Simplifying Deep Temporal Difference Learning
作者: Matteo Gallici, Mattie Fellows, Benjamin Ellis, Bartomeu Pou, Ivan Masmitja, Jakob Nicolaus Foerster, Mario Martin
分类: cs.LG
发布日期: 2024-07-05 (更新: 2025-04-21)
💡 一句话要点
提出PQN:一种简化的深度在线Q学习算法,无需目标网络和经验回放,且性能优异。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度Q学习 强化学习 在线学习 正则化 无目标网络 无经验回放 时序差分学习 向量化环境
📋 核心要点
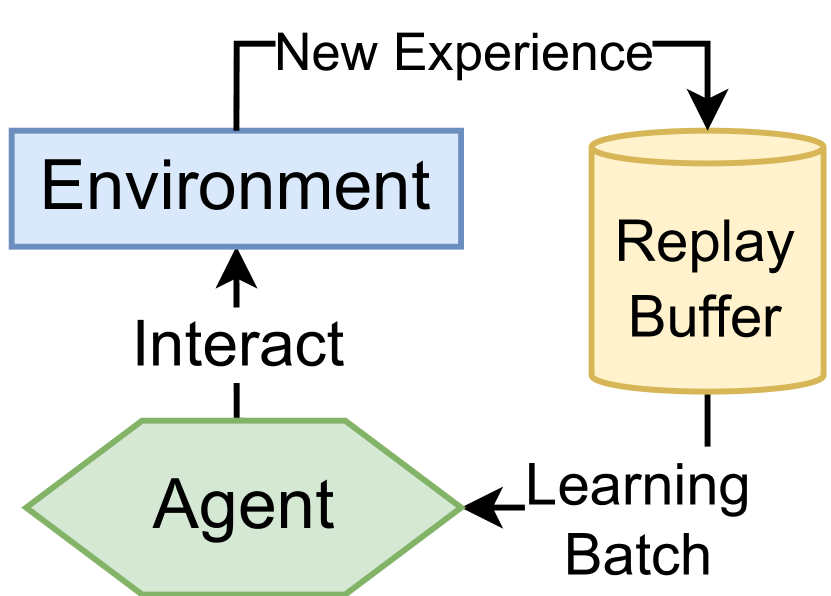
- 传统深度Q学习依赖目标网络和经验回放来稳定训练,但这些机制降低了样本效率并增加了内存开销。
- 论文提出PQN算法,利用LayerNorm等正则化技术和在线并行采样,无需目标网络和经验回放即可实现稳定训练。
- 实验表明,PQN在多个任务中与复杂算法相比具有竞争力,且训练速度更快,证明了简化离策略Q学习的可行性。
📝 摘要(中文)
Q学习是强化学习(RL)领域的基础。然而,诸如Q学习等使用离策略数据的时序差分(TD)算法,或像深度神经网络这样的非线性函数逼近,需要一些额外的技巧来稳定训练,主要是大型回放缓冲区和目标网络。不幸的是,目标网络中冻结网络参数的延迟更新会损害样本效率,类似地,大型回放缓冲区会引入内存和实现开销。在本文中,我们研究了是否有可能在保持其稳定性的同时加速和简化离策略TD训练。我们的关键理论结果首次证明,诸如LayerNorm等正则化技术可以产生可证明收敛的TD算法,而无需目标网络或回放缓冲区,即使使用离策略数据。在经验上,我们发现由向量化环境实现的在线并行采样可以在不需要大型回放缓冲区的情况下稳定训练。受这些发现的启发,我们提出了PQN,我们简化的深度在线Q学习算法。令人惊讶的是,这种简单的算法与更复杂的方法相比具有竞争力,例如:Atari中的Rainbow,Craftax中的PPO-RNN,Smax中的QMix,并且在不牺牲样本效率的情况下,比传统的DQN快50倍。在一个PPO已成为首选RL算法的时代,PQN重新确立了离策略Q学习作为一种可行的替代方案。
🔬 方法详解
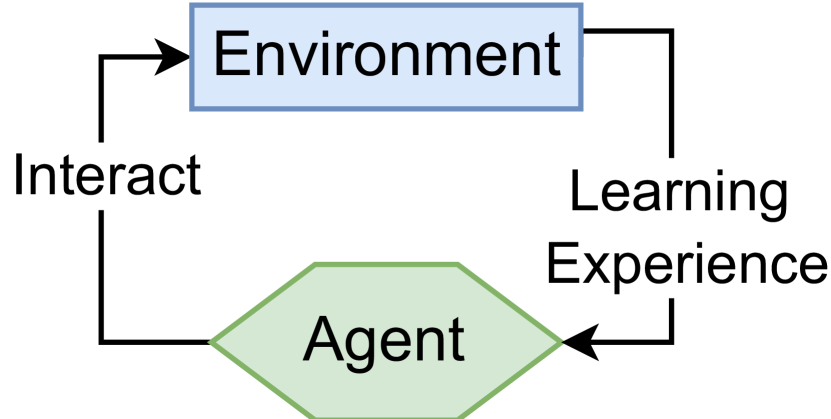
问题定义:传统深度Q学习算法,如DQN,为了解决训练不稳定问题,通常需要使用目标网络和经验回放机制。目标网络通过延迟更新来稳定目标值,但降低了样本利用率。经验回放则需要大量的内存空间,并且引入了采样偏差。因此,如何在不牺牲稳定性的前提下,简化深度Q学习算法,提高样本效率和降低内存开销,是本文要解决的问题。
核心思路:论文的核心思路是利用LayerNorm等正则化技术来稳定训练过程,从而消除对目标网络的需求。同时,通过在线并行采样,利用向量化环境来稳定训练,从而消除对经验回放的需求。这种方法旨在简化算法结构,提高训练效率,并降低内存开销。
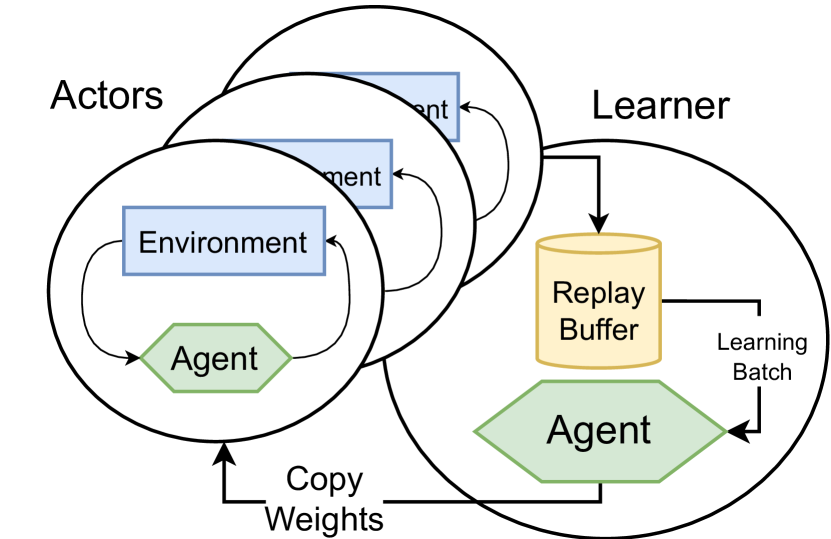
技术框架:PQN算法的整体框架如下:1. 使用向量化环境进行在线并行采样,获得经验数据。2. 使用深度神经网络作为Q函数逼近器,并采用LayerNorm等正则化技术。3. 使用时序差分(TD)学习更新Q函数参数,无需目标网络。4. 重复上述步骤进行训练,直到收敛。
关键创新:论文最重要的技术创新点在于证明了正则化技术(如LayerNorm)可以保证TD算法的收敛性,即使在没有目标网络和经验回放的情况下。这打破了传统深度Q学习对目标网络和经验回放的依赖,为简化算法结构提供了理论基础。
