Beyond Scaleup: Knowledge-aware Parsimony Learning from Deep Networks
作者: Quanming Yao, Yongqi Zhang, Yaqing Wang, Nan Yin, James Kwok, Qiang Yang
分类: cs.LG, cs.AI
发布日期: 2024-06-29 (更新: 2024-12-17)
备注: Accepted to AI Magazine
💡 一句话要点
提出知识驱动的简约学习框架,克服深度网络过度依赖规模扩张的局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识驱动学习 简约学习 深度网络 领域知识 药物相互作用预测
📋 核心要点
- 现有深度学习模型依赖大规模数据和算力,但面临数据稀缺、计算成本高昂和模型可信度不足等挑战。
- 论文提出知识驱动的简约学习方法,利用领域知识指导模型设计,在保证性能的同时降低模型复杂度。
- 实验结果表明,该方法在多个任务上超越了传统缩放定律的方法,并在药物相互作用预测等科学领域展现了潜力。
📝 摘要(中文)
本文旨在解决当前深度学习模型过度依赖大规模数据集、参数和算力扩张的问题,这种策略的可持续性面临数据、计算和信任瓶颈。我们提出一种简约学习方法,利用领域知识(如符号、逻辑和公式)驱动模型,而非单纯依赖规模扩张。该方法构建了一个以领域知识为“构建块”的框架,在模型设计、训练和解释方面实现简约性。实验结果表明,我们的方法优于遵循传统缩放定律的方法。我们还在科学人工智能领域,特别是药物相互作用预测问题中验证了该框架。希望我们的研究能够促进基础模型时代更多样化的技术路线。
🔬 方法详解
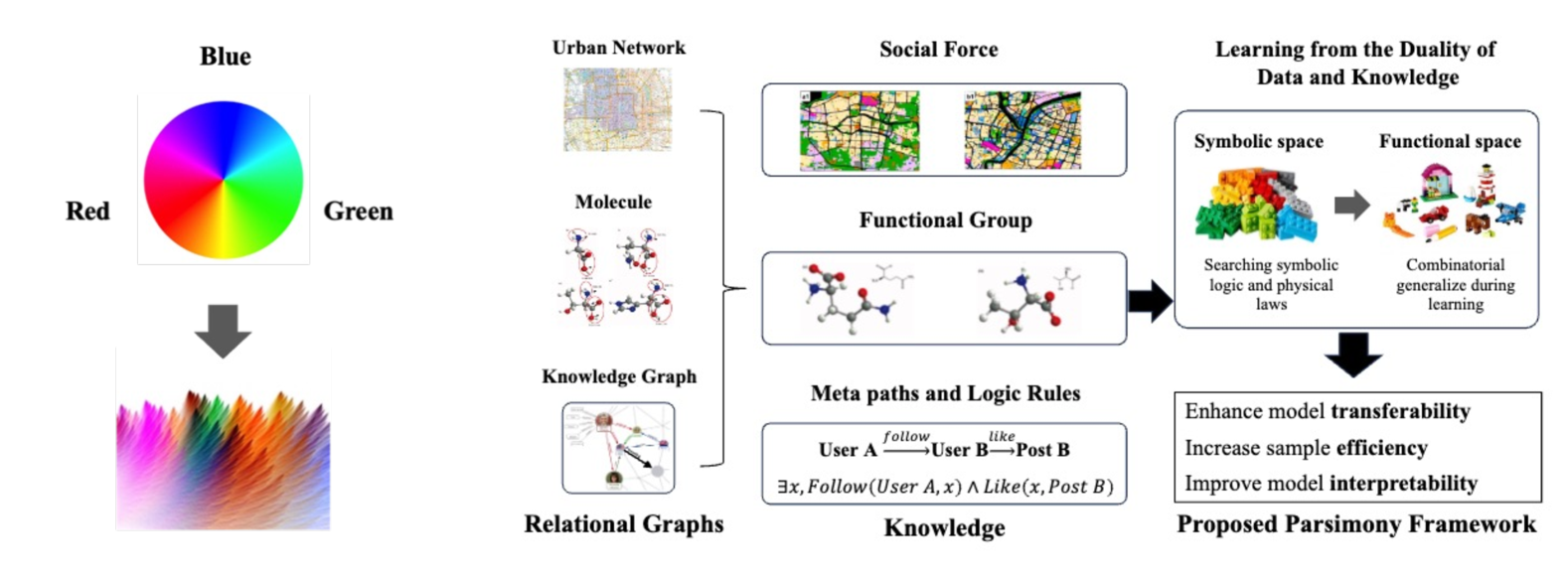
问题定义:当前深度学习模型为了追求更高的性能,往往采用“暴力”的规模扩张策略,即增加训练数据集的大小、模型参数的数量以及计算能力。然而,这种策略面临着数据获取困难、计算资源消耗巨大以及模型可解释性差等问题,其可持续性受到质疑。因此,如何以更简约的方式(即使用更简单的模型)实现更高的性能,是本文要解决的核心问题。
核心思路:本文的核心思路是利用领域知识来指导模型的学习过程,而不是仅仅依赖于大规模的数据。通过将领域知识(如符号、逻辑和公式)融入到模型中,可以有效地减少模型对数据的依赖,提高模型的泛化能力和可解释性。这种方法类似于人类专家利用领域知识来解决问题,而不是仅仅依靠经验数据。
技术框架:该框架主要包含三个阶段:1) 知识表示:将领域知识表示成计算机可以理解的形式,例如符号、逻辑规则或数学公式。2) 知识融合:将领域知识融入到模型的设计和训练过程中。这可以通过多种方式实现,例如将知识作为正则化项添加到损失函数中,或者使用知识来指导模型的结构设计。3) 知识解释:利用领域知识来解释模型的预测结果,提高模型的可解释性和可信度。
关键创新:该论文的关键创新在于提出了一个通用的知识驱动的简约学习框架,该框架可以应用于不同的领域和任务。与传统的深度学习方法相比,该框架更加注重利用领域知识来指导模型的学习过程,从而在保证性能的同时降低了模型的复杂度。此外,该框架还提供了一种利用领域知识来解释模型预测结果的方法,提高了模型的可解释性和可信度。
