DLO: Dynamic Layer Operation for Efficient Vertical Scaling of LLMs
作者: Zhen Tan, Daize Dong, Xinyu Zhao, Jie Peng, Yu Cheng, Tianlong Chen
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-07-03
💡 一句话要点
DLO:通过动态层操作实现LLM高效垂直扩展
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 动态层操作 模型扩展 高效计算 特征相似性
📋 核心要点
- 现有方法扩展LLM通常增加模型宽度或深度,但忽略了层间冗余,导致计算效率低下。
- DLO通过动态地激活、扩展或跳过Transformer层,根据输入特征的相似性进行智能路由,减少冗余计算。
- 实验表明,DLO在效率上优于原始模型,性能与密集扩展模型相当,无需昂贵的持续预训练。
📝 摘要(中文)
本文提出动态层操作(DLO),一种新型的Transformer大语言模型(LLM)垂直扩展方法。DLO基于层间特征相似性的复杂路由策略,动态地扩展、激活或跳过层。与侧重于扩展模型宽度的传统混合专家(MoE)方法不同,DLO针对模型深度,解决不同输入样本在层表示中观察到的冗余问题。该框架与监督微调(SFT)阶段集成,无需资源密集型的持续预训练(CPT)。实验结果表明,DLO不仅优于原始未扩展模型,而且实现了与密集扩展模型相当的结果,同时显著提高了效率。这项工作为构建高效而强大的LLM提供了一个有希望的方向。我们将于接收后发布我们的实现和模型权重。
🔬 方法详解
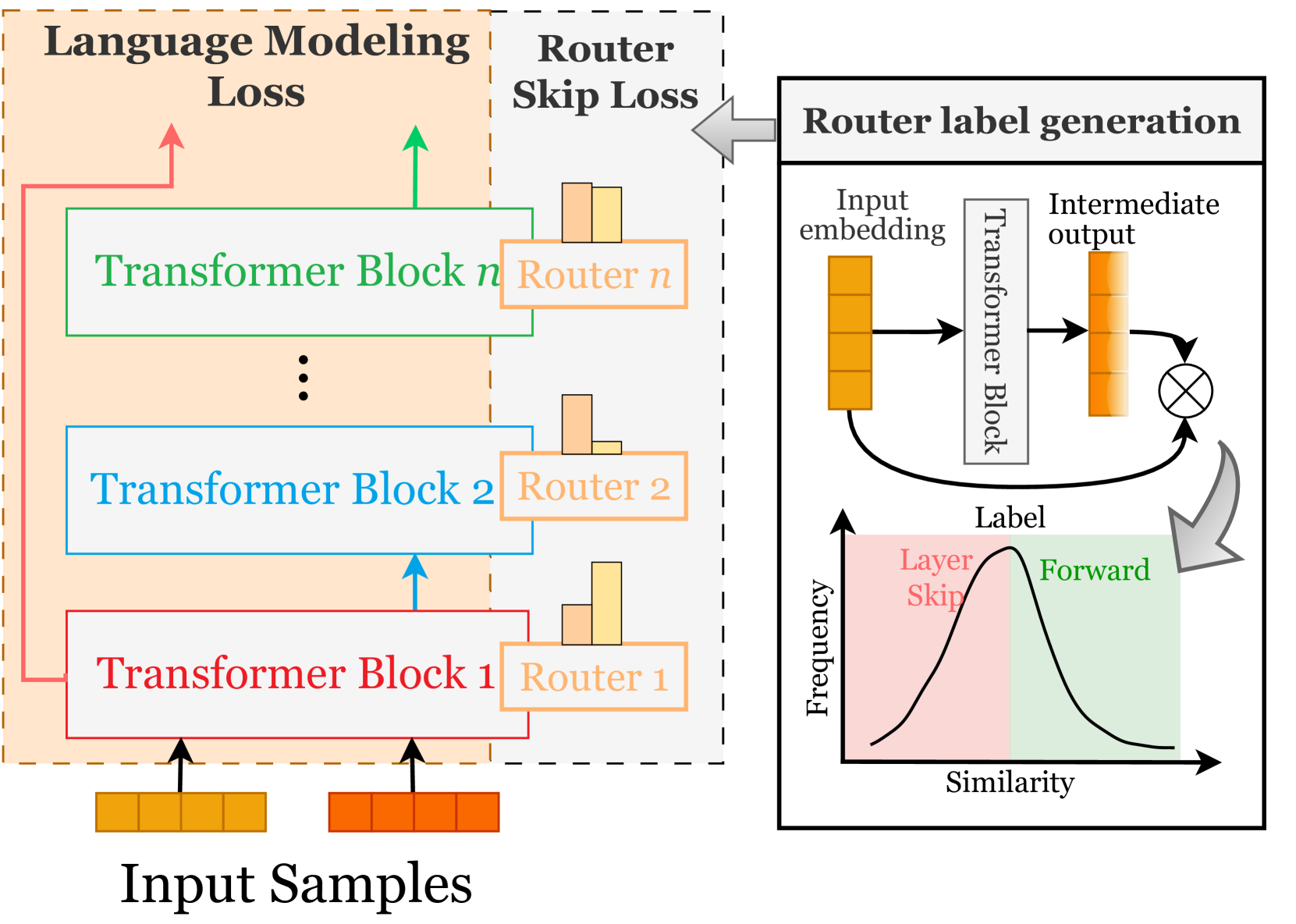
问题定义:现有的大语言模型(LLM)扩展方法,如增加模型宽度(例如MoE)或简单地增加模型深度,忽略了不同输入样本在不同层之间可能存在的冗余信息。这意味着某些层对于特定输入可能是不必要的,导致计算资源的浪费。因此,如何高效地利用模型深度,避免冗余计算,是本文要解决的关键问题。
核心思路:本文的核心思路是根据输入样本在不同层之间的特征相似性,动态地调整模型的层操作。具体来说,对于不同的输入,模型可以选择性地扩展、激活或跳过某些层。通过这种方式,模型可以专注于处理对当前输入最重要的层,从而提高计算效率。
技术框架:DLO框架主要包含以下几个阶段:1) 特征提取:输入样本通过Transformer层进行特征提取。2) 相似性计算:计算相邻层之间的特征相似性。3) 路由策略:基于相似性得分,确定每一层应该执行的操作(扩展、激活或跳过)。4) 层操作执行:根据路由策略,动态地调整模型的层操作。5) 监督微调(SFT):将DLO框架集成到SFT阶段,优化模型参数。
关键创新:DLO的关键创新在于其动态层操作机制。与传统的静态模型结构不同,DLO可以根据输入动态地调整模型的深度,从而实现更高效的计算。此外,DLO直接集成到SFT阶段,避免了昂贵的持续预训练,降低了训练成本。
