Towards Stable and Storage-efficient Dataset Distillation: Matching Convexified Trajectory
作者: Wenliang Zhong, Haoyu Tang, Qinghai Zheng, Mingzhu Xu, Yupeng Hu, Liqiang Nie
分类: cs.LG
发布日期: 2024-06-28
备注: 11 pages
💡 一句话要点
提出匹配凸化轨迹(MCT)方法,解决数据集蒸馏中训练轨迹匹配的不稳定性和存储效率问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据集蒸馏 训练轨迹匹配 凸优化 神经正切核 模型压缩
📋 核心要点
- 现有基于训练轨迹匹配(MTT)的数据集蒸馏方法存在专家轨迹不稳定、蒸馏收敛慢和存储消耗高等问题。
- 论文提出匹配凸化轨迹(MCT)方法,通过构建专家轨迹的凸组合,为学生网络提供更稳定和高效的训练指导。
- 实验结果表明,MCT方法在多个数据集上优于传统MTT方法,验证了其在稳定性和存储效率方面的优势。
📝 摘要(中文)
深度学习和大型语言模型的快速发展导致对训练数据的需求呈指数级增长,这促使数据集蒸馏方法的发展,以应对管理大型数据集的挑战。其中,匹配训练轨迹(MTT)是一种突出的方法,它使用合成数据集复制专家网络在真实数据上的训练轨迹。然而,我们的研究发现该方法存在三个显著的局限性:1. 随机梯度下降(SGD)产生的专家轨迹的不稳定性;2. 蒸馏过程的收敛速度慢;3. 专家轨迹的高存储消耗。为了解决这些问题,我们通过对目标函数进行简单的变换,提供了一个理解数据集蒸馏和MTT本质的新视角,并提出了一种名为匹配凸化轨迹(MCT)的新方法,旨在为学生轨迹提供更好的指导。MCT利用神经正切核方法的线性化动态的见解,创建专家轨迹的凸组合,引导学生网络快速稳定地收敛。这种轨迹不仅更容易存储,而且能够在蒸馏过程中实现连续采样策略,确保对整个专家轨迹进行彻底的学习和拟合。在三个公共数据集上的综合实验验证了MCT相对于传统MTT方法的优越性。
🔬 方法详解
问题定义:数据集蒸馏旨在用一个小的合成数据集来模拟真实数据集的训练过程,从而降低存储和计算成本。现有的匹配训练轨迹(MTT)方法通过匹配学生网络和专家网络在真实数据上的训练轨迹来实现蒸馏。然而,由于专家网络使用随机梯度下降(SGD)进行训练,其训练轨迹存在不稳定性,导致蒸馏过程收敛速度慢,且需要存储大量的专家轨迹数据。
核心思路:论文的核心思路是通过构建专家轨迹的凸组合来生成更稳定和易于存储的训练目标。具体来说,利用神经正切核(NTK)方法的线性化动态特性,将专家轨迹表示为一系列线性组合,从而降低轨迹的噪声和不确定性。这种凸化的轨迹能够为学生网络提供更平滑和可靠的训练指导,加速收敛并提高蒸馏效果。
技术框架:MCT方法主要包含以下几个阶段:1. 专家网络训练:使用真实数据集训练一个专家网络。2. 专家轨迹提取:记录专家网络在训练过程中的参数变化,形成专家轨迹。3. 凸化轨迹构建:利用NTK方法的线性化动态特性,将专家轨迹表示为凸组合。4. 学生网络训练:使用合成数据集训练学生网络,目标是匹配凸化后的专家轨迹。5. 连续采样策略:在训练学生网络时,采用连续采样策略,确保学生网络能够充分学习和拟合整个凸化轨迹。
关键创新:MCT方法的关键创新在于将NTK方法的线性化动态特性引入到数据集蒸馏中,通过构建专家轨迹的凸组合来提高训练的稳定性和效率。与传统的MTT方法直接匹配原始的、不稳定的专家轨迹不同,MCT方法匹配的是一个经过凸化处理的、更平滑和可靠的轨迹,从而避免了SGD带来的噪声和不确定性。
关键设计:MCT方法的关键设计包括:1. 凸组合的权重计算:利用NTK理论计算每个专家轨迹的权重,确保凸组合能够准确地表示原始轨迹的整体趋势。2. 损失函数设计:设计一个损失函数来衡量学生网络和凸化专家轨迹之间的差异,目标是最小化这种差异。3. 连续采样策略:在训练学生网络时,采用连续采样策略,即每次迭代都从凸化轨迹中随机选择一个时间点,并计算学生网络在该时间点的输出与专家网络在该时间点的输出之间的差异。这种策略能够确保学生网络能够充分学习和拟合整个凸化轨迹。
🖼️ 关键图片