关键设计:PQN算法的关键设计包括:1. 使用LayerNorm来规范化Q函数的输出,从而稳定训练过程。2. 使用向量化环境进行在线并行采样,提高样本利用率。3. 使用Adam优化器更新Q函数参数。4. 损失函数采用传统的TD误差,但无需目标网络计算目标值。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PQN算法在Atari游戏中与Rainbow算法具有竞争力,在Craftax游戏中与PPO-RNN算法相当,在Smax游戏中与QMix算法相当。更重要的是,PQN算法的训练速度比传统DQN算法快50倍,且无需牺牲样本效率,证明了其优越的性能。
🎯 应用场景
PQN算法可应用于各种强化学习任务,尤其适用于资源受限或需要快速训练的场景,例如机器人控制、游戏AI和推荐系统。该算法的简化结构和高效训练使其更容易部署和应用,并有望推动强化学习在实际问题中的应用。
📄 摘要(原文)
Q-learning played a foundational role in the field reinforcement learning (RL). However, TD algorithms with off-policy data, such as Q-learning, or nonlinear function approximation like deep neural networks require several additional tricks to stabilise training, primarily a large replay buffer and target networks. Unfortunately, the delayed updating of frozen network parameters in the target network harms the sample efficiency and, similarly, the large replay buffer introduces memory and implementation overheads. In this paper, we investigate whether it is possible to accelerate and simplify off-policy TD training while maintaining its stability. Our key theoretical result demonstrates for the first time that regularisation techniques such as LayerNorm can yield provably convergent TD algorithms without the need for a target network or replay buffer, even with off-policy data. Empirically, we find that online, parallelised sampling enabled by vectorised environments stabilises training without the need for a large replay buffer. Motivated by these findings, we propose PQN, our simplified deep online Q-Learning algorithm. Surprisingly, this simple algorithm is competitive with more complex methods like: Rainbow in Atari, PPO-RNN in Craftax, QMix in Smax, and can be up to 50x faster than traditional DQN without sacrificing sample efficiency. In an era where PPO has become the go-to RL algorithm, PQN reestablishes off-policy Q-learning as a viable alternative.