OmniJARVIS: Unified Vision-Language-Action Tokenization Enables Open-World Instruction Following Agents
作者: Zihao Wang, Shaofei Cai, Zhancun Mu, Haowei Lin, Ceyao Zhang, Xuejie Liu, Qing Li, Anji Liu, Xiaojian Ma, Yitao Liang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-06-27 (更新: 2024-10-31)
备注: accepted on NeurIPS 2024
💡 一句话要点
OmniJARVIS:统一视觉-语言-动作 Token 化实现开放世界指令跟随智能体
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 开放世界 指令跟随 统一Token化 Minecraft 自监督学习 模仿学习
📋 核心要点
- 现有方法在Minecraft等开放世界中,指令跟随智能体难以兼顾推理能力和决策效率。
- OmniJARVIS通过统一Token化多模态交互数据,将视觉、语言和动作信息整合,实现高效推理和决策。
- OmniJARVIS在Minecraft的各类任务中表现出色,验证了统一Token化和交互数据设计的有效性。
📝 摘要(中文)
本文提出了OmniJARVIS,一种用于Minecraft开放世界中指令跟随智能体的全新视觉-语言-动作(VLA)模型。与以往将文本目标传递给独立控制器或直接生成控制命令的方法不同,OmniJARVIS探索了一条不同的路径,通过多模态交互数据的统一Token化来确保强大的推理和高效的决策能力。首先,我们引入了一种自监督方法来学习行为编码器,该编码器为行为轨迹τ= {o_0, a_0, ...}生成离散化的Token,以及一个以这些Token为条件的模仿学习策略解码器。这些额外的行为Token将被添加到预训练多模态语言模型的词汇表中。借助此编码器,我们将长期多模态交互(包括任务指令、记忆、思考、观察、文本响应、行为轨迹等)打包成统一的Token序列,并使用自回归Transformer对其进行建模。由于语义上有意义的行为Token,由此产生的VLA模型OmniJARVIS可以进行推理(通过生成思维链)、规划、回答问题和行动(通过为模仿学习策略解码器生成行为Token)。OmniJARVIS在开放世界Minecraft中一系列全面的原子、程序化和开放式任务中表现出卓越的性能。我们的分析进一步揭示了交互数据形成、统一Token化及其扩展潜力的关键设计原则。数据集、模型和代码将在https://craftjarvis.org/OmniJARVIS上发布。
🔬 方法详解
问题定义:现有开放世界指令跟随智能体,要么将任务分解为文本目标传递给独立的控制器,要么直接生成控制命令。前者推理能力较强但决策效率低,后者决策效率高但缺乏有效的推理能力。因此,如何在开放世界环境中构建兼具强大推理能力和高效决策能力的智能体是一个挑战。
核心思路:OmniJARVIS的核心思路是通过统一Token化多模态交互数据,将视觉、语言和动作信息整合到一个统一的序列中,然后利用自回归Transformer模型进行建模。这种方法允许模型在推理、规划、回答问题和行动之间无缝切换,从而实现更强的通用性和灵活性。
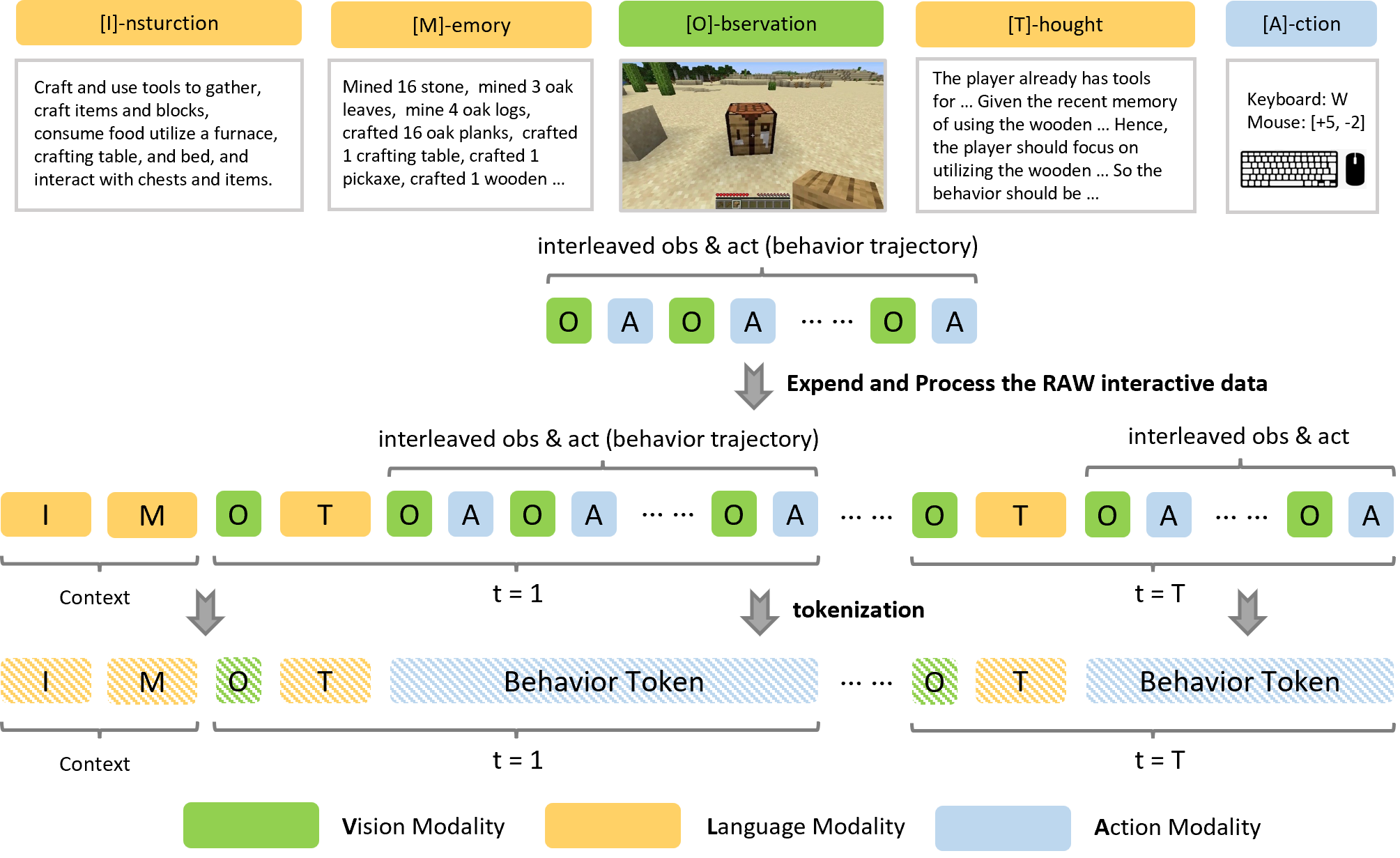
技术框架:OmniJARVIS的整体框架包括以下几个主要模块:1) 行为编码器:使用自监督学习方法将行为轨迹编码为离散的Token。2) 多模态语言模型:使用预训练的多模态语言模型作为主干网络,并扩展其词汇表以包含行为Token。3) 策略解码器:使用模仿学习策略解码器,根据行为Token生成具体的动作指令。整个流程是,首先将任务指令、记忆、思考、观察等信息编码为Token序列,然后输入到多模态语言模型中进行推理和规划,最后生成行为Token,并通过策略解码器执行动作。
关键创新:OmniJARVIS最重要的创新点在于统一Token化多模态交互数据。通过将视觉、语言和动作信息都表示为Token序列,模型可以更容易地学习它们之间的关系,从而实现更强的推理和决策能力。与现有方法相比,OmniJARVIS避免了将任务分解为文本目标或直接生成控制命令的局限性,而是采用了一种更通用和灵活的方法。
