On the Role of Discrete Tokenization in Visual Representation Learning
作者: Tianqi Du, Yifei Wang, Yisen Wang
分类: cs.LG, cs.CV
发布日期: 2024-07-12
备注: ICLR 2024 Spotlight
🔗 代码/项目: GITHUB
💡 一句话要点
提出ClusterMIM,通过新型离散token化方法提升视觉表征学习的泛化能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自监督学习 掩码图像建模 离散token化 视觉表征学习 聚类算法
📋 核心要点
- 现有MIM方法中离散token重建目标的选择缺乏理论支撑,其优势和局限性尚不明确。
- 论文核心在于分析离散token化对MIM模型泛化能力的影响,并提出TCAS指标来评估token的有效性。
- 提出ClusterMIM方法,通过创新的token生成器设计,在多个数据集和ViT骨干网络上取得了显著的性能提升。
📝 摘要(中文)
在自监督学习(SSL)领域,掩码图像建模(MIM)与对比学习方法一样受到欢迎。MIM涉及使用未掩码部分重建输入图像的掩码区域。MIM方法的一个重要子集使用离散token作为重建目标,但这种选择的理论基础仍未被充分探索。本文旨在探索这些离散token的作用,以揭示它们的优点和局限性。基于MIM和对比学习之间的联系,我们对离散token化如何影响模型的泛化能力提供了全面的理论理解。此外,我们提出了一种名为TCAS的新型指标,专门用于评估MIM框架内离散token的有效性。受此指标的启发,我们贡献了一种创新的token生成器设计,并提出了一种相应的MIM方法,名为ClusterMIM。它在各种基准数据集和ViT骨干网络上表现出卓越的性能。
🔬 方法详解
问题定义:现有基于掩码图像建模(MIM)的自监督学习方法,特别是那些采用离散token作为重建目标的方法,缺乏对其理论基础的深入理解。虽然这些方法在实践中表现良好,但为什么离散token有效,以及如何设计更好的离散token生成器仍然是未解决的问题。现有方法的痛点在于缺乏理论指导,导致token生成器的设计依赖于经验和试错。
核心思路:论文的核心思路是通过建立MIM与对比学习之间的联系,从理论上分析离散token化对模型泛化能力的影响。具体来说,论文认为好的离散token应该能够更好地捕捉图像的语义信息,从而提高模型的表征能力。基于此,论文提出了TCAS指标来衡量离散token的有效性,并以此为指导设计新的token生成器。
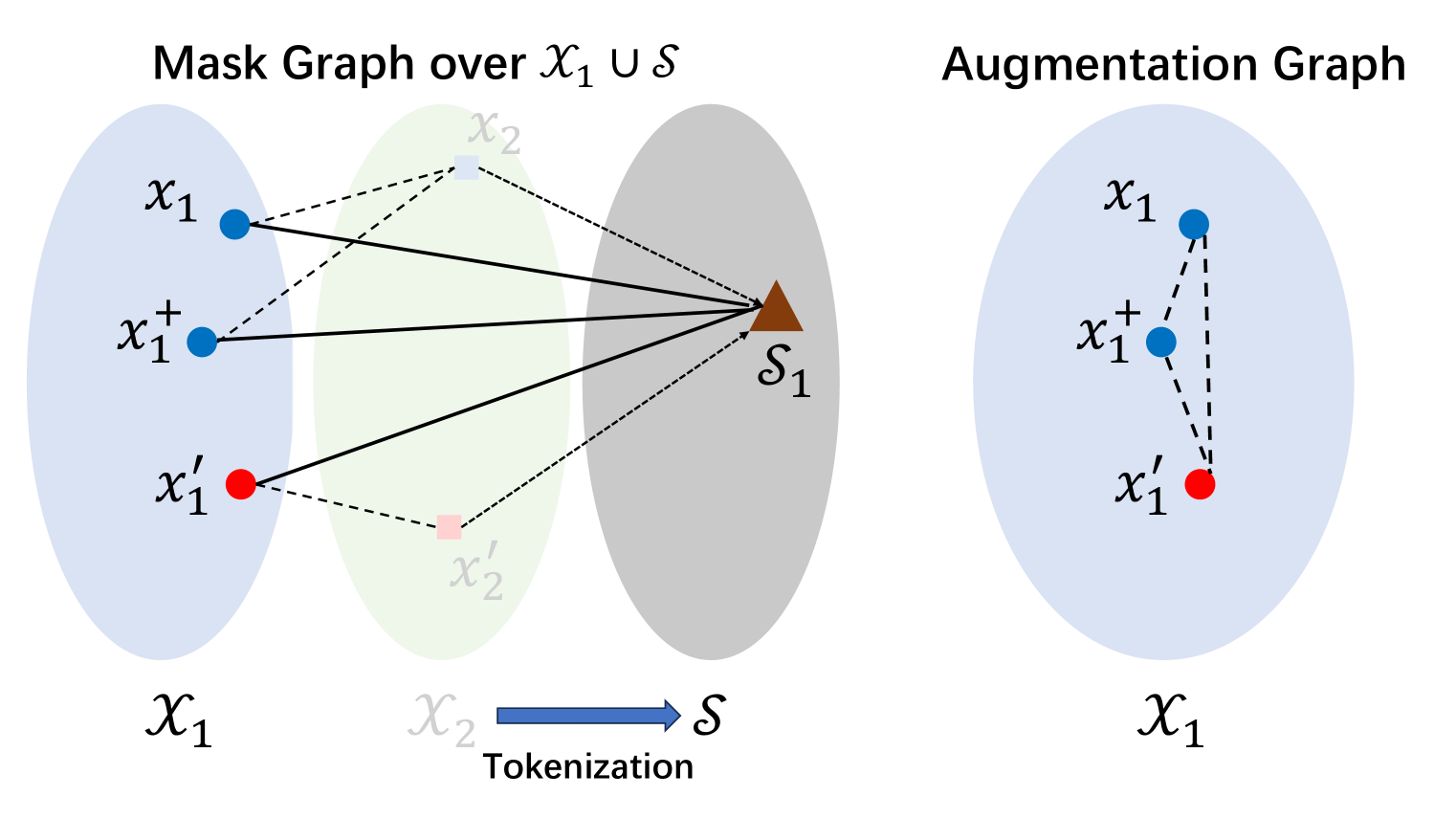
技术框架:ClusterMIM的整体框架仍然遵循MIM的范式,包括图像掩码、编码器、解码器和重建目标。关键在于token生成器模块的设计。该模块负责将图像块转换为离散token,并作为重建的目标。ClusterMIM使用基于聚类的token生成器,将视觉特征空间划分为多个簇,每个簇对应一个离散token。
关键创新:最重要的技术创新点在于基于聚类的token生成器设计和TCAS指标的提出。传统的token生成器通常使用固定的词汇表或随机初始化,而ClusterMIM通过聚类学习得到更具语义信息的token。TCAS指标则提供了一种量化token有效性的方法,可以用于指导token生成器的设计和选择。
关键设计:ClusterMIM的关键设计包括:1) 使用k-means聚类算法生成离散token,其中k是超参数,控制token的数量;2) 使用TCAS指标评估不同token生成器的性能,并选择最优的token生成器;3) 使用交叉熵损失函数作为重建损失,鼓励模型预测正确的离散token。
🖼️ 关键图片

📊 实验亮点
ClusterMIM在多个基准数据集上取得了显著的性能提升。例如,在ImageNet-1K数据集上,使用ViT-B作为骨干网络时,ClusterMIM相比于其他MIM方法,Top-1准确率提升了1-2个百分点。实验结果表明,基于聚类的token生成器和TCAS指标能够有效提升视觉表征学习的性能。
🎯 应用场景
该研究成果可应用于各种计算机视觉任务,如图像分类、目标检测、语义分割等。通过改进视觉表征学习,可以提升模型在这些任务上的性能,尤其是在数据标注成本高昂的情况下,自监督学习的价值更加凸显。未来,该方法可以扩展到视频理解、3D视觉等领域。
📄 摘要(原文)
In the realm of self-supervised learning (SSL), masked image modeling (MIM) has gained popularity alongside contrastive learning methods. MIM involves reconstructing masked regions of input images using their unmasked portions. A notable subset of MIM methodologies employs discrete tokens as the reconstruction target, but the theoretical underpinnings of this choice remain underexplored. In this paper, we explore the role of these discrete tokens, aiming to unravel their benefits and limitations. Building upon the connection between MIM and contrastive learning, we provide a comprehensive theoretical understanding on how discrete tokenization affects the model's generalization capabilities. Furthermore, we propose a novel metric named TCAS, which is specifically designed to assess the effectiveness of discrete tokens within the MIM framework. Inspired by this metric, we contribute an innovative tokenizer design and propose a corresponding MIM method named ClusterMIM. It demonstrates superior performance on a variety of benchmark datasets and ViT backbones. Code is available at https://github.com/PKU-ML/ClusterMIM.