OpenDiLoCo: An Open-Source Framework for Globally Distributed Low-Communication Training
作者: Sami Jaghouar, Jack Min Ong, Johannes Hagemann
分类: cs.LG, cs.DC
发布日期: 2024-07-10
💡 一句话要点
OpenDiLoCo:用于大规模语言模型训练的开源分布式低通信框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分布式训练 低通信 大规模语言模型 开源框架 梯度稀疏化
📋 核心要点
- 现有分布式训练方法在大规模模型训练中面临通信瓶颈,限制了训练效率和可扩展性。
- OpenDiLoCo通过分布式低通信训练,减少节点间的通信量,提高训练效率,并支持去中心化的训练环境。
- 实验表明,OpenDiLoCo在跨地域分布式环境中能保持高计算利用率,并可扩展到更大规模的模型。
📝 摘要(中文)
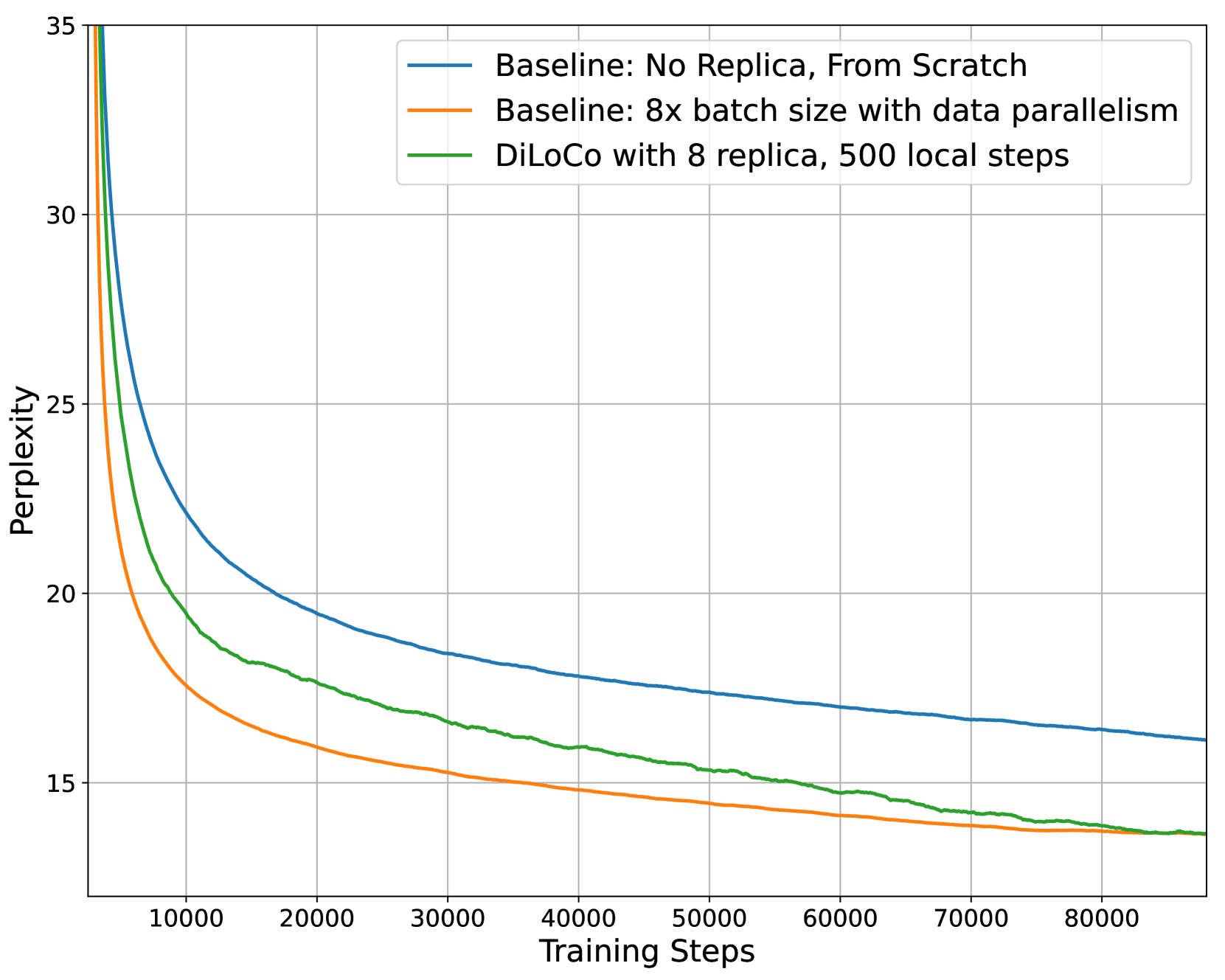
OpenDiLoCo是一个开源实现,复现了用于大型语言模型的分布式低通信(DiLoCo)训练方法。我们提供了一个可复现的DiLoCo实验实现,并将其置于一个使用Hivemind库的可扩展、去中心化的训练框架中。我们通过在两个大洲和三个国家训练模型来证明其有效性,同时保持90-95%的计算利用率。此外,我们进行了消融研究,重点关注算法的计算效率、工作节点的扩展性,并表明其梯度可以使用FP16进行all-reduce而不会降低性能。此外,我们将OpenDiLoCo扩展到原始工作规模的3倍,证明了其对数十亿参数模型的有效性。
🔬 方法详解
问题定义:论文旨在解决大规模语言模型分布式训练中通信开销过大的问题。传统的数据并行训练方法需要频繁地在所有worker节点之间同步梯度,这在大规模模型和分布式环境下会造成严重的通信瓶颈,降低训练效率,并且对网络带宽要求很高。
核心思路:OpenDiLoCo的核心思路是通过减少通信频率和通信量来缓解通信瓶颈。它采用了一种基于梯度累积和稀疏化的方法,使得worker节点可以在本地累积一定数量的梯度更新,然后只同步重要的梯度信息,从而降低通信开销。
技术框架:OpenDiLoCo基于Hivemind库构建,提供了一个可扩展的去中心化训练框架。整体流程包括:1) worker节点在本地进行模型训练,累积梯度;2) worker节点之间进行梯度稀疏化和选择,只保留重要的梯度信息;3) 使用All-Reduce算法同步选定的梯度;4) 使用同步后的梯度更新模型。
关键创新:OpenDiLoCo的关键创新在于其分布式低通信训练方法,该方法通过梯度累积和稀疏化显著减少了通信量。与传统的数据并行训练相比,它能够在保证模型性能的前提下,降低通信开销,提高训练效率,尤其是在带宽受限的分布式环境中。
