Low-latency machine learning FPGA accelerator for multi-qubit-state discrimination
作者: Pradeep Kumar Gautam, Shantharam Kalipatnapu, Shankaranarayanan H, Ujjawal Singhal, Benjamin Lienhard, Vibhor Singh, Chetan Singh Thakur
分类: quant-ph, cs.AR, cs.LG
发布日期: 2024-07-04 (更新: 2024-08-14)
备注: 10 pages, 6 figures
💡 一句话要点
提出低延迟FPGA加速器以解决多量子比特状态判别问题
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 量子计算 FPGA 神经网络 多量子比特 低延迟 加速器 量子比特测量 频率复用
📋 核心要点
- 现有量子比特状态测量方法容易受到多种错误影响,导致测量不准确,影响量子计算的可靠性。
- 本文提出了一种将神经网络加速器部署到FPGA的方法,能够在保证低延迟的同时,减少计算复杂性和提高准确性。
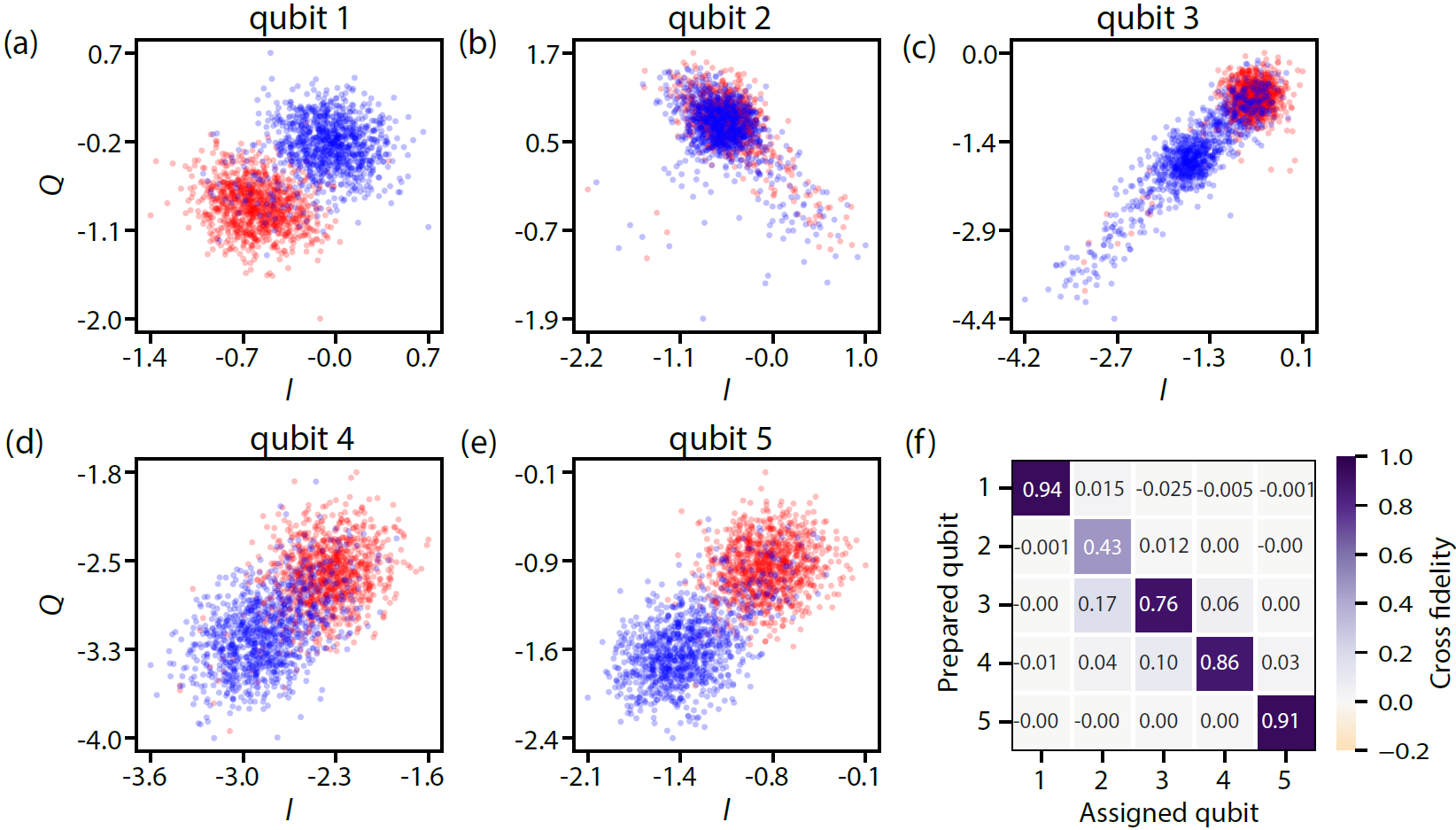
- 实验结果表明,该加速器在RFSoC ZCU111 FPGA上实现了对五个超导量子比特的快速读出,延迟低于50纳秒,具有显著的性能提升。
📝 摘要(中文)
