SpikeLLM: Scaling up Spiking Neural Network to Large Language Models via Saliency-based Spiking
作者: Xingrun Xing, Boyan Gao, Zheng Zhang, David A. Clifton, Shitao Xiao, Li Du, Guoqi Li, Jiajun Zhang
分类: cs.LG, cs.CL, cs.NE
发布日期: 2024-07-05 (更新: 2025-04-10)
💡 一句话要点
提出SpikeLLM,通过基于显著性的脉冲神经网络扩展到大型语言模型,实现高效推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 脉冲神经网络 大型语言模型 神经形态计算 低功耗推理 量化 显著性 广义积分-发放神经元
📋 核心要点
- 大型语言模型推理需要大量算力与能耗,而人脑在相似参数规模下能耗更低,因此需要探索更高效的LLM实现方式。
- SpikeLLM通过引入脉冲神经网络机制,并结合广义积分-发放神经元和最优大脑脉冲框架,压缩脉冲长度,提升训练效率。
- 实验表明,SpikeLLM在OmniQuant和GPTQ流程中均优于现有量化方法,降低了困惑度并提高了推理准确率。
📝 摘要(中文)
大型语言模型(LLMs)在各种应用中表现出色,但其推理过程需要大量的能源和计算资源。受人脑的启发,论文重新设计了参数量在70亿到700亿之间的LLMs,使用生物可信的脉冲机制,模拟人脑的高效行为。论文提出了第一个脉冲大型语言模型,SpikeLLM。为了提高脉冲训练效率,提出了两种关键方法:广义积分-发放(GIF)神经元,将脉冲长度从T压缩到$\frac{T}{L} \log_2 L$ 比特;以及最优大脑脉冲框架,用于划分异常通道并为GIF神经元分配不同的T值,从而进一步将脉冲长度压缩到近似$\log_2T$ 比特。通过与具有类似运算的量化LLM进行比较,证明了脉冲驱动LLM的必要性。在OmniQuant流程中,SpikeLLM降低了11.01%的WikiText2困惑度,并在LLAMA-7B W4A4模型上提高了2.55%的常见场景推理准确率。在GPTQ流程中,SpikeLLM实现了线性层中的直接加性,显著超过了PB-LLMs。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)虽然在各种任务中取得了显著的性能,但其推理过程需要消耗大量的计算资源和能量。这限制了它们在资源受限环境中的部署和应用。现有的量化方法虽然可以降低计算成本,但仍然存在精度损失和硬件加速的挑战。因此,如何设计一种既能保持LLM性能,又能显著降低计算和能量消耗的模型是一个关键问题。
