GPTQT: Quantize Large Language Models Twice to Push the Efficiency
作者: Yipin Guo, Yilin Lang, Qinyuan Ren
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-07-03
备注: Accepted by 11th IEEE International Conference on Cybernetics and Intelligent Systems
💡 一句话要点
GPTQT:通过两次量化大型语言模型权重,提升效率并降低存储需求
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 量化 后训练量化 低比特量化 模型压缩 二进制编码 推理加速
📋 核心要点
- 大型语言模型(LLM)体积庞大,需要大量的计算和存储资源,现有量化方法难以兼顾效率与精度。
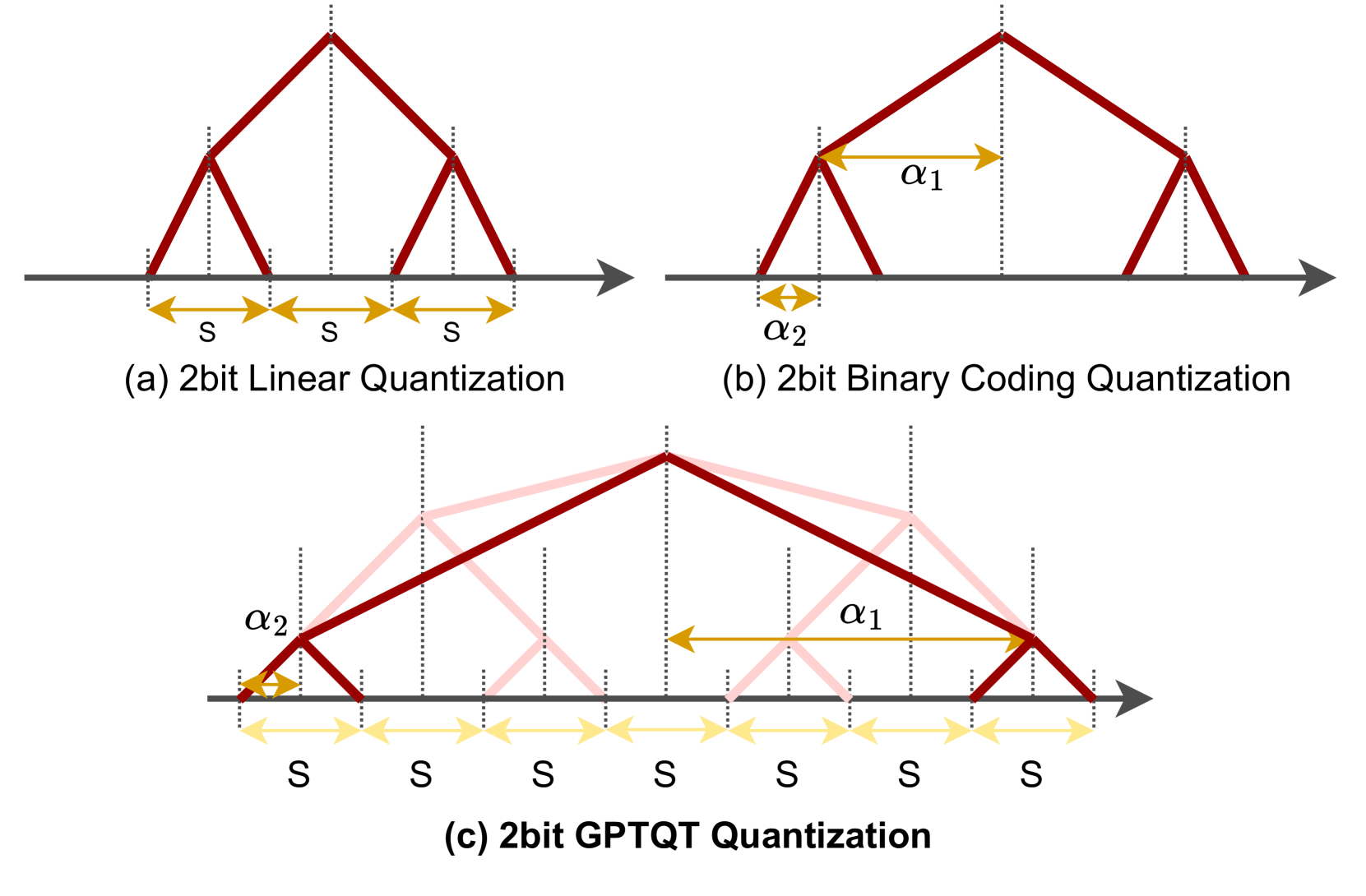
- GPTQT采用渐进式两步量化策略,先进行较高比特线性量化,再转换为低比特二进制编码,并优化缩放因子。
- 实验表明,GPTQT在多个模型和数据集上有效,相比3比特基线,降低了困惑度并提高了推理速度。
📝 摘要(中文)
本文提出了一种新的后训练量化方法GPTQT,旨在通过使用3比特/2比特表示LLM的权重来减少内存使用并提高处理速度。研究表明,最小化权重的量化误差是无效的,会导致过拟合。因此,GPTQT采用了一种渐进的两步方法:首先使用线性量化将权重量化到相对较高的比特,然后将获得的整数权重转换为较低比特的二进制编码。提出了一种重新探索策略来优化初始缩放因子。在推理过程中,这些步骤被合并为纯二进制编码,从而实现高效计算。在各种模型和数据集上的测试证实了GPTQT的有效性。与强大的3比特量化基线相比,GPTQT在opt-66B上进一步降低了4.01的困惑度,并在opt-30b上提高了1.24倍的速度。Llama2上的结果表明,GPTQT是目前此类LLM的最佳二进制编码量化方法。
🔬 方法详解
问题定义:大型语言模型(LLM)的部署面临着巨大的计算和存储挑战。现有的量化方法,特别是直接最小化量化误差的方法,容易导致过拟合,无法在极低比特(如2bit/3bit)下保持良好的性能。因此,如何在保持模型性能的同时,进一步降低LLM的存储需求和提高推理速度,是一个亟待解决的问题。
