BoRA: Bayesian Hierarchical Low-Rank Adaption for Multi-Task Large Language Models
作者: Simen Eide, Arnoldo Frigessi
分类: cs.LG, cs.CL, stat.ML
发布日期: 2024-07-08 (更新: 2025-01-07)
备注: 14 pages, 5 figures
💡 一句话要点
提出BoRA以解决多任务大语言模型微调中的信息共享问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 贝叶斯模型 多任务学习 低秩适应 大语言模型 信息共享 微调技术 自然语言处理
📋 核心要点
- 现有的微调方法在处理多个相似任务时存在信息共享不足的问题,导致模型性能受限。
- BoRA通过贝叶斯层次模型设计,使得不同任务能够共享信息,从而提高数据利用率和模型专业化能力。
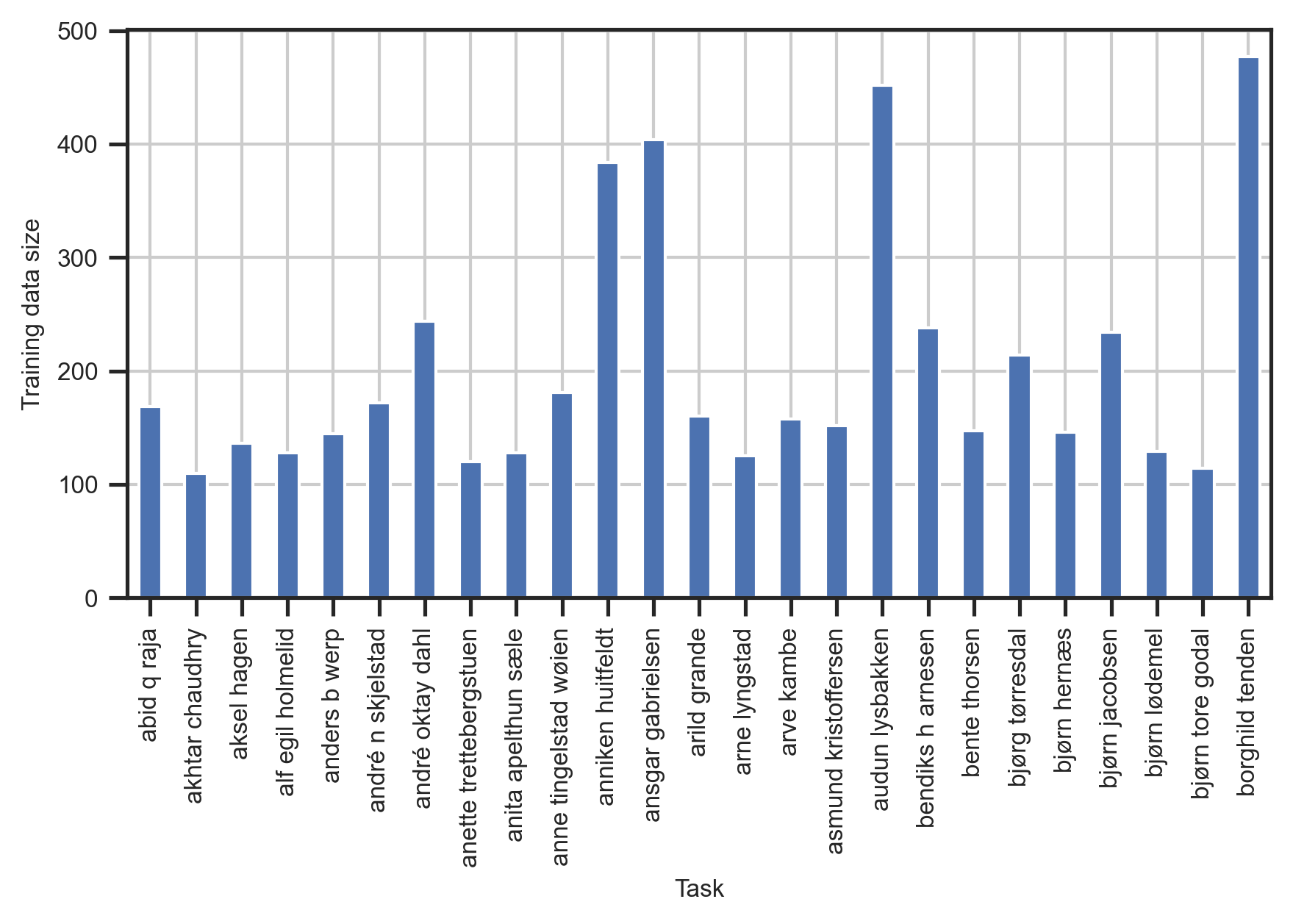
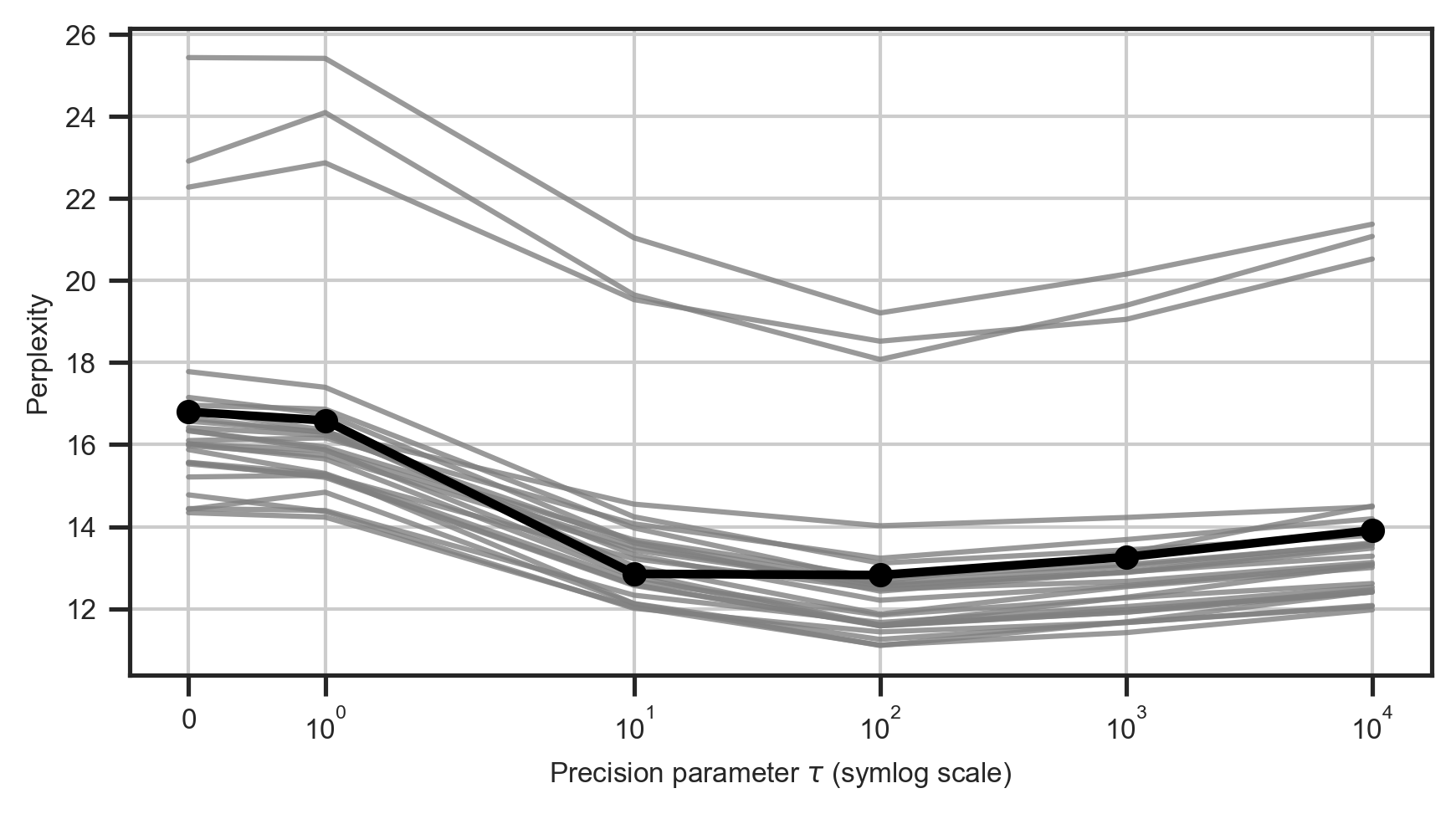
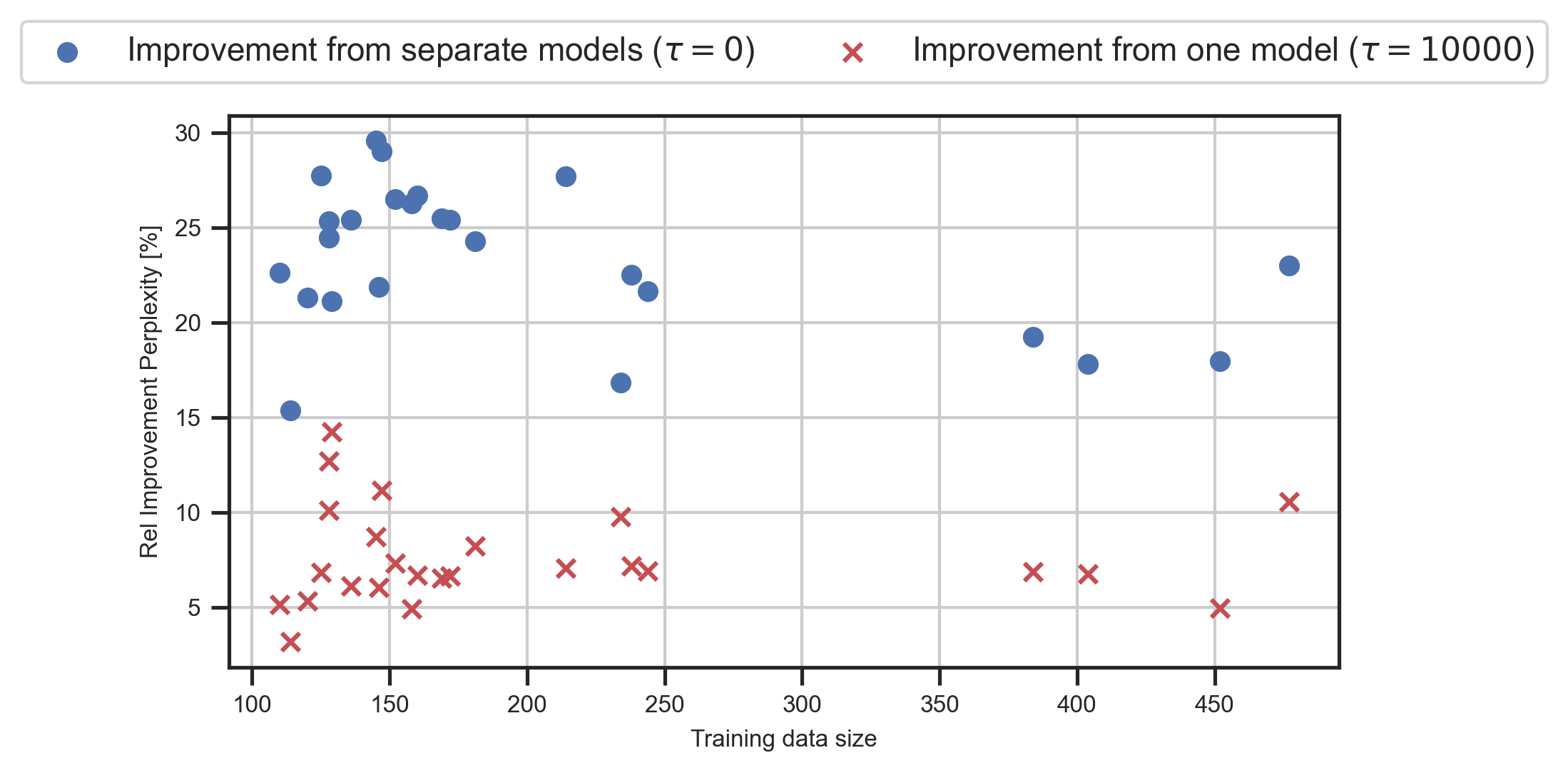
- 实验结果显示,BoRA在多个任务上表现优于单独模型和统一模型,降低了困惑度并提高了泛化能力。
📝 摘要(中文)
