EfficientQAT: Efficient Quantization-Aware Training for Large Language Models
作者: Mengzhao Chen, Wenqi Shao, Peng Xu, Jiahao Wang, Peng Gao, Kaipeng Zhang, Ping Luo
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-07-10 (更新: 2025-05-19)
备注: ACL 2025 Main, camera ready version
🔗 代码/项目: GITHUB
💡 一句话要点
提出EfficientQAT,一种高效的大语言模型量化感知训练方法,显著降低训练资源需求。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 量化感知训练 大型语言模型 低比特量化 模型压缩 高效训练
📋 核心要点
- 现有量化感知训练(QAT)方法训练资源需求巨大,难以应用于大型语言模型(LLM)的低比特量化。
- EfficientQAT通过块状参数训练和量化参数端到端训练,在降低资源消耗的同时,保持量化模型的精度。
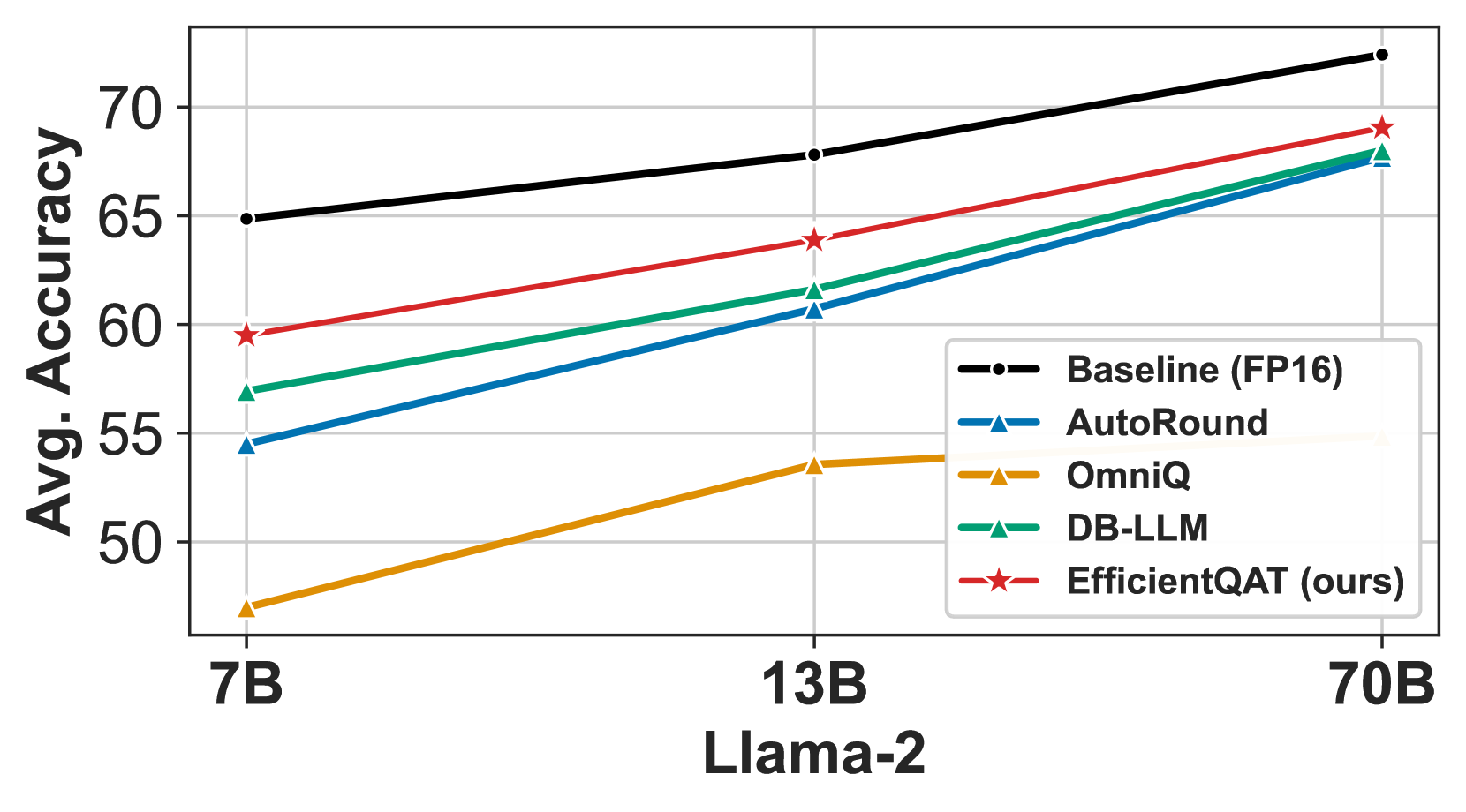
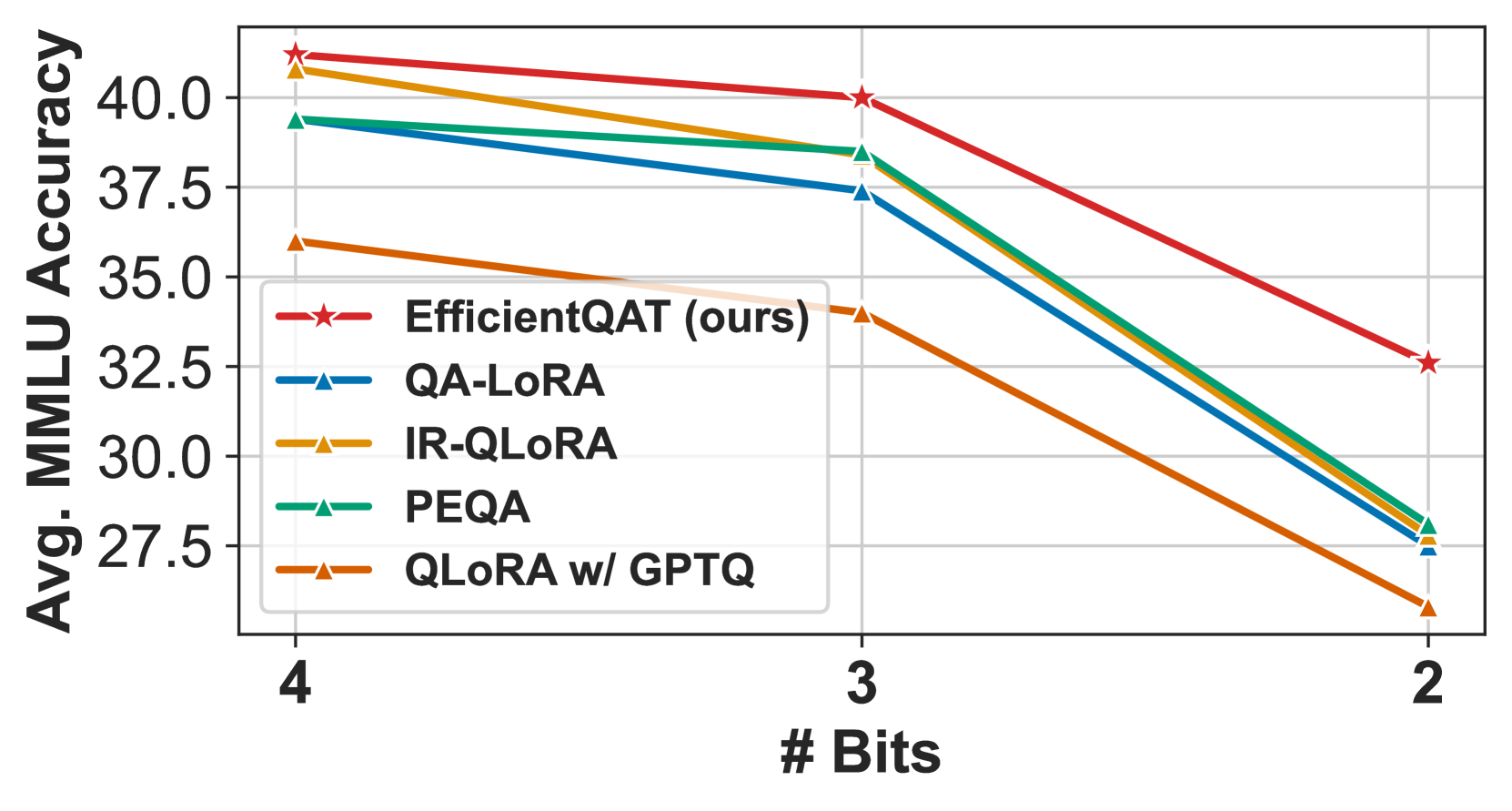
- 实验表明,EfficientQAT在多种LLM上优于现有量化方法,例如,2-bit Llama-2-70B模型精度损失小于3%。
📝 摘要(中文)
大型语言模型(LLM)在现代自然语言处理和人工智能中至关重要。然而,它们在管理大量内存需求方面面临挑战。量化感知训练(QAT)通过低比特表示减少内存消耗并最小化精度损失,提供了一种解决方案,但由于需要大量的训练资源,因此在实践中难以应用。为了解决这个问题,我们提出了一种更可行的QAT算法,即高效量化感知训练(EfficientQAT)。EfficientQAT包括两个连续的阶段:所有参数的块状训练(Block-AP)和量化参数的端到端训练(E2E-QP)。据我们所知,Block-AP是第一个能够以块状方式直接训练所有参数的方法,通过增强优化期间的解空间来减少低比特场景中的精度损失。