Averaging log-likelihoods in direct alignment
作者: Nathan Grinsztajn, Yannis Flet-Berliac, Mohammad Gheshlaghi Azar, Florian Strub, Bill Wu, Eugene Choi, Chris Cremer, Arash Ahmadian, Yash Chandak, