Constructing Concept-based Models to Mitigate Spurious Correlations with Minimal Human Effort
作者: Jeeyung Kim, Ze Wang, Qiang Qiu
分类: cs.LG, cs.CV
发布日期: 2024-07-12
💡 一句话要点
提出一种利用多模态大模型构建概念瓶颈模型的方法,以缓解虚假相关性问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 概念瓶颈模型 可解释性 虚假相关性 预训练模型 多模态学习
📋 核心要点
- 现有概念瓶颈模型(CBMs)依赖大量人工标注,成本高昂,限制了其应用范围。
- 该论文提出利用多个预训练基础模型自动构建CBMs,降低人工标注成本,同时避免引入预训练模型中的偏差。
- 实验结果表明,该方法在多个数据集上有效降低了模型对虚假相关性的依赖,并保持了模型的可解释性。
📝 摘要(中文)
增强模型的可解释性可以通过揭示模型如何进行预测来解决虚假相关性问题。概念瓶颈模型(CBMs)提供了一种原则性的方法,通过人类可理解的概念来揭示和指导模型行为,但需要在数据标注方面投入大量人力。本文利用多个基础模型的协同作用,以几乎零人工成本构建CBMs。我们发现了基于预训练模型构建的CBMs中存在的不良偏差,并提出了一种新颖的框架,旨在利用预训练模型,同时避免这些偏差,从而降低模型对虚假相关性的敏感性。具体而言,我们的方法提供了一个无缝的流程,采用基础模型来评估数据集中潜在的虚假相关性,为图像标注概念,并改进标注以提高鲁棒性。我们在多个数据集上评估了所提出的方法,结果表明该方法在降低模型对虚假相关性的依赖性的同时,保持了其可解释性。
🔬 方法详解
问题定义:现有的概念瓶颈模型(CBMs)虽然具有良好的可解释性,但其构建过程依赖于大量的人工标注,这使得其应用成本很高,并且难以扩展到大规模数据集。此外,直接使用预训练模型构建CBMs可能会引入预训练模型中存在的偏差,导致模型仍然容易受到虚假相关性的影响。
核心思路:该论文的核心思路是利用多个预训练的基础模型,协同完成概念标注和模型训练,从而在几乎不需要人工干预的情况下构建CBMs。同时,设计一种框架来避免预训练模型中存在的偏差,从而提高模型的鲁棒性,使其不易受到虚假相关性的影响。
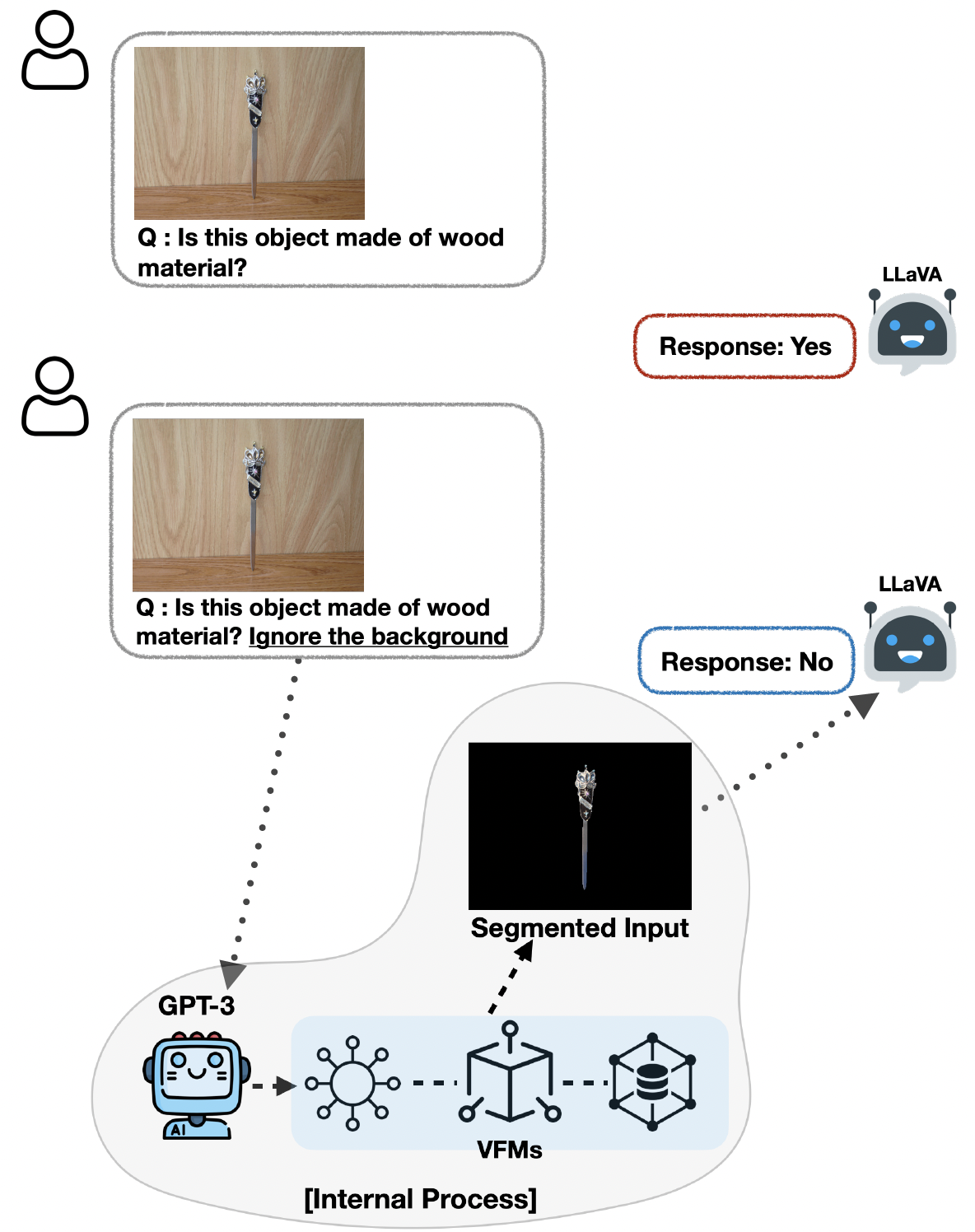
技术框架:该方法包含以下几个主要阶段:1) 利用预训练模型评估数据集中潜在的虚假相关性;2) 使用预训练模型为图像自动标注概念;3) 对自动标注的概念进行优化,以提高标注的准确性和鲁棒性;4) 使用标注后的数据训练概念瓶颈模型。整个流程无需人工干预,实现了自动化构建CBMs。
关键创新:该论文的关键创新在于提出了一种利用多个预训练模型协同构建CBMs的框架,该框架能够有效地降低人工标注成本,并且能够避免预训练模型中存在的偏差。与传统的CBMs构建方法相比,该方法更加高效、鲁棒,并且具有更好的可扩展性。
关键设计:论文中涉及的关键设计包括:如何选择合适的预训练模型来评估虚假相关性,如何设计损失函数来优化概念标注,以及如何设计网络结构来提高模型的鲁棒性。具体的参数设置和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