然后,E2E-QP仅端到端地训练量化参数(步长),通过考虑所有子模块之间的交互来进一步提高量化模型的性能。大量的实验表明,EfficientQAT在各种模型上优于以前的量化方法,包括基础LLM、指令调优LLM和多模态LLM,规模从7B到70B参数,量化比特数各不相同。例如,EfficientQAT在单个A100-80GB GPU上以41小时获得了一个2比特的Llama-2-70B模型,与全精度相比,精度下降不到3个点(69.48 vs. 72.41)。
🔬 方法详解
问题定义:现有量化感知训练(QAT)方法在训练大型语言模型时,需要消耗大量的计算资源和内存,使得低比特量化在实际应用中面临挑战。传统的QAT方法通常需要对所有参数进行微调,这对于参数量巨大的LLM来说是不可行的。因此,如何在有限的资源下,实现LLM的低比特量化,同时保持较高的模型精度,是本论文要解决的核心问题。
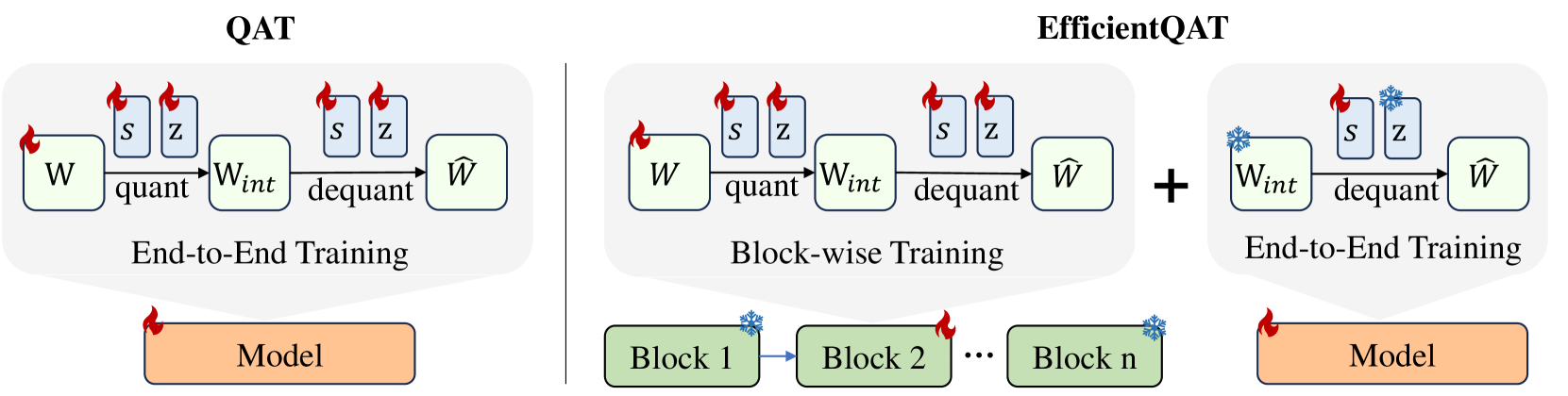
核心思路:EfficientQAT的核心思路是将QAT过程分解为两个阶段:首先,采用块状训练(Block-AP)的方式,对模型的所有参数进行训练,旨在扩大优化空间,减少低比特量化带来的精度损失。然后,固定模型权重,仅对量化参数(如量化步长)进行端到端训练(E2E-QP),以进一步提升量化模型的性能。这种两阶段的训练策略,可以在保证模型精度的前提下,显著降低训练所需的计算资源。
技术框架:EfficientQAT的整体框架包含两个主要阶段:Block-wise training of all parameters (Block-AP) 和 end-to-end training of quantization parameters (E2E-QP)。在Block-AP阶段,模型被划分为多个块,每个块内的参数被同时训练,而不同块之间的参数则交替训练。在E2E-QP阶段,模型权重被固定,仅对量化参数进行端到端训练,以优化量化模型的整体性能。
关键创新:EfficientQAT的关键创新在于Block-AP阶段的块状训练策略。与传统的QAT方法相比,Block-AP能够以更高效的方式探索更大的解空间,从而减少低比特量化带来的精度损失。此外,E2E-QP阶段的量化参数端到端训练,能够进一步优化量化模型的性能,使其更好地适应低比特表示。