关键设计:OpenDiLoCo的关键设计包括:1) 梯度累积的步数,决定了通信的频率;2) 梯度稀疏化的策略,例如选择幅度最大的梯度;3) 使用FP16进行梯度All-Reduce,进一步减少通信量;4) 基于Hivemind的去中心化架构,允许在异构和不可靠的网络环境中进行训练。
🖼️ 关键图片


📊 实验亮点
OpenDiLoCo在跨越两个大洲和三个国家的分布式环境中进行了实验,实现了90-95%的计算利用率。消融研究表明,该算法具有良好的计算效率和可扩展性。此外,使用FP16进行梯度All-Reduce没有导致性能下降。OpenDiLoCo还被扩展到原始工作规模的3倍,证明了其对数十亿参数模型的有效性。
🎯 应用场景
OpenDiLoCo适用于大规模语言模型的分布式训练,特别是在计算资源分散、网络带宽受限的环境中。它可以降低训练成本,加速模型迭代,并支持在更广泛的计算资源上进行训练。该框架的开源特性也促进了社区的协作和创新,加速了大型语言模型的发展。
📄 摘要(原文)
OpenDiLoCo is an open-source implementation and replication of the Distributed Low-Communication (DiLoCo) training method for large language models. We provide a reproducible implementation of the DiLoCo experiments, offering it within a scalable, decentralized training framework using the Hivemind library. We demonstrate its effectiveness by training a model across two continents and three countries, while maintaining 90-95% compute utilization. Additionally, we conduct ablations studies focusing on the algorithm's compute efficiency, scalability in the number of workers and show that its gradients can be all-reduced using FP16 without any performance degradation. Furthermore, we scale OpenDiLoCo to 3x the size of the original work, demonstrating its effectiveness for billion parameter models.