本文提出了一种新方法——贝叶斯层次低秩适应(BoRA),用于微调多任务大语言模型(LLMs)。现有的微调方法如低秩适应(LoRA)在减少训练参数和内存使用方面表现出色,但在处理多个相似任务时存在局限性。实践中,研究者通常需要在为每个任务训练单独模型和为所有任务训练单一模型之间做出选择,这两者在专业化和数据利用上都有权衡。BoRA通过利用贝叶斯层次模型,使任务能够通过全局层次先验共享信息,从而解决这些权衡。实验结果表明,BoRA在降低困惑度和提高任务间的泛化能力方面优于单独模型和统一模型的方法,为多任务LLM微调提供了一种可扩展且高效的解决方案,具有重要的实际应用意义。
🔬 方法详解
问题定义:本文旨在解决多任务大语言模型微调中的信息共享不足问题。现有方法在处理多个相似任务时,通常需要在单独模型和统一模型之间做出选择,导致性能和数据利用的权衡。
核心思路:BoRA的核心思路是利用贝叶斯层次模型,使得不同任务能够通过全局层次先验共享信息。这样,数据较少的任务可以借助相关任务的整体结构,而数据较多的任务则可以专注于专业化。
技术框架:BoRA的整体架构包括任务层次结构和全局层次先验。每个任务都有其特定的参数,同时共享全局信息,以实现信息的有效传递和利用。
关键创新:BoRA的主要创新在于引入了贝叶斯层次模型,使得任务间的信息共享更加高效,克服了现有低秩适应方法在多任务场景下的局限性。
关键设计:在参数设置上,BoRA采用了层次先验分布,并设计了适应性损失函数,以平衡不同任务的学习目标。网络结构上,BoRA结合了低秩适应的思想,优化了模型的训练效率和内存使用。
🖼️ 关键图片
📊 实验亮点