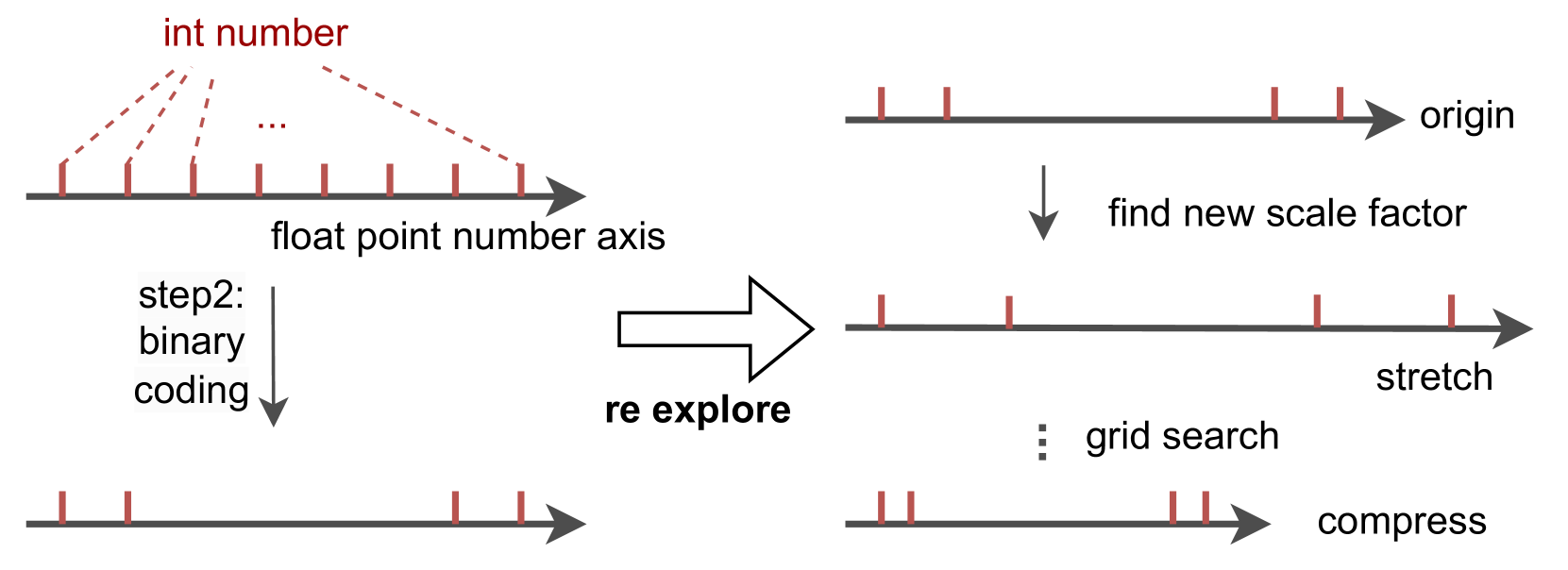
核心思路:GPTQT的核心思路是采用一种渐进式的两步量化策略,避免直接优化低比特量化误差。首先,将权重线性量化到相对较高的比特,然后再将这些整数权重转换为更低比特的二进制编码。这种分阶段的方法旨在更好地保留原始权重中的重要信息,并减少量化过程中的信息损失。同时,通过重新探索策略优化初始缩放因子,进一步提升量化效果。
技术框架:GPTQT的整体流程包括两个主要阶段:第一阶段是线性量化,将原始浮点权重转换为较高比特的整数权重。第二阶段是将这些整数权重转换为低比特的二进制编码。在推理阶段,这两个步骤被合并成一个纯二进制编码,以实现高效的计算。此外,还包含一个缩放因子优化模块,用于调整第一阶段的缩放因子,以进一步提高量化精度。
关键创新:GPTQT的关键创新在于其渐进式的两步量化策略和重新探索缩放因子的方法。与传统的直接量化到低比特的方法不同,GPTQT通过分阶段量化,更好地保留了原始权重的信息。重新探索缩放因子则进一步优化了量化过程,提高了量化精度。这种方法特别适用于极低比特量化,能够有效避免过拟合问题。
关键设计:GPTQT的关键设计包括:1) 线性量化的比特数选择(第一阶段);2) 二进制编码的具体方式(第二阶段);3) 缩放因子优化策略,例如采用某种搜索算法来寻找最佳缩放因子;4) 如何将两步量化合并为纯二进制编码,以实现高效推理。论文中可能还涉及具体的损失函数设计,用于指导缩放因子的优化过程。这些细节决定了GPTQT的最终性能。
🖼️ 关键图片

📊 实验亮点
GPTQT在多个LLM和数据集上进行了广泛的实验验证。在opt-66B模型上,GPTQT相比于强大的3比特量化基线,进一步降低了4.01的困惑度。在opt-30b模型上,GPTQT将推理速度提高了1.24倍。在Llama2模型上的实验结果表明,GPTQT是目前最佳的二进制编码量化方法。这些结果充分证明了GPTQT在降低存储需求和提高推理效率方面的有效性。
🎯 应用场景
GPTQT具有广泛的应用前景,尤其是在资源受限的场景下部署大型语言模型。例如,它可以应用于移动设备、嵌入式系统和边缘计算设备,使得这些设备能够运行更大规模的LLM,从而实现更智能的应用。此外,GPTQT还可以降低LLM的存储和传输成本,促进LLM在云计算和分布式系统中的应用。
📄 摘要(原文)
Due to their large size, generative Large Language Models (LLMs) require significant computing and storage resources. This paper introduces a new post-training quantization method, GPTQT, to reduce memory usage and enhance processing speed by expressing the weight of LLM in 3bit/2bit. Practice has shown that minimizing the quantization error of weights is ineffective, leading to overfitting. Therefore, GPTQT employs a progressive two-step approach: initially quantizing weights using Linear quantization to a relatively high bit, followed by converting obtained int weight to lower bit binary coding. A re-explore strategy is proposed to optimize initial scaling factor. During inference, these steps are merged into pure binary coding, enabling efficient computation. Testing across various models and datasets confirms GPTQT's effectiveness. Compared to the strong 3-bit quantization baseline, GPTQT further reduces perplexity by 4.01 on opt-66B and increases speed by 1.24 times on opt-30b. The results on Llama2 show that GPTQT is currently the best binary coding quantization method for such kind of LLMs.