关键设计:行为编码器使用自监督学习方法,通过预测未来的状态来学习行为Token。多模态语言模型使用预训练的Transformer模型,并添加了行为Token的嵌入层。策略解码器使用模仿学习方法,通过学习人类玩家的行为来生成动作指令。损失函数包括语言模型损失和模仿学习损失。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
OmniJARVIS 在 Minecraft 开放世界环境中表现出卓越的性能,能够完成原子、程序化和开放式任务。通过统一 Token 化多模态交互数据,OmniJARVIS 能够进行推理、规划、回答问题和行动,展示了其强大的通用性和灵活性。具体性能数据和对比基线将在论文中详细展示。
🎯 应用场景
OmniJARVIS 的技术可应用于游戏AI、机器人控制、自动驾驶等领域。通过统一建模视觉、语言和动作信息,可以构建更智能、更通用的智能体,使其能够更好地理解人类指令,并在复杂环境中执行任务。该研究为构建更强大的通用人工智能系统提供了新的思路。
📄 摘要(原文)
This paper presents OmniJARVIS, a novel Vision-Language-Action (VLA) model for open-world instruction-following agents in Minecraft. Compared to prior works that either emit textual goals to separate controllers or produce the control command directly, OmniJARVIS seeks a different path to ensure both strong reasoning and efficient decision-making capabilities via unified tokenization of multimodal interaction data. First, we introduce a self-supervised approach to learn a behavior encoder that produces discretized tokens for behavior trajectories $τ= {o_0, a_0, \dots}$ and an imitation learning policy decoder conditioned on these tokens. These additional behavior tokens will be augmented to the vocabulary of pretrained Multimodal Language Models. With this encoder, we then pack long-term multimodal interactions involving task instructions, memories, thoughts, observations, textual responses, behavior trajectories, etc into unified token sequences and model them with autoregressive transformers. Thanks to the semantically meaningful behavior tokens, the resulting VLA model, OmniJARVIS, can reason (by producing chain-of-thoughts), plan, answer questions, and act (by producing behavior tokens for the imitation learning policy decoder). OmniJARVIS demonstrates excellent performances on a comprehensive collection of atomic, programmatic, and open-ended tasks in open-world Minecraft. Our analysis further unveils the crucial design principles in interaction data formation, unified tokenization, and its scaling potentials. The dataset, models, and code will be released at https://craftjarvis.org/OmniJARVIS.