测量量子比特状态是量子计算中的基本操作,但容易出错,错误来源包括串扰、自发态转变和读出脉冲引起的激发。本文采用集成方法将神经网络部署到现场可编程门阵列(FPGA)上,展示了为多量子比特读出实现全连接神经网络加速器的优势,平衡了计算复杂性与低延迟要求,且准确性损失不显著。该硬件加速器在RFSoC ZCU111 FPGA上实现了对五个超导量子比特的频率复用读出,时间少于50纳秒,标志着基于RFSoC的低延迟多量子比特读出技术的进展。此模块可集成到现有的量子控制和读出平台中,为实验部署做好准备。
🔬 方法详解
问题定义:本文旨在解决量子比特状态测量中的高错误率和延迟问题。现有方法在处理多量子比特时,往往面临计算复杂性高和实时性不足的挑战。
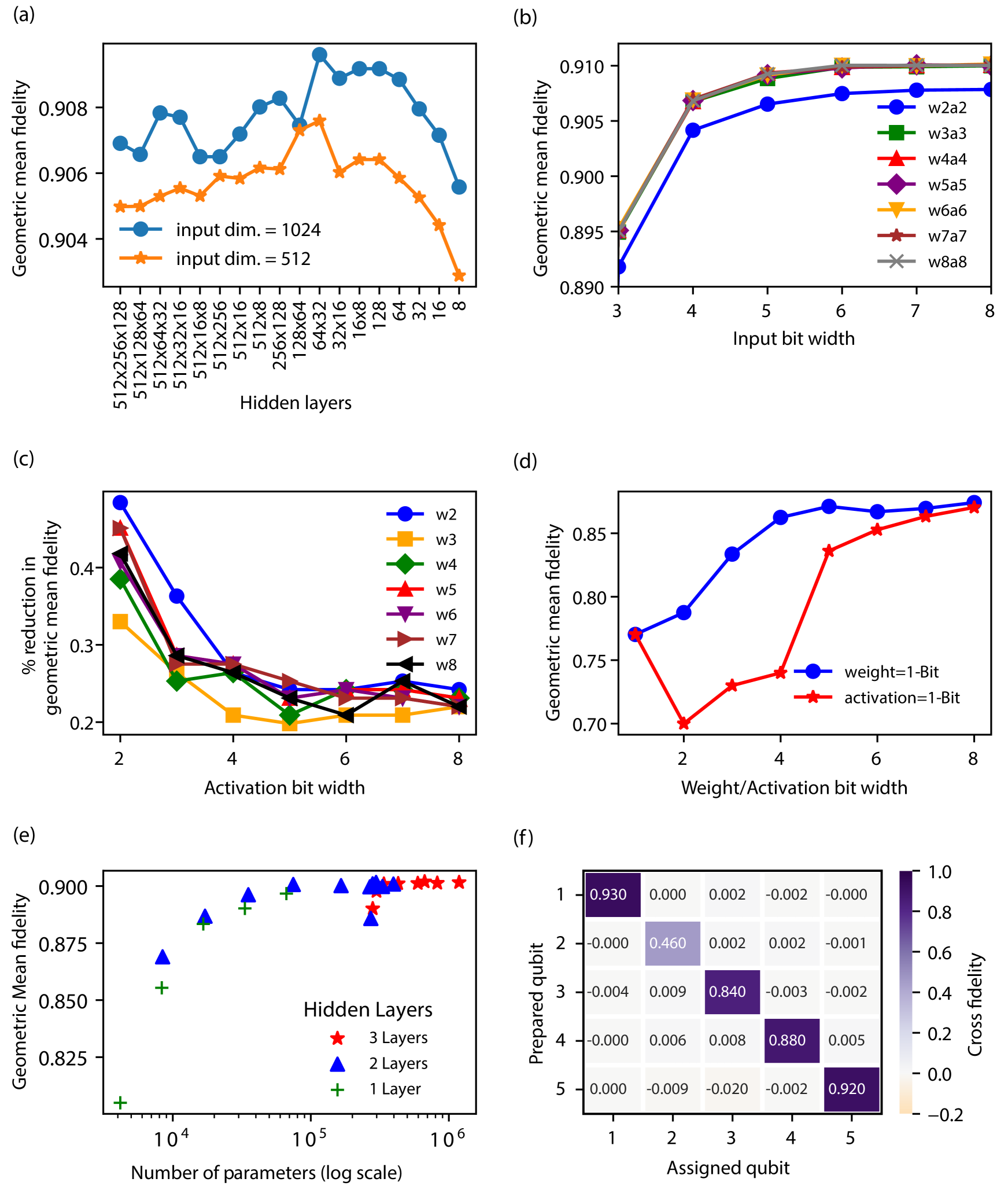
核心思路:论文的核心思路是将全连接神经网络加速器集成到FPGA中,通过量化权重、激活函数和输入,来实现低延迟的多量子比特读出。这样的设计旨在优化计算效率,同时保持测量的准确性。
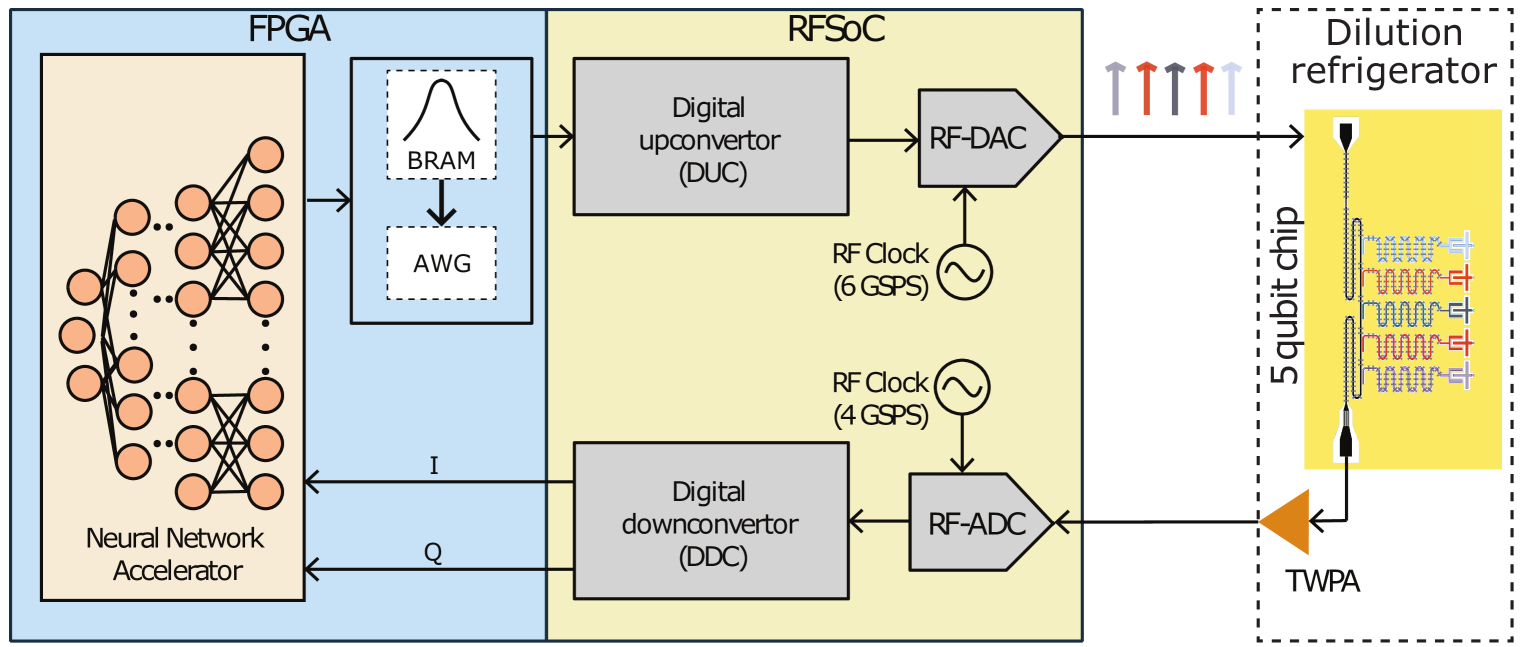
技术框架:整体架构包括数据输入模块、神经网络处理模块和输出模块。数据输入模块负责接收量子比特的状态信息,神经网络处理模块进行状态判别,输出模块则将结果反馈至量子控制系统。
关键创新:最重要的技术创新在于将神经网络与FPGA结合,实现了频率复用的多量子比特读出,显著降低了读出延迟,并且在准确性上没有显著损失。与传统方法相比,这种集成方式在实时性和效率上具有本质的优势。