关键设计:具体的知识融合方式取决于具体的任务和领域知识。例如,在药物相互作用预测任务中,可以将药物的化学结构信息和已知的药物相互作用信息作为领域知识,并将其融入到模型的训练过程中。损失函数的设计也需要考虑领域知识的影响,例如可以添加一个正则化项,鼓励模型学习符合领域知识的预测结果。网络结构的设计也可以借鉴领域知识,例如可以使用图神经网络来表示药物之间的相互作用关系。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在多个数据集上取得了显著的性能提升。例如,在药物相互作用预测任务中,该方法优于传统的深度学习方法,并且能够提供更具解释性的预测结果。此外,该方法还能够有效地降低模型的复杂度,减少计算资源的消耗。具体性能提升数据未知,需要查阅论文原文。
🎯 应用场景
该研究成果可广泛应用于需要高可靠性和可解释性的领域,例如医疗诊断、金融风控、智能制造等。通过将领域知识融入到模型中,可以提高模型的泛化能力和可解释性,从而更好地服务于实际应用。特别是在数据稀缺或获取成本高的场景下,该方法具有重要的应用价值。未来,该研究有望推动人工智能在科学发现和工程设计等领域的应用。
📄 摘要(原文)
The brute-force scaleup of training datasets, learnable parameters and computation power, has become a prevalent strategy for developing more robust learning models. However, due to bottlenecks in data, computation, and trust, the sustainability of this strategy is a serious concern. In this paper, we attempt to address this issue in a parsimonious manner (i.e., achieving greater potential with simpler models). The key is to drive models using domain-specific knowledge, such as symbols, logic, and formulas, instead of purely relying on scaleup. This approach allows us to build a framework that uses this knowledge as "building blocks" to achieve parsimony in model design, training, and interpretation. Empirical results show that our methods surpass those that typically follow the scaling law. We also demonstrate our framework in AI for science, specifically in the problem of drug-drug interaction prediction. We hope our research can foster more diverse technical roadmaps in the era of foundation models.