A Survey of Data Synthesis Approaches
作者: Hsin-Yu Chang, Pei-Yu Chen, Tun-Hsiang Chou, Chang-Sheng Kao, Hsuan-Yun Yu, Yen-Ting Lin, Yun-Nung Chen
分类: cs.LG, cs.AI
发布日期: 2024-07-04
💡 一句话要点
合成数据技术综述:提升数据质量与模型泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 合成数据 数据增强 机器学习 领域迁移 数据质量
📋 核心要点
- 现有机器学习模型依赖大量数据,但真实数据获取成本高昂,且可能存在偏差或隐私问题,限制了模型性能和泛化能力。
- 本文综述了多种合成数据生成方法,涵盖了从基于专家知识到利用预训练模型等不同策略,旨在弥补真实数据不足。
- 论文还探讨了合成数据的质量评估与过滤方法,并展望了未来多模型数据增强等发展方向,为后续研究提供参考。
📝 摘要(中文)
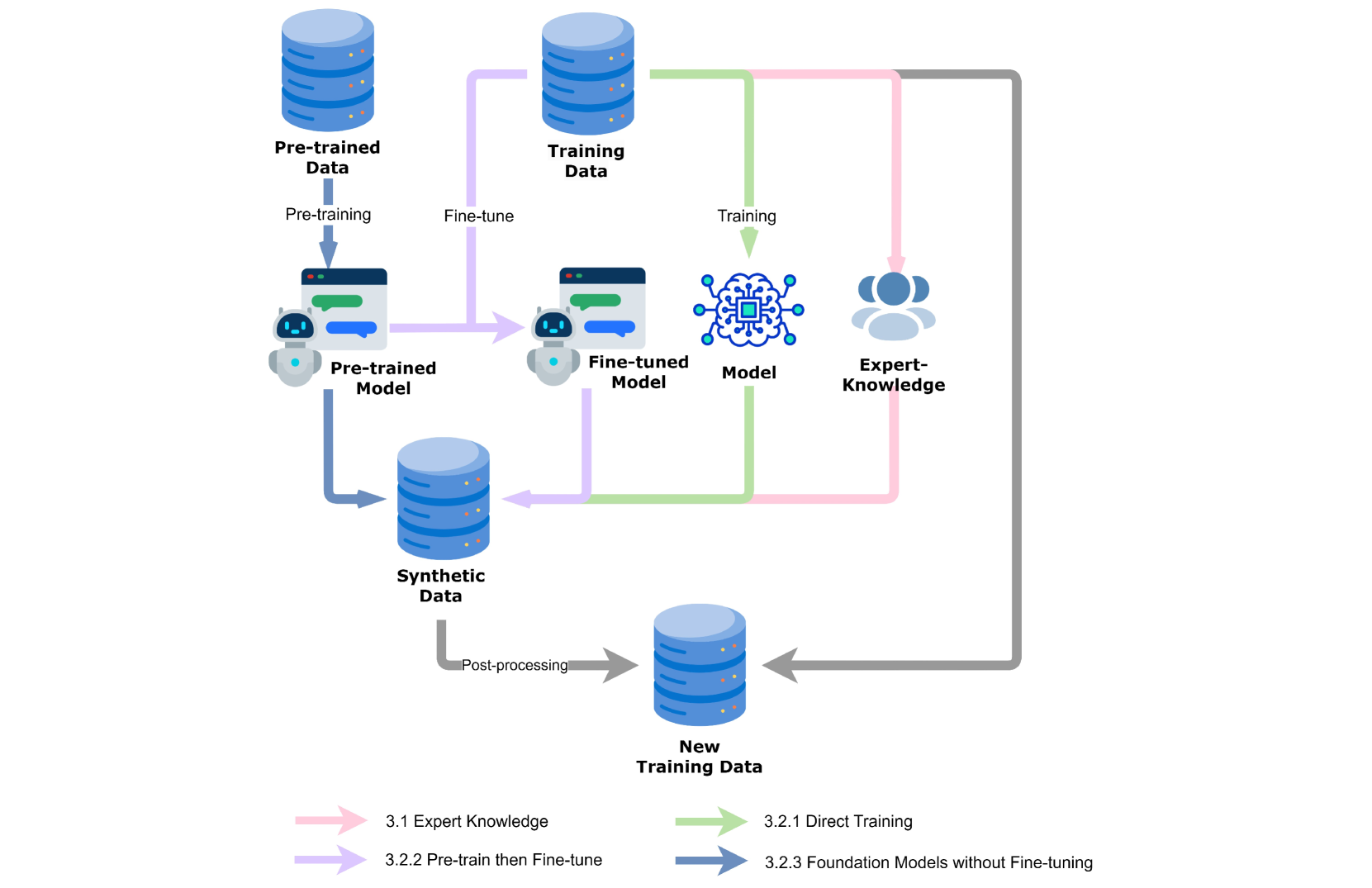
本文对合成数据技术进行了详细的综述。首先讨论了在数据增强中使用合成数据的预期目标,这些目标可以分为四个部分:1) 提高多样性,2) 数据平衡,3) 解决领域迁移问题,以及 4) 解决边缘情况。合成数据与当时流行的机器学习技术密切相关,因此,我们将合成数据技术领域总结为四个类别:1) 专家知识,2) 直接训练,3) 预训练然后微调,以及 4) 无需微调的基础模型。接下来,我们将合成数据过滤的目标分为四种类型进行讨论:1) 基本质量,2) 标签一致性,以及 3) 数据分布。在本文的第5节中,我们还讨论了合成数据的未来方向,并提出了我们认为重要的三个方向:1) 更加关注质量,2) 合成数据的评估,以及 3) 多模型数据增强。
🔬 方法详解
问题定义:现有机器学习模型训练依赖大量高质量数据,但真实数据获取成本高、存在隐私问题,且分布可能不均衡,导致模型泛化能力受限。合成数据旨在通过算法生成数据,弥补真实数据不足,但如何保证合成数据的质量和有效性是一个关键挑战。
核心思路:本文的核心思路是对现有的合成数据生成技术进行系统性的梳理和分类,并从数据增强的目标出发,分析不同方法的优缺点和适用场景。通过对合成数据生成、过滤和评估等环节的深入探讨,为研究人员提供全面的指导。
技术框架:本文将合成数据技术分为四个类别:1) 基于专家知识的方法,利用领域知识生成数据;2) 直接训练的方法,如GAN等;3) 预训练后微调的方法,利用预训练模型生成数据;4) 无需微调的基础模型,直接利用大型模型生成数据。同时,论文还讨论了合成数据过滤的四个目标:基本质量、标签一致性和数据分布。
关键创新:本文的创新之处在于对合成数据技术进行了全面的综述和分类,并从数据增强的目标出发,分析了不同方法的优缺点和适用场景。此外,论文还提出了合成数据质量评估和过滤的重要性,并展望了未来多模型数据增强等发展方向。
