LoRA-Guard: Parameter-Efficient Guardrail Adaptation for Content Moderation of Large Language Models
作者: Hayder Elesedy, Pedro M. Esperança, Silviu Vlad Oprea, Mete Ozay
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-07-03 (更新: 2024-12-18)
💡 一句话要点
提出LoRA-Guard,通过参数高效的Guardrail适配实现大语言模型的内容审核,适用于资源受限设备。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 内容审核 大语言模型 低秩适配 参数高效 Guardrail 移动设备 本地部署
📋 核心要点
- 现有基于模型的guardrail方法在资源受限设备上部署存在挑战,无法满足日益增长的本地LLM应用需求。
- LoRA-Guard通过知识共享和低秩适配,实现了LLM与guardrail模型之间的参数高效适配,降低了计算开销。
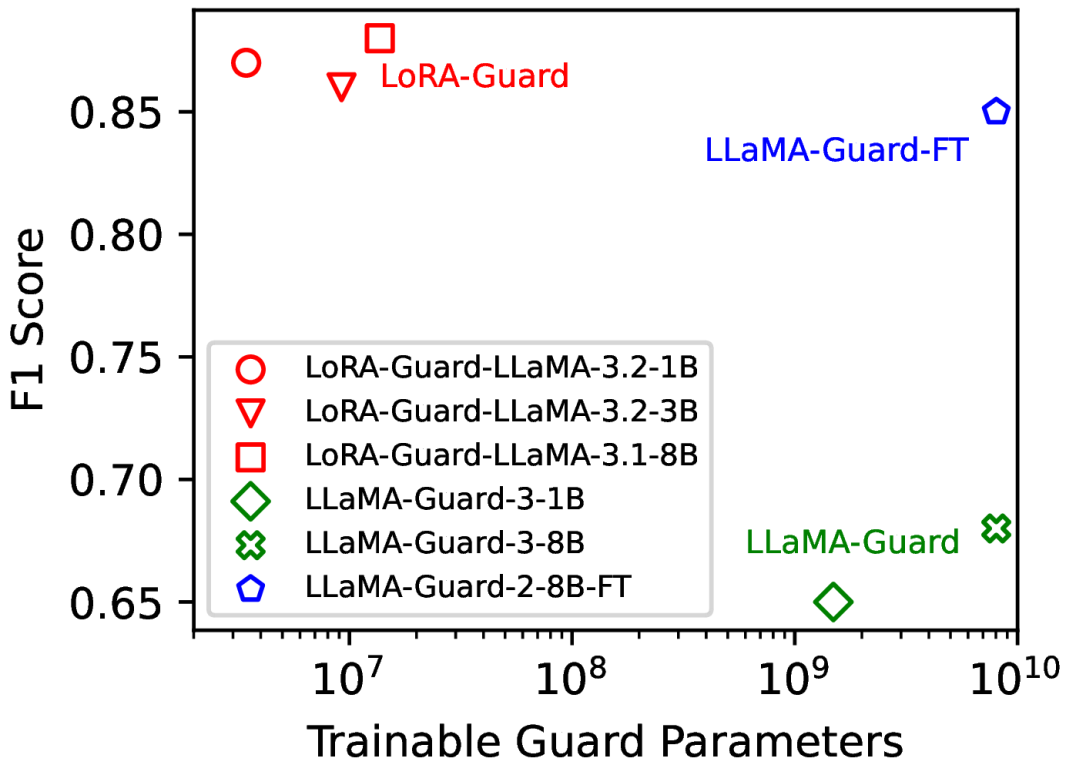
- 实验结果表明,LoRA-Guard在保持内容审核准确性的同时,显著降低了参数量,实现了在设备上的高效部署。
📝 摘要(中文)
本文提出LoRA-Guard,一种参数高效的guardrail适配方法,用于大语言模型(LLM)的内容审核。现有基于模型的guardrail并非为资源受限的便携式计算设备(如手机)设计,而越来越多的基于LLM的应用在本地运行。LoRA-Guard从LLM中提取语言特征,并使用低秩适配器将其适配于内容审核任务。双路径设计可防止生成任务的性能下降。实验表明,LoRA-Guard以100-1000倍更低的参数开销优于现有方法,同时保持准确性,从而实现设备上的内容审核。
🔬 方法详解
问题定义:现有基于模型的guardrail方法通常参数量较大,难以部署在资源受限的移动设备上,无法满足本地LLM应用的内容审核需求。因此,需要一种参数高效的方法,在保证内容审核准确性的前提下,降低模型大小,使其能够在移动设备上运行。
核心思路:LoRA-Guard的核心思路是利用低秩适配(LoRA)技术,通过少量参数来调整LLM的语言特征,使其适应内容审核任务。同时,采用双路径设计,保证在进行内容审核的同时,不影响LLM原有的生成能力。通过知识共享,减少guardrail模型所需的参数量。
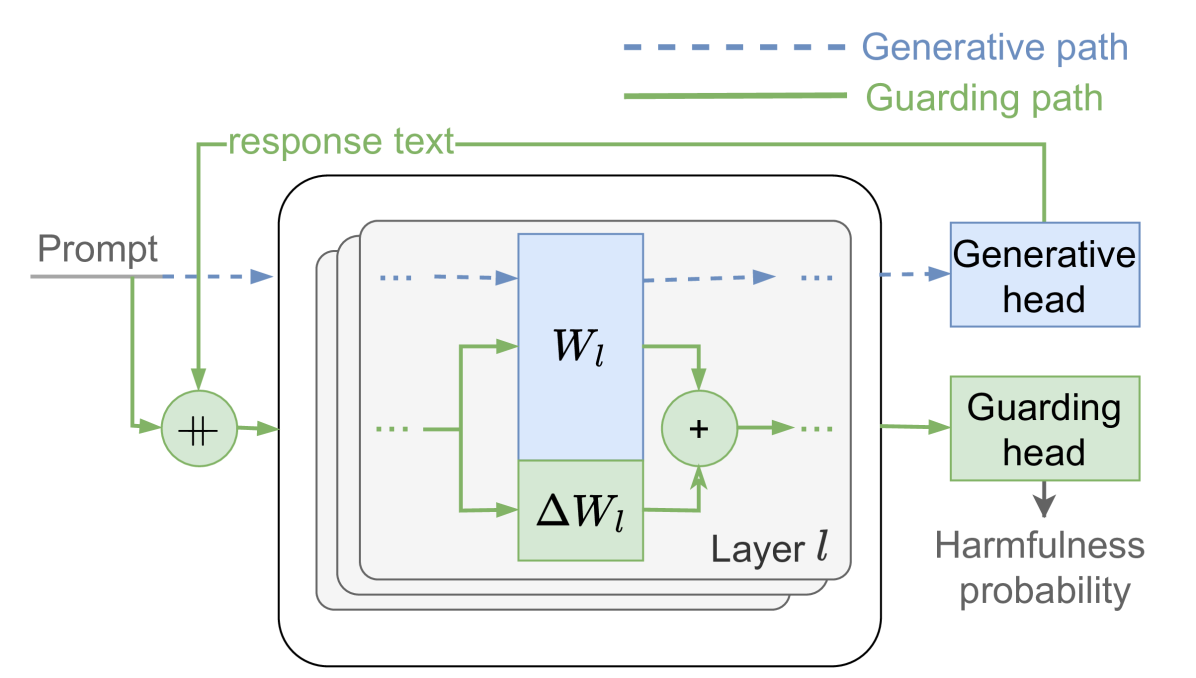
技术框架:LoRA-Guard包含两个主要路径:LLM路径和Guardrail路径。LLM路径负责提取输入文本的语言特征。Guardrail路径使用低秩适配器(LoRA)调整LLM提取的特征,并将其用于内容审核任务。这两个路径并行运行,互不影响。整体流程为:输入文本首先经过LLM提取特征,然后特征被送入Guardrail路径进行内容审核,同时LLM路径继续进行生成任务。