关键设计:在Block-AP阶段,需要确定合适的块大小和训练策略。论文中可能采用了某种启发式方法或实验来确定最佳的块大小。在E2E-QP阶段,量化参数的初始化和优化算法的选择至关重要。论文可能采用了某种自适应的步长调整策略或特殊的优化器,以加速量化参数的收敛。
🖼️ 关键图片
📊 实验亮点
EfficientQAT在多种LLM上取得了显著的性能提升。例如,在Llama-2-70B模型上,使用2比特量化,EfficientQAT在单个A100-80GB GPU上仅用41小时就完成了训练,并且精度损失小于3个点(69.48 vs. 72.41)。该结果表明,EfficientQAT能够以较低的资源消耗,实现LLM的低比特量化,并保持较高的模型精度。
🎯 应用场景
EfficientQAT具有广泛的应用前景,可用于在资源受限的设备上部署大型语言模型,例如移动设备、嵌入式系统和边缘计算设备。通过降低LLM的内存占用和计算复杂度,EfficientQAT可以加速LLM在各个领域的应用,如智能助手、机器翻译、文本生成等。此外,该方法还可以应用于其他类型的深度学习模型,以实现更高效的模型压缩和加速。
📄 摘要(原文)
Large language models (LLMs) are crucial in modern natural language processing and artificial intelligence. However, they face challenges in managing their significant memory requirements. Although quantization-aware training (QAT) offers a solution by reducing memory consumption through low-bit representations with minimal accuracy loss, it is impractical due to substantial training resources. To address this, we propose Efficient Quantization-Aware Training (EfficientQAT), a more feasible QAT algorithm. EfficientQAT involves two consecutive phases: Block-wise training of all parameters (Block-AP) and end-to-end training of quantization parameters (E2E-QP). To the best of our knowledge, Block-AP is the first method to enable direct training of all parameters in a block-wise manner, reducing accuracy loss in low-bit scenarios by enhancing the solution space during optimization. E2E-QP then trains only the quantization parameters (step sizes) end-to-end, further improving the performance of quantized models by considering interactions among all sub-modules. Extensive experiments demonstrate that EfficientQAT outperforms previous quantization methods across a range of models, including base LLMs, instruction-tuned LLMs, and multimodal LLMs, with scales from 7B to 70B parameters at various quantization bits. For instance, EfficientQAT obtains a 2-bit Llama-2-70B model on a single A100-80GB GPU in 41 hours, with less than 3 points accuracy degradation compared to the full precision (69.48 vs. 72.41). Code is available at https://github.com/OpenGVLab/EfficientQAT.