LLMEasyQuant: Scalable Quantization for Parallel and Distributed LLM Inference
作者: Dong Liu, Yanxuan Yu
分类: cs.LG
发布日期: 2024-06-28 (更新: 2025-11-27)
备注: Accepted as International Conference of Computational Optimization 2025 Oral
💡 一句话要点
LLMEasyQuant:面向并行和分布式LLM推理的可扩展量化框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 量化 低比特推理 分布式推理 CUDA内核 系统优化 硬件加速
📋 核心要点
- 现有量化工具包在LLM部署中缺乏透明度、灵活性和系统级可扩展性,难以满足不同硬件环境的需求。
- LLMEasyQuant通过模块化设计和系统感知优化,提供统一接口支持多种量化方法,并能自适应运行时环境。
- 实验表明,LLMEasyQuant在GEMM执行、HBM加载和多GPU扩展方面均有显著提升,并能有效平衡延迟、内存和精度。
📝 摘要(中文)
随着大型语言模型(LLMs)规模和部署规模的增长,量化已成为降低内存占用和提高推理效率的关键技术。然而,现有的量化工具包通常缺乏透明度、灵活性以及跨GPU和分布式环境的系统级可扩展性。我们提出了 extbf{LLMEasyQuant},这是一个模块化、系统感知的量化框架,专为在单节点多GPU、多节点和边缘硬件上进行高效、低比特LLM推理而设计。LLMEasyQuant支持广泛的量化方法——包括对称量化、ZeroQuant、SmoothQuant和SimQuant——具有统一的接口,用于逐层校准、比特宽度分配和运行时自适应。它集成了融合的CUDA内核与基于NCCL的分布式同步,并支持静态和在线量化。实验结果表明,LLMEasyQuant可以在GEMM执行、HBM加载时间和近线性多GPU扩展方面实现显著加速。消融研究进一步验证了其在不同部署条件下平衡延迟、内存和准确性的能力。LLMEasyQuant为可扩展的、硬件优化的LLM推理提供了一个实用的量化服务系统。
🔬 方法详解
问题定义:现有LLM量化工具包通常缺乏透明度、灵活性和系统级可扩展性。它们难以在不同的硬件平台(如单节点多GPU、多节点集群和边缘设备)上高效部署LLM,并且难以支持多种量化算法和运行时自适应。
核心思路:LLMEasyQuant的核心思路是构建一个模块化、系统感知的量化框架。通过模块化设计,可以灵活地支持不同的量化方法和硬件平台。系统感知优化则能够根据硬件特性和运行时状态,自适应地调整量化参数,从而实现最佳的性能。
技术框架:LLMEasyQuant的整体架构包含以下几个主要模块:1) 量化方法支持模块:支持对称量化、ZeroQuant、SmoothQuant和SimQuant等多种量化方法。2) 逐层校准模块:对每一层进行独立的校准,以确定最佳的量化参数。3) 比特宽度分配模块:根据每一层的特性,动态地分配比特宽度。4) 运行时自适应模块:根据硬件状态和运行时负载,动态地调整量化参数。5) CUDA内核融合模块:通过融合CUDA内核,减少kernel launch的开销。6) 分布式同步模块:基于NCCL实现多GPU和多节点的分布式同步。
关键创新:LLMEasyQuant的关键创新在于其模块化设计和系统感知优化。模块化设计使得框架具有很高的灵活性和可扩展性,可以方便地支持新的量化方法和硬件平台。系统感知优化则能够根据硬件特性和运行时状态,自适应地调整量化参数,从而实现最佳的性能。此外,融合CUDA内核和基于NCCL的分布式同步也显著提升了推理效率。
关键设计:LLMEasyQuant的关键设计包括:1) 统一的量化接口,方便用户使用不同的量化方法。2) 逐层校准策略,能够更好地适应不同层的特性。3) 动态比特宽度分配策略,能够在精度和性能之间取得平衡。4) 运行时自适应策略,能够根据硬件状态和运行时负载动态调整量化参数。5) 融合CUDA内核,减少kernel launch的开销。6) 基于NCCL的分布式同步,实现高效的多GPU和多节点通信。