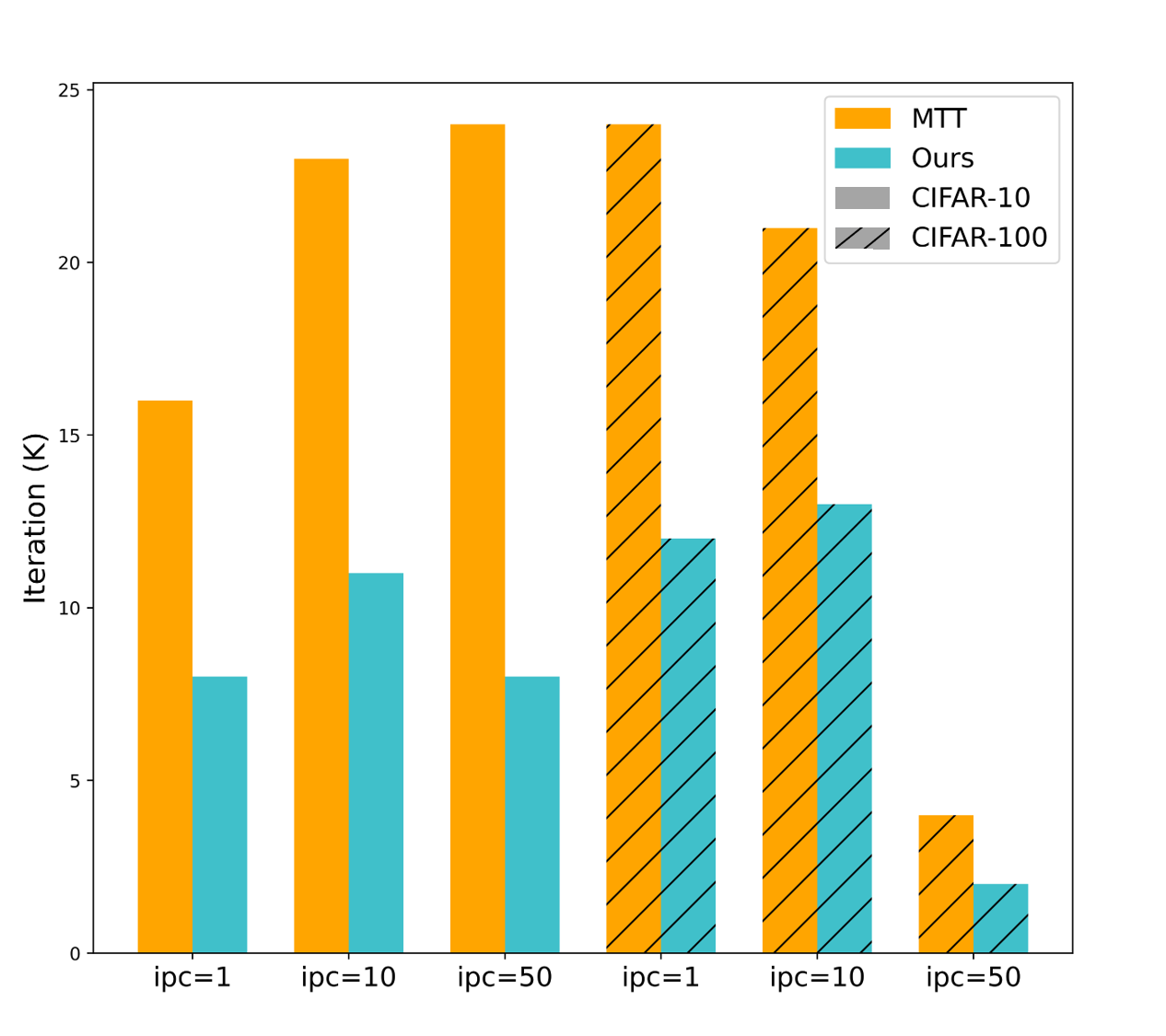

📊 实验亮点
实验结果表明,MCT方法在三个公共数据集上均优于传统的MTT方法。例如,在CIFAR-10数据集上,使用MCT方法训练的学生网络达到了与使用原始数据集训练的专家网络相近的性能,同时显著降低了存储成本。此外,MCT方法还表现出更快的收敛速度和更高的训练稳定性。
🎯 应用场景
该研究成果可应用于各种需要数据集蒸馏的场景,例如模型压缩、联邦学习和隐私保护。通过使用更小、更易于管理的合成数据集,可以降低存储和计算成本,提高训练效率,并保护原始数据的隐私。此外,该方法还可以用于加速新模型的开发和部署,特别是在数据量有限或获取成本较高的情况下。
📄 摘要(原文)
The rapid evolution of deep learning and large language models has led to an exponential growth in the demand for training data, prompting the development of Dataset Distillation methods to address the challenges of managing large datasets. Among these, Matching Training Trajectories (MTT) has been a prominent approach, which replicates the training trajectory of an expert network on real data with a synthetic dataset. However, our investigation found that this method suffers from three significant limitations: 1. Instability of expert trajectory generated by Stochastic Gradient Descent (SGD); 2. Low convergence speed of the distillation process; 3. High storage consumption of the expert trajectory. To address these issues, we offer a new perspective on understanding the essence of Dataset Distillation and MTT through a simple transformation of the objective function, and introduce a novel method called Matching Convexified Trajectory (MCT), which aims to provide better guidance for the student trajectory. MCT leverages insights from the linearized dynamics of Neural Tangent Kernel methods to create a convex combination of expert trajectories, guiding the student network to converge rapidly and stably. This trajectory is not only easier to store, but also enables a continuous sampling strategy during distillation, ensuring thorough learning and fitting of the entire expert trajectory. Comprehensive experiments across three public datasets validate the superiority of MCT over traditional MTT methods.