A Survey on LoRA of Large Language Models
作者: Yuren Mao, Yuhang Ge, Yijiang Fan, Wenyi Xu, Yu Mi, Zhonghao Hu, Yunjun Gao
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-07-08 (更新: 2024-10-24)
备注: The article has been accepted by Frontiers of Computer Science (FCS), with the DOI: {10.1007/s11704-024-40663-9}
DOI: 10.1007/s11704-024-40663-9
🔗 代码/项目: GITHUB
💡 一句话要点
LoRA综述:对大语言模型低秩适应微调方法进行全面梳理与分析
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低秩适应 参数高效微调 大语言模型 跨任务泛化 联邦学习 自然语言处理 模型微调
📋 核心要点
- 现有大语言模型微调方法参数量巨大,计算成本高昂,限制了其在资源受限场景下的应用。
- LoRA通过引入低秩矩阵来更新模型参数,显著减少了需要训练的参数量,降低了计算成本。
- 该综述全面回顾了LoRA在下游任务适应、跨任务泛化、效率提升、隐私保护和应用等方面的研究进展。
📝 摘要(中文)
低秩适应(LoRA)是一种参数高效的微调范式,它通过可插拔的低秩矩阵更新稠密神经网络层。LoRA在跨任务泛化和保护隐私方面具有显著优势。因此,LoRA最近受到了广泛关注,相关文献数量呈指数增长。本文对LoRA的最新进展进行了全面的概述,从以下几个角度对进展进行分类和回顾:(1)改进下游任务适应性的变体;(2)混合多个LoRA插件以实现跨任务泛化的方法;(3)提高LoRA计算效率的方法;(4)在联邦学习中使用LoRA的数据隐私保护方法;(5)应用。此外,本文还讨论了该领域的未来发展方向。最后,我们提供了一个Github页面,供读者查看更新并就本文发起讨论。
🔬 方法详解
问题定义:现有的大型语言模型微调方法通常需要更新所有模型参数,这导致了巨大的计算和存储开销,尤其是在资源受限的环境中。此外,针对不同任务进行微调的模型难以实现跨任务的泛化能力。
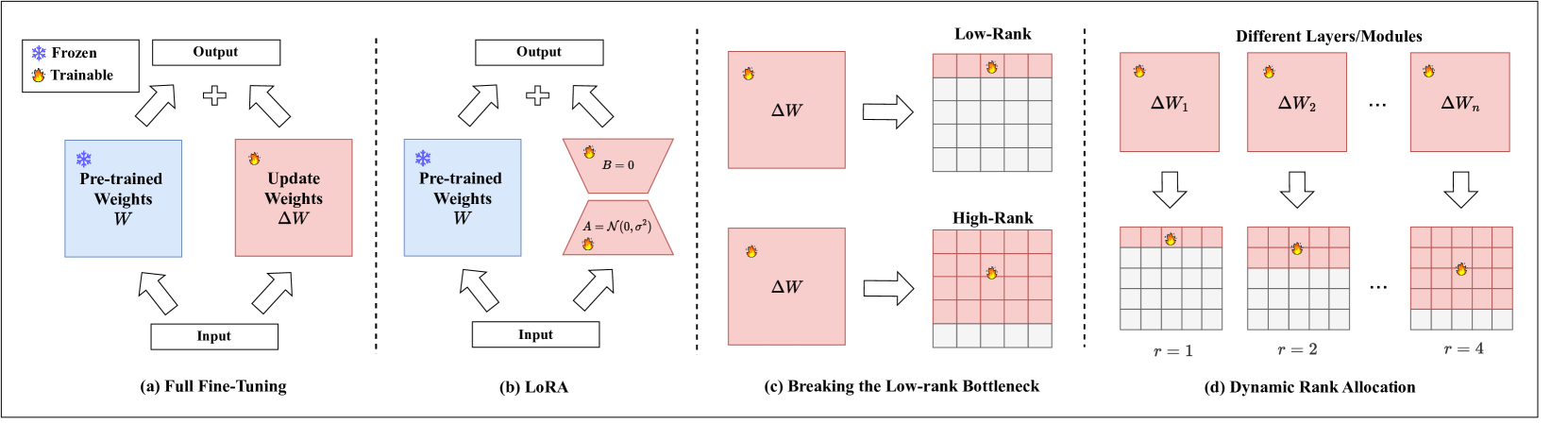
核心思路:LoRA的核心思想是通过引入低秩矩阵来近似模型参数的更新。具体来说,LoRA冻结预训练模型的原始权重,并引入两个低秩矩阵来表示权重更新。这样,只需要训练这些低秩矩阵,而无需更新整个模型,从而大大减少了需要训练的参数量。
技术框架:LoRA的整体框架包括以下几个步骤:首先,选择需要进行微调的预训练模型层。然后,对于每一层,引入两个低秩矩阵A和B,它们的维度分别为r x d和d x r,其中r是秩,d是原始权重的维度。在训练过程中,只更新A和B,而原始权重保持不变。推理时,将A和B的乘积加到原始权重上。
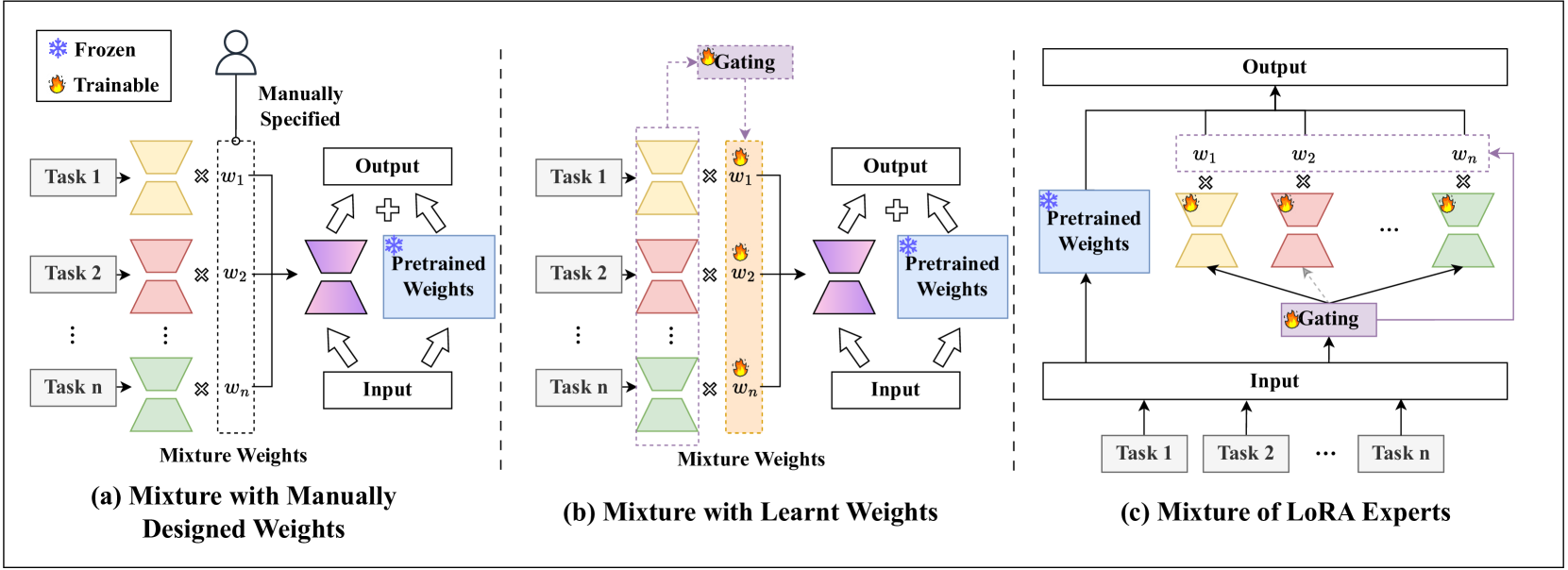
关键创新:LoRA最重要的创新点在于其参数高效性。通过使用低秩矩阵来表示权重更新,LoRA显著减少了需要训练的参数量,从而降低了计算和存储成本。此外,LoRA还具有良好的跨任务泛化能力,可以通过混合多个LoRA插件来实现。