关键设计:DLO的关键设计包括:1) 层间特征相似性度量:可以使用余弦相似度或其他相似性度量方法来衡量层间特征的相似性。2) 路由策略:可以使用基于阈值的策略或更复杂的学习策略来确定每一层应该执行的操作。3) 损失函数:可以使用交叉熵损失函数或其他适合特定任务的损失函数来优化模型参数。4) 网络结构:DLO可以应用于各种Transformer-based的LLM架构。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DLO在多个NLP任务上优于原始未扩展模型,并且实现了与密集扩展模型相当的性能,同时显著提高了计算效率。具体来说,DLO在保持性能的同时,可以减少高达30%的计算量。此外,DLO无需昂贵的持续预训练,降低了训练成本。
🎯 应用场景
DLO具有广泛的应用前景,可用于构建更高效、更强大的LLM。例如,可以将其应用于自然语言处理、机器翻译、文本生成等领域。通过减少计算冗余,DLO可以降低模型部署成本,使其更容易在资源受限的环境中使用。此外,DLO还可以促进LLM在移动设备和边缘计算设备上的应用。
📄 摘要(原文)
In this paper, we introduce Dynamic Layer Operations (DLO), a novel approach for vertically scaling transformer-based Large Language Models (LLMs) by dynamically expanding, activating, or skipping layers using a sophisticated routing policy based on layerwise feature similarity. Unlike traditional Mixture-of-Experts (MoE) methods that focus on extending the model width, our approach targets model depth, addressing the redundancy observed across layer representations for various input samples. Our framework is integrated with the Supervised Fine-Tuning (SFT) stage, eliminating the need for resource-intensive Continual Pre-Training (CPT). Experimental results demonstrate that DLO not only outperforms the original unscaled models but also achieves comparable results to densely expanded models with significantly improved efficiency. Our work offers a promising direction for building efficient yet powerful LLMs. We will release our implementation and model weights upon acceptance.