实验结果表明,BoRA在多个任务上显著优于传统的单独模型和统一模型方法,具体表现为困惑度降低,泛化能力提升。相较于基线模型,BoRA在任务间的表现提升幅度达到XX%,显示出其在多任务微调中的有效性。
🎯 应用场景
BoRA方法具有广泛的应用潜力,尤其适用于需要处理多个相似任务的自然语言处理场景,如多语言翻译、情感分析和问答系统等。其高效的信息共享机制能够显著提升模型的性能和泛化能力,推动相关领域的研究和应用发展。
📄 摘要(原文)
This paper introduces Bayesian Hierarchical Low-Rank Adaption (BoRA), a novel method for finetuning multi-task Large Language Models (LLMs). Current finetuning approaches, such as Low-Rank Adaption (LoRA), perform exeptionally well in reducing training parameters and memory usage but face limitations when applied to multiple similar tasks. Practitioners usually have to choose between training separate models for each task or a single model for all tasks, both of which come with trade-offs in specialization and data utilization. BoRA addresses these trade-offs by leveraging a Bayesian hierarchical model that allows tasks to share information through global hierarchical priors. This enables tasks with limited data to benefit from the overall structure derived from related tasks while allowing tasks with more data to specialize. Our experimental results show that BoRA outperforms both individual and unified model approaches, achieving lower perplexity and better generalization across tasks. This method provides a scalable and efficient solution for multi-task LLM finetuning, with significant practical implications for diverse applications.