关键设计:LoRA的关键设计包括秩r的选择、需要微调的层选择以及训练策略。秩r的选择需要在参数效率和性能之间进行权衡。需要微调的层通常是Transformer模型的注意力层和MLP层。训练策略包括学习率、优化器和正则化方法等。
🖼️ 关键图片

📊 实验亮点
该综述总结了LoRA在各种下游任务上的性能表现,并与全参数微调等基线方法进行了比较。实验结果表明,LoRA在保持甚至提高性能的同时,显著减少了需要训练的参数量,例如,在某些任务上,LoRA仅需微调少量参数即可达到与全参数微调相当的性能。
🎯 应用场景
LoRA在自然语言处理领域具有广泛的应用前景,包括文本分类、情感分析、机器翻译、文本生成等。它特别适用于资源受限的场景,例如移动设备和边缘计算。此外,LoRA还可以应用于联邦学习,以保护用户数据的隐私。
📄 摘要(原文)
Low-Rank Adaptation~(LoRA), which updates the dense neural network layers with pluggable low-rank matrices, is one of the best performed parameter efficient fine-tuning paradigms. Furthermore, it has significant advantages in cross-task generalization and privacy-preserving. Hence, LoRA has gained much attention recently, and the number of related literature demonstrates exponential growth. It is necessary to conduct a comprehensive overview of the current progress on LoRA. This survey categorizes and reviews the progress from the perspectives of (1) downstream adaptation improving variants that improve LoRA's performance on downstream tasks; (2) cross-task generalization methods that mix multiple LoRA plugins to achieve cross-task generalization; (3) efficiency-improving methods that boost the computation-efficiency of LoRA; (4) data privacy-preserving methods that use LoRA in federated learning; (5) application. Besides, this survey also discusses the future directions in this field. At last, we provide a Github page~\footnote{\href{https://github.com/ZJU-LLMs/Awesome-LoRAs.git}{https://github.com/ZJU-LLMs/Awesome-LoRAs.git}} for readers to check the updates and initiate discussions on this survey paper.