🖼️ 关键图片

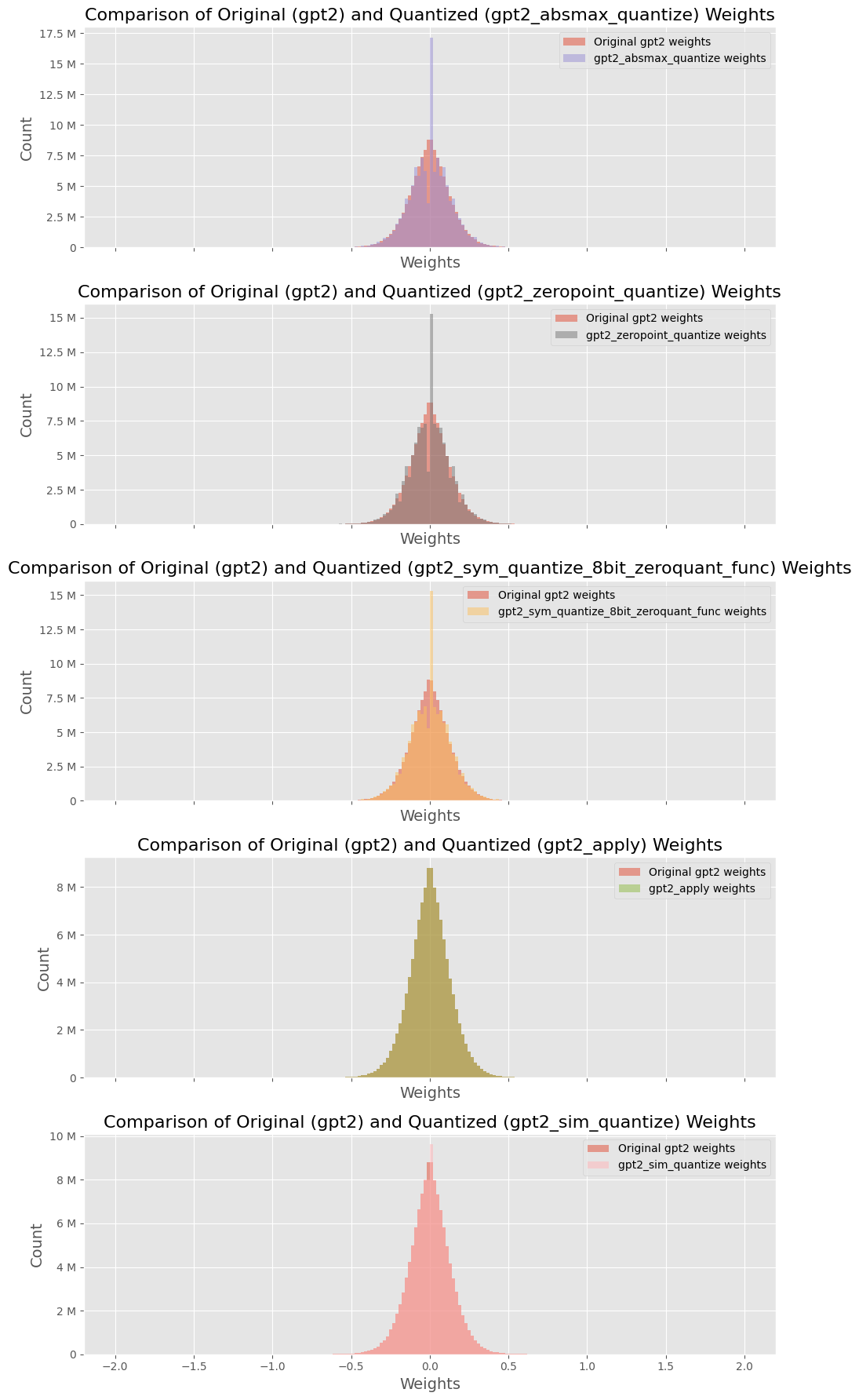
📊 实验亮点
实验结果表明,LLMEasyQuant在GEMM执行速度、HBM加载时间和多GPU扩展性方面均有显著提升。例如,在多GPU环境下,LLMEasyQuant实现了近线性的扩展,显著降低了推理延迟。消融实验验证了LLMEasyQuant在不同部署条件下平衡延迟、内存和准确性的能力,证明了其在实际应用中的有效性。
🎯 应用场景
LLMEasyQuant可广泛应用于各种需要高效LLM推理的场景,如智能客服、机器翻译、文本生成等。它尤其适用于资源受限的边缘设备和需要大规模并行推理的云服务器。通过降低内存占用和提高推理速度,LLMEasyQuant能够显著降低LLM部署的成本,并提升用户体验,加速LLM在各行业的落地。
📄 摘要(原文)
As large language models (LLMs) grow in size and deployment scale, quantization has become an essential technique for reducing memory footprint and improving inference efficiency. However, existing quantization toolkits often lack transparency, flexibility, and system-level scalability across GPUs and distributed environments. We present \textbf{LLMEasyQuant}, a modular, system-aware quantization framework designed for efficient, low-bit inference of LLMs on single-node multi-GPU, multi-node, and edge hardware. LLMEasyQuant supports a wide range of quantization methods -- including Symmetric Quantization, ZeroQuant, SmoothQuant, and SimQuant -- with unified interfaces for per-layer calibration, bitwidth assignment, and runtime adaptation. It integrates fused CUDA kernels with NCCL-based distributed synchronization and supports both static and online quantization. Empirical results show that LLMEasyQuant can achieve substantial speedup in GEMM execution, HBM load time, and near-linear multi-GPU scaling. Ablation studies further validate its ability to balance latency, memory, and accuracy under diverse deployment conditions. LLMEasyQuant offers a practical quantization serving system for scalable, hardware-optimized LLM inference.