不完全多视图聚类问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 不完全多视图聚类 统一表示学习 鲁棒性 注意力机制 KNN插补
📋 核心要点
- 现有IMVC方法侧重于视图间一致性,忽略了互补信息,或因缺乏监督导致恢复的视图不可靠。
- URRL-IMVC通过融合多视图信息和邻域样本,直接学习对视图缺失具有鲁棒性的统一嵌入表示。
- 实验表明,URRL-IMVC在多个数据集上取得了SOTA性能,并验证了各个模块的有效性。
📝 摘要(中文)
本文提出了一种用于不完全多视图聚类(IMVC)的统一鲁棒表示学习框架(URRL-IMVC),旨在解决多视图数据部分缺失情况下的聚类问题。URRL-IMVC通过融合多视图信息和邻域样本信息,直接学习对视图缺失条件具有鲁棒性的统一嵌入表示。该方法利用基于注意力机制的自编码器框架融合多视图信息,生成统一嵌入,并通过KNN插补和数据增强技术增强统一嵌入对视图缺失的鲁棒性,避免了显式的缺失视图恢复。此外,还引入了聚类模块和编码器定制等增量改进,以进一步提高整体性能。在多个基准数据集上的大量实验表明,URRL-IMVC框架达到了最先进的性能,并通过全面的消融研究验证了设计的有效性。
🔬 方法详解
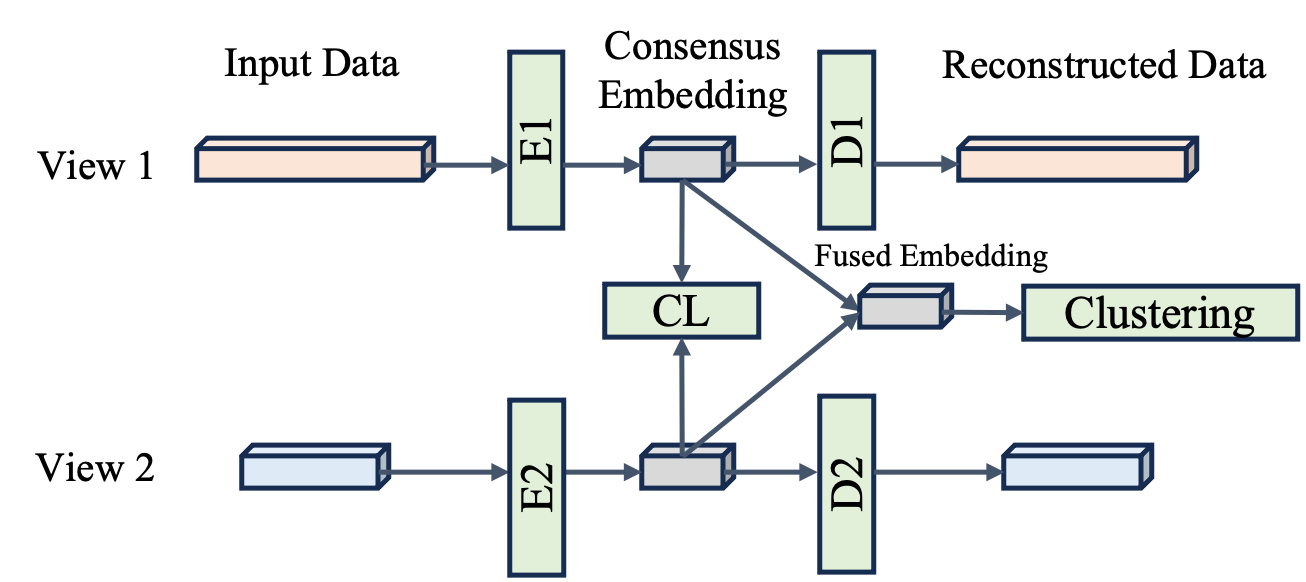
问题定义:不完全多视图聚类(IMVC)旨在处理多视图数据中部分视图缺失的情况。现有方法主要存在两个痛点:一是过度关注视图间的一致性,忽略了视图间的互补信息;二是依赖于缺失视图的恢复,但由于缺乏监督,恢复的视图质量难以保证,从而影响聚类性能。
核心思路:URRL-IMVC的核心思路是直接学习一个对视图缺失具有鲁棒性的统一嵌入表示,避免显式地恢复缺失视图。通过融合多视图信息和邻域样本的信息,使得学习到的嵌入表示能够抵抗视图缺失带来的影响。这样设计的目的是为了更有效地利用现有信息,并减少对不准确的缺失视图恢复的依赖。
技术框架:URRL-IMVC的整体框架包含以下几个主要模块:1) 基于注意力机制的自编码器:用于融合多视图信息,生成统一嵌入表示。注意力机制用于学习不同视图的重要性,从而更好地融合信息。2) KNN插补和数据增强:用于增强统一嵌入表示对视图缺失的鲁棒性。KNN插补利用邻域样本的信息来填充缺失的视图,数据增强则通过生成新的样本来扩充数据集。3) 聚类模块:用于对学习到的统一嵌入表示进行聚类。4) 编码器定制:针对不同视图的特点,定制不同的编码器结构。
关键创新:URRL-IMVC的关键创新在于直接学习鲁棒的统一嵌入表示,而不是依赖于缺失视图的恢复。通过融合多视图信息和邻域样本的信息,使得学习到的嵌入表示能够抵抗视图缺失带来的影响。与现有方法相比,URRL-IMVC避免了对不准确的缺失视图恢复的依赖,从而提高了聚类性能。
关键设计:1) 注意力机制:使用注意力机制来学习不同视图的重要性,从而更好地融合信息。2) KNN插补:使用KNN算法来填充缺失的视图,利用邻域样本的信息。3) 数据增强:通过生成新的样本来扩充数据集,提高模型的泛化能力。4) 损失函数:设计了合适的损失函数来优化模型,包括重构损失、聚类损失和鲁棒性损失。
🖼️ 关键图片


📊 实验亮点
URRL-IMVC在多个基准数据集上取得了显著的性能提升,例如在BBCSport数据集上,相较于第二好的基线方法,聚类准确率(ACC)提升了超过3%,标准化互信息(NMI)提升了超过2%。消融实验表明,各个模块(如注意力机制、KNN插补和数据增强)都对最终性能有积极贡献,验证了URRL-IMVC设计的有效性。
🎯 应用场景
URRL-IMVC可应用于多种实际场景,例如社交网络分析(用户属性不完整)、医学图像分析(模态数据缺失)和多媒体内容理解(部分媒体信息丢失)。该方法能够有效处理数据不完整的情况,提高聚类分析的准确性和可靠性,为相关领域的决策提供支持,并促进更深入的数据挖掘和知识发现。