核心思路:论文的核心思路是借鉴人脑的神经脉冲机制,构建基于脉冲神经网络(SNN)的大型语言模型SpikeLLM。SNN具有事件驱动和稀疏激活的特性,理论上可以实现比传统ANN更低的功耗。通过将LLM中的计算转换为脉冲信号的处理,并结合优化的脉冲编码和训练方法,旨在实现高效的LLM推理。
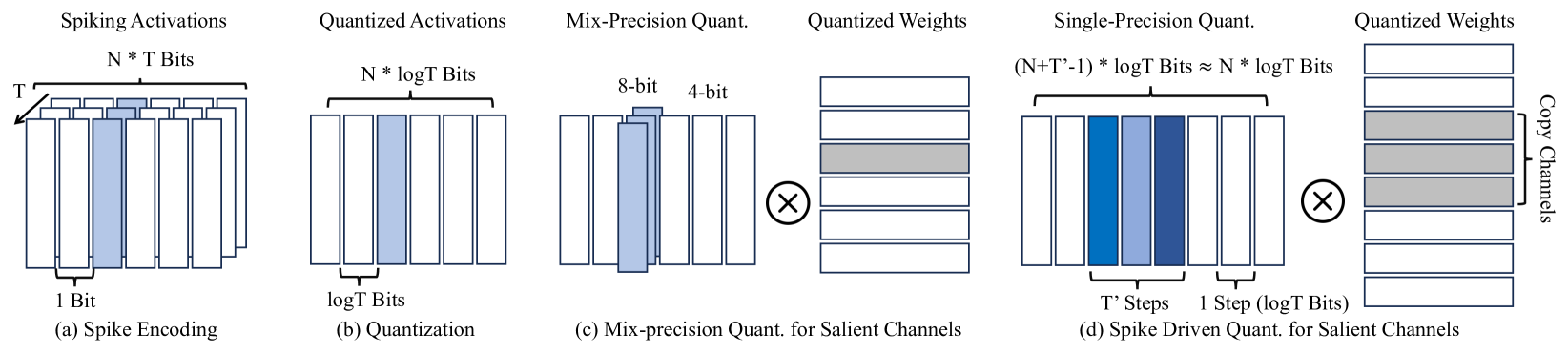
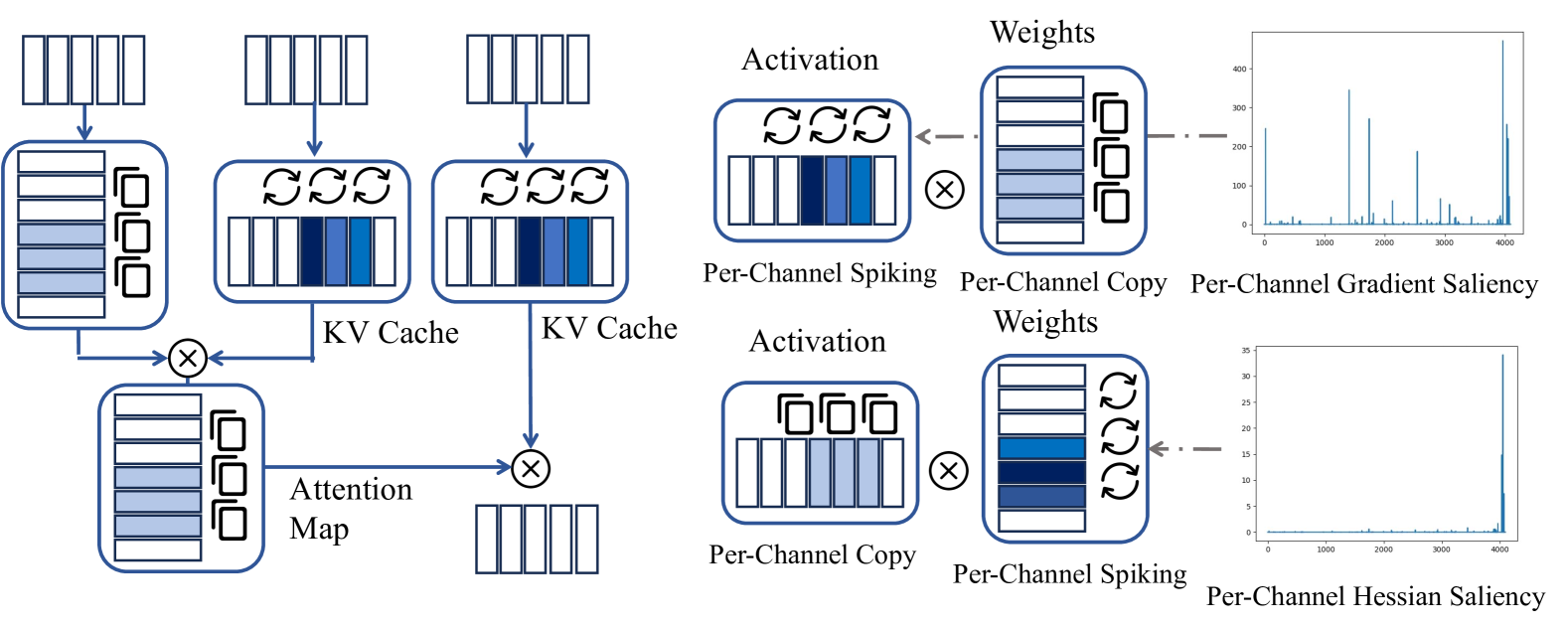
技术框架:SpikeLLM的整体框架包括以下几个主要组成部分:1) 将预训练的LLM(如LLAMA)的权重迁移到SNN结构;2) 使用广义积分-发放(GIF)神经元替换传统神经元,以压缩脉冲长度;3) 引入最优大脑脉冲框架,用于划分异常通道并为GIF神经元分配不同的时间步长T;4) 使用脉冲反向传播算法对SNN进行训练和优化。该框架旨在将LLM的强大能力与SNN的高能效特性相结合。
关键创新:论文的关键创新点在于:1) 提出了第一个基于脉冲神经网络的大型语言模型SpikeLLM;2) 提出了广义积分-发放(GIF)神经元,通过参数L来控制脉冲长度的压缩,实现了在精度和计算效率之间的平衡;3) 提出了最优大脑脉冲框架,通过分析不同通道的激活情况,动态地分配时间步长T,进一步提高了计算效率。与传统的量化方法相比,SpikeLLM能够实现更低的功耗和更高的精度。
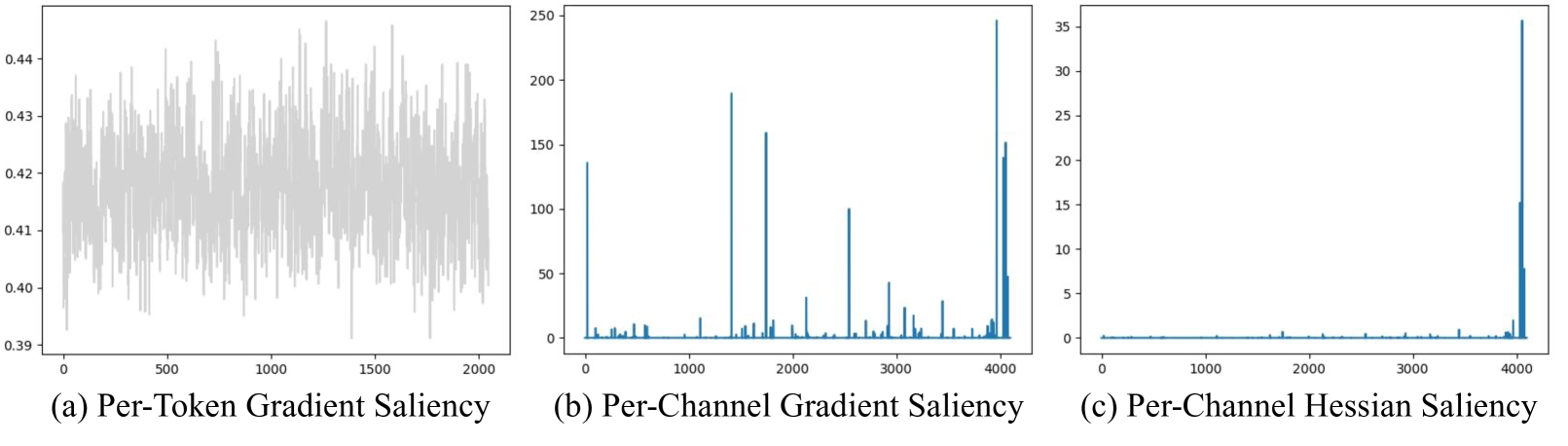
关键设计:在GIF神经元的设计中,参数L控制了脉冲长度的压缩比例,需要根据具体的任务和模型进行调整。最优大脑脉冲框架通过计算每个通道的显著性得分来确定其重要性,并根据重要性分配不同的时间步长T。在训练过程中,使用了脉冲反向传播算法,并对学习率和优化器进行了调整,以保证SNN的收敛性和性能。
🖼️ 关键图片
📊 实验亮点
SpikeLLM在WikiText2数据集上实现了11.01%的困惑度降低,并在LLAMA-7B W4A4模型上实现了2.55%的常见场景推理准确率提升。与传统的量化方法相比,SpikeLLM在GPTQ流程中实现了线性层中的直接加性,显著超过了PB-LLMs,表明其在计算效率和精度方面具有显著优势。
🎯 应用场景
SpikeLLM具有广泛的应用前景,尤其是在边缘计算设备、移动设备和物联网设备等资源受限的环境中。它可以用于部署低功耗、高性能的自然语言处理应用,如智能助手、机器翻译、文本摘要和情感分析等。此外,SpikeLLM还可以应用于神经形态计算领域,为开发更高效、更节能的人工智能系统提供新的思路。
📄 摘要(原文)
Recent advancements in large language models (LLMs) with billions of parameters have improved performance in various applications, but their inference processes demand significant energy and computational resources. In contrast, the human brain, with approximately 86 billion neurons, is much more energy-efficient than LLMs with similar parameters. Inspired by this, we redesign 7$\sim$70 billion parameter LLMs using bio-plausible spiking mechanisms, emulating the efficient behavior of the human brain. We propose the first spiking large language model, SpikeLLM. Coupled with the proposed model, two essential approaches are proposed to improve spike training efficiency: Generalized Integrate-and-Fire (GIF) neurons to compress spike length from $T$ to $\frac{T}{L} \log_2 L$ bits, and an Optimal Brain Spiking framework to divide outlier channels and allocate different $T$ for GIF neurons, which further compresses spike length to approximate $log_2T$ bits. The necessity of spike-driven LLM is proved by comparison with quantized LLMs with similar operations. In the OmniQuant pipeline, SpikeLLM reduces 11.01% WikiText2 perplexity and improves 2.55% accuracy of common scene reasoning on a LLAMA-7B W4A4 model. In the GPTQ pipeline, SpikeLLM achieves direct additive in linear layers, significantly exceeding PB-LLMs.