该论文在多个数据集上进行了实验,结果表明,所提出的方法能够有效地降低模型对虚假相关性的依赖,同时保持模型的可解释性。具体的性能提升数据和对比基线在论文中进行了详细展示(未知)。实验结果验证了该方法在构建鲁棒且可解释的模型方面的有效性。
🎯 应用场景
该研究成果可应用于各种需要模型可解释性和鲁棒性的领域,例如自动驾驶、医疗诊断、金融风控等。通过构建概念瓶颈模型,可以更好地理解模型的决策过程,从而提高模型的可靠性和安全性,并减少因虚假相关性导致的错误决策。未来,该方法可以进一步扩展到处理更复杂的数据和任务,例如视频理解、自然语言处理等。
📄 摘要(原文)
Enhancing model interpretability can address spurious correlations by revealing how models draw their predictions. Concept Bottleneck Models (CBMs) can provide a principled way of disclosing and guiding model behaviors through human-understandable concepts, albeit at a high cost of human efforts in data annotation. In this paper, we leverage a synergy of multiple foundation models to construct CBMs with nearly no human effort. We discover undesirable biases in CBMs built on pre-trained models and propose a novel framework designed to exploit pre-trained models while being immune to these biases, thereby reducing vulnerability to spurious correlations. Specifically, our method offers a seamless pipeline that adopts foundation models for assessing potential spurious correlations in datasets, annotating concepts for images, and refining the annotations for improved robustness. We evaluate the proposed method on multiple datasets, and the results demonstrate its effectiveness in reducing model reliance on spurious correlations while preserving its interpretability.