关键创新:LoRA-Guard的关键创新在于其参数高效性。通过利用低秩适配器,LoRA-Guard仅需少量参数即可实现内容审核功能,相比于直接训练一个大型guardrail模型,大大降低了参数开销。此外,双路径设计保证了内容审核不会影响LLM的生成性能。
关键设计:LoRA-Guard使用预训练的LLM作为特征提取器,并在此基础上添加低秩适配器。低秩适配器的秩(rank)是一个关键参数,决定了适配器的参数量和性能。论文中可能探讨了不同秩对性能的影响。损失函数可能包括内容审核的分类损失和LLM生成任务的损失,以保证两个任务的性能。
🖼️ 关键图片
📊 实验亮点
LoRA-Guard在内容审核任务上表现出色,以100-1000倍更低的参数开销优于现有方法,同时保持了较高的准确性。这表明LoRA-Guard能够在资源受限的设备上实现高效的内容审核,为本地LLM应用提供了可行的解决方案。具体的性能数据和对比基线需要在论文中查找。
🎯 应用场景
LoRA-Guard可应用于各种需要本地内容审核的场景,例如移动设备上的聊天机器人、智能助手等。它能够有效过滤有害信息,保护用户安全,同时降低计算成本,提升用户体验。未来,该技术有望在边缘计算设备上得到广泛应用,实现更加安全、可靠的本地LLM服务。
📄 摘要(原文)
Guardrails have emerged as an alternative to safety alignment for content moderation of large language models (LLMs). Existing model-based guardrails have not been designed for resource-constrained computational portable devices, such as mobile phones, more and more of which are running LLM-based applications locally. We introduce LoRA-Guard, a parameter-efficient guardrail adaptation method that relies on knowledge sharing between LLMs and guardrail models. LoRA-Guard extracts language features from the LLMs and adapts them for the content moderation task using low-rank adapters, while a dual-path design prevents any performance degradation on the generative task. We show that LoRA-Guard outperforms existing approaches with 100-1000x lower parameter overhead while maintaining accuracy, enabling on-device content moderation.