Fine-Tuning Large Language Models with User-Level Differential Privacy
作者: Zachary Charles, Arun Ganesh, Ryan McKenna, H. Brendan McMahan, Nicole Mitchell, Krishna Pillutla, Keith Rush
分类: cs.LG, cs.CL, cs.CR, cs.DC
发布日期: 2024-07-10
💡 一句话要点
提出用户级差分隐私LLM微调算法,保障用户数据安全。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 差分隐私 大型语言模型 用户级隐私 DP-SGD 隐私保护 模型微调 用户级采样 示例级采样
📋 核心要点
- 现有差分隐私训练方法在大型语言模型微调中面临挑战,尤其是在用户级别隐私保护方面。
- 论文提出用户级采样(ULS)和示例级采样(ELS)两种DP-SGD变体,并设计了新的用户级DP核算器。
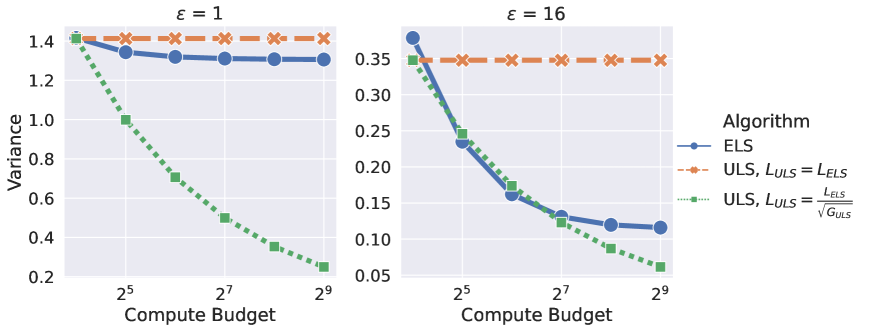
- 实验表明,ULS在强隐私保证或高计算预算下优于ELS,适用于大规模LLM和数据集。
📝 摘要(中文)
本文研究了在用户级别差分隐私(DP)下训练大型语言模型(LLM)的实用且可扩展的算法,旨在可靠地保护每个用户贡献的所有样本。我们研究了DP-SGD的两种变体:(1)示例级采样(ELS)和逐示例梯度裁剪,以及(2)用户级采样(ULS)和逐用户梯度裁剪。我们推导了一种新颖的用户级DP核算器,可以为ELS计算出可靠的严格隐私保证。基于此,我们表明,虽然ELS在特定设置中可以优于ULS,但当每个用户拥有多样化的示例集合时,ULS通常会产生更好的结果。我们通过在固定计算预算下的合成均值估计和LLM微调任务中的实验验证了我们的发现。我们发现,在需要强隐私保证或计算预算较大时,ULS明显更好。值得注意的是,我们专注于与LLM兼容的训练算法,这使我们能够扩展到具有数亿参数的模型和数十万用户的数百万数据集。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)微调过程中用户级别差分隐私(DP)的保护问题。现有方法在用户数据量差异大、计算资源有限的情况下,难以保证隐私性和模型性能的平衡。痛点在于如何在保护用户数据隐私的同时,高效地训练出高性能的LLM。
核心思路:论文的核心思路是探索两种不同的DP-SGD变体:示例级采样(ELS)和用户级采样(ULS),并针对ELS提出一种新的用户级DP核算器,以更准确地评估隐私损失。通过比较两种采样策略在不同场景下的性能,找到更适合LLM微调的用户级DP训练方法。核心在于利用用户级采样,减少因单个用户数据量过大而导致的隐私泄露风险。
技术框架:整体框架基于DP-SGD算法,包含以下主要模块:数据采样(ELS或ULS)、梯度裁剪(逐示例或逐用户)、噪声添加和模型更新。ELS对每个样本进行采样,并对每个样本的梯度进行裁剪;ULS对每个用户进行采样,并对每个用户的梯度进行裁剪。两种方法都添加高斯噪声以满足差分隐私的要求。关键在于新提出的用户级DP核算器,用于更精确地计算ELS的隐私损失。
关键创新:最重要的技术创新点在于提出了针对ELS的用户级DP核算器。传统的DP核算方法可能过于保守,导致不必要的性能损失。新的核算器能够更准确地评估ELS的隐私损失,从而在满足相同隐私保证的前提下,允许更大的模型更新幅度,提高模型性能。与现有方法的本质区别在于,它提供了一种更精确的隐私分析工具,使得ELS在某些场景下也能达到与ULS相当甚至更好的性能。
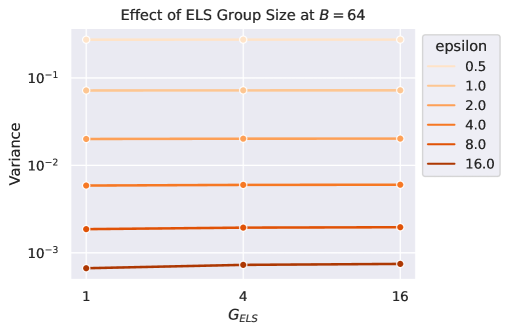
关键设计:关键设计包括:1) 两种采样策略(ELS和ULS)的具体实现方式,包括采样概率的设置;2) 梯度裁剪的阈值选择,需要在保护隐私和保留梯度信息之间进行权衡;3) 高斯噪声的方差设置,直接影响隐私保护的强度和模型性能;4) 新的用户级DP核算器的数学推导和实现,需要保证其准确性和高效性。论文中可能还涉及特定LLM的结构和训练参数设置,但摘要中未明确提及。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在强隐私保证或高计算预算下,用户级采样(ULS)明显优于示例级采样(ELS)。特别是在用户数据多样性较高的情况下,ULS能够更好地平衡隐私保护和模型性能。虽然摘要中没有给出具体的性能数据和提升幅度,但强调了ULS在特定场景下的显著优势,以及该方法能够扩展到具有数亿参数的模型和数十万用户的数据集。
🎯 应用场景
该研究成果可应用于各种需要保护用户数据隐私的大型语言模型微调场景,例如个性化推荐、医疗诊断、金融风控等。通过使用用户级差分隐私技术,可以在保证用户数据安全的前提下,训练出高性能的LLM,从而促进人工智能技术在敏感领域的应用和发展。未来,该技术有望推广到其他类型的机器学习模型和数据集中。
📄 摘要(原文)
We investigate practical and scalable algorithms for training large language models (LLMs) with user-level differential privacy (DP) in order to provably safeguard all the examples contributed by each user. We study two variants of DP-SGD with: (1) example-level sampling (ELS) and per-example gradient clipping, and (2) user-level sampling (ULS) and per-user gradient clipping. We derive a novel user-level DP accountant that allows us to compute provably tight privacy guarantees for ELS. Using this, we show that while ELS can outperform ULS in specific settings, ULS generally yields better results when each user has a diverse collection of examples. We validate our findings through experiments in synthetic mean estimation and LLM fine-tuning tasks under fixed compute budgets. We find that ULS is significantly better in settings where either (1) strong privacy guarantees are required, or (2) the compute budget is large. Notably, our focus on LLM-compatible training algorithms allows us to scale to models with hundreds of millions of parameters and datasets with hundreds of thousands of users.