关键设计:在设计中,采用了量化技术来减少计算资源消耗,损失函数选择了适合多类分类的交叉熵损失,网络结构为全连接层,确保了信息的充分传递和处理。
🖼️ 关键图片
📊 实验亮点
实验结果显示,所提出的FPGA加速器在RFSoC ZCU111平台上实现了对五个超导量子比特的频率复用读出,延迟低于50纳秒,显著提升了读出速度,相较于传统方法具有更高的实时性和效率。
🎯 应用场景
该研究的潜在应用领域包括量子计算中的量子比特状态测量、量子控制系统的实时反馈以及量子信息处理等。通过提高量子比特读出的速度和准确性,能够推动量子计算技术的实际应用,提升量子计算机的性能和可靠性。
📄 摘要(原文)
Measuring a qubit state is a fundamental yet error-prone operation in quantum computing. These errors can arise from various sources, such as crosstalk, spontaneous state transitions, and excitations caused by the readout pulse. Here, we utilize an integrated approach to deploy neural networks onto field-programmable gate arrays (FPGA). We demonstrate that implementing a fully connected neural network accelerator for multi-qubit readout is advantageous, balancing computational complexity with low latency requirements without significant loss in accuracy. The neural network is implemented by quantizing weights, activation functions, and inputs. The hardware accelerator performs frequency-multiplexed readout of five superconducting qubits in less than 50 ns on a radio frequency system on chip (RFSoC) ZCU111 FPGA, marking the advent of RFSoC-based low-latency multi-qubit readout using neural networks. These modules can be implemented and integrated into existing quantum control and readout platforms, making the RFSoC ZCU111 ready for experimental deployment.