关键设计:论文没有提出新的算法或模型,而是对现有方法进行了梳理和总结。关键在于对不同方法的分类和分析,以及对合成数据质量评估和过滤的重视。未来的研究方向包括如何设计更有效的合成数据评估指标,以及如何利用多模型融合来生成更高质量的合成数据。
🖼️ 关键图片
📊 实验亮点
本文重点在于对现有合成数据技术的系统性总结与分类,并强调了合成数据质量评估的重要性。虽然没有提供具体的实验数据,但通过对不同方法的优缺点分析,为研究人员选择合适的合成数据生成策略提供了指导。未来研究方向包括提升合成数据质量和设计更有效的评估指标。
🎯 应用场景
该研究对计算机视觉、自然语言处理、机器人等领域具有广泛的应用价值。通过合成数据,可以有效解决数据稀缺、数据偏差和隐私保护等问题,提升模型的泛化能力和鲁棒性。例如,在自动驾驶领域,可以利用合成数据生成各种极端场景,提高自动驾驶系统的安全性。
📄 摘要(原文)
This paper provides a detailed survey of synthetic data techniques. We first discuss the expected goals of using synthetic data in data augmentation, which can be divided into four parts: 1) Improving Diversity, 2) Data Balancing, 3) Addressing Domain Shift, and 4) Resolving Edge Cases. Synthesizing data are closely related to the prevailing machine learning techniques at the time, therefore, we summarize the domain of synthetic data techniques into four categories: 1) Expert-knowledge, 2) Direct Training, 3) Pre-train then Fine-tune, and 4) Foundation Models without Fine-tuning. Next, we categorize the goals of synthetic data filtering into four types for discussion: 1) Basic Quality, 2) Label Consistency, and 3) Data Distribution. In section 5 of this paper, we also discuss the future directions of synthetic data and state three direction that we believe is important: 1) focus more on quality, 2) the evaluation of synthetic data, and 3) multi-model data augmentation.