Explorative Imitation Learning: A Path Signature Approach for Continuous Environments
作者: Nathan Gavenski, Juarez Monteiro, Felipe Meneguzzi, Michael Luck, Odinaldo Rodrigues
分类: cs.LG, cs.AI
发布日期: 2024-07-05 (更新: 2024-07-22)
备注: This paper has been accepted in the 27th European Conference on Artificial Intelligence (ECAI) 2024
💡 一句话要点
提出基于路径签名和探索的模仿学习方法CILO,用于连续控制环境。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模仿学习 连续控制 路径签名 探索 行为克隆
📋 核心要点
- 现有模仿学习方法依赖大量专家轨迹以提高泛化性,且需人工干预以捕捉领域约束等关键问题。
- CILO通过引入探索机制,鼓励多样化的状态转移,减少对专家轨迹的依赖,并降低训练迭代次数。
- CILO利用路径签名自动编码约束,创建智能体和专家轨迹的非参数表示,无需人工特征工程。
📝 摘要(中文)
本文提出了一种名为“基于观测的连续模仿学习”(CILO)的新方法,该方法通过结合行为克隆和自监督,从状态对中推断动作。CILO增强了模仿学习,具有两个重要特征:(i)探索,允许更多样化的状态转换,减少对专家轨迹的依赖,并减少训练迭代次数;(ii)路径签名,通过创建智能体和专家轨迹的非参数表示,自动编码约束。在五个环境中,我们将CILO与基线和两种领先的模仿学习方法进行了比较。结果表明,CILO在所有环境中都具有最佳的整体性能,并且在其中两个环境中优于专家。
🔬 方法详解
问题定义:现有的模仿学习方法在连续控制环境中,通常需要大量的专家轨迹才能获得较好的泛化性能。此外,对于一些具有复杂约束的环境,需要人工设计特征来表示这些约束,增加了算法的复杂性和对领域知识的依赖。因此,如何减少对专家轨迹的依赖,并自动学习环境中的约束,是本文要解决的问题。
核心思路:本文的核心思路是将探索机制和路径签名相结合,以提高模仿学习的效率和泛化能力。通过探索,智能体可以访问更多样化的状态,从而减少对专家轨迹的依赖。通过路径签名,可以自动编码环境中的约束,无需人工干预。
技术框架:CILO的整体框架包括以下几个主要模块:1)探索模块:通过某种策略(例如,添加噪声)来鼓励智能体探索环境。2)行为克隆模块:使用专家轨迹来训练一个初始策略。3)自监督模块:使用智能体自身的轨迹来进一步训练策略。4)路径签名模块:使用路径签名来表示智能体和专家轨迹,并将其作为策略的输入。
关键创新:CILO的关键创新在于将探索机制和路径签名相结合。探索机制可以提高智能体的探索能力,减少对专家轨迹的依赖。路径签名可以自动编码环境中的约束,无需人工干预。这种结合使得CILO在连续控制环境中具有更好的性能和泛化能力。
关键设计:在探索模块中,可以使用不同的探索策略,例如,添加高斯噪声到动作空间。在路径签名模块中,需要选择合适的路径签名阶数。损失函数通常包括行为克隆损失和自监督损失。网络结构可以采用常见的神经网络结构,例如,多层感知机或循环神经网络。
🖼️ 关键图片
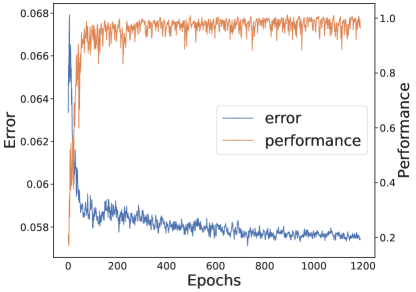
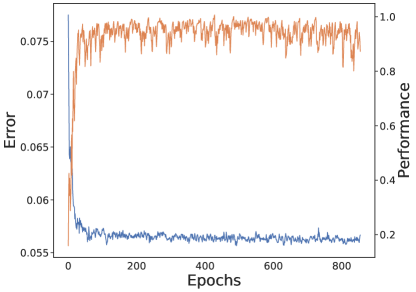
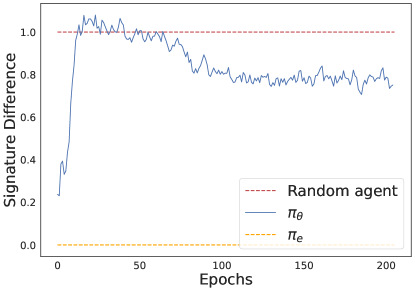
📊 实验亮点
CILO在五个不同的连续控制环境中进行了评估,包括Pendulum、MountainCarContinuous等。实验结果表明,CILO在所有环境中都取得了最佳的整体性能,并且在其中两个环境中甚至超过了专家。这表明CILO具有很强的模仿学习能力和泛化能力。
🎯 应用场景
CILO可应用于机器人控制、自动驾驶、游戏AI等领域。在机器人控制中,可以利用少量的人工示教数据,训练机器人完成复杂的任务。在自动驾驶中,可以利用少量的专家驾驶数据,训练自动驾驶系统,并自动学习交通规则等约束。在游戏AI中,可以利用少量的玩家操作数据,训练游戏AI,使其具有更高的智能和适应性。
📄 摘要(原文)
Some imitation learning methods combine behavioural cloning with self-supervision to infer actions from state pairs. However, most rely on a large number of expert trajectories to increase generalisation and human intervention to capture key aspects of the problem, such as domain constraints. In this paper, we propose Continuous Imitation Learning from Observation (CILO), a new method augmenting imitation learning with two important features: (i) exploration, allowing for more diverse state transitions, requiring less expert trajectories and resulting in fewer training iterations; and (ii) path signatures, allowing for automatic encoding of constraints, through the creation of non-parametric representations of agents and expert trajectories. We compared CILO with a baseline and two leading imitation learning methods in five environments. It had the best overall performance of all methods in all environments, outperforming the expert in two of them.