📄 摘要(原文)
Incomplete multi-view clustering (IMVC) aims to cluster multi-view data that are only partially available. This poses two main challenges: effectively leveraging multi-view information and mitigating the impact of missing views. Prevailing solutions employ cross-view contrastive learning and missing view recovery techniques. However, they either neglect valuable complementary information by focusing only on consensus between views or provide unreliable recovered views due to the absence of supervision. To address these limitations, we propose a novel Unified and Robust Representation Learning for Incomplete Multi-View Clustering (URRL-IMVC). URRL-IMVC directly learns a unified embedding that is robust to view missing conditions by integrating information from multiple views and neighboring samples. Firstly, to overcome the limitations of cross-view contrastive learning, URRL-IMVC incorporates an attention-based auto-encoder framework to fuse multi-view information and generate unified embeddings. Secondly, URRL-IMVC directly enhances the robustness of the unified embedding against view-missing conditions through KNN imputation and data augmentation techniques, eliminating the need for explicit missing view recovery. Finally, incremental improvements are introduced to further enhance the overall performance, such as the Clustering Module and the customization of the Encoder. We extensively evaluate the proposed URRL-IMVC framework on various benchmark datasets, demonstrating its state-of-the-art performance. Furthermore, comprehensive ablation studies are performed to validate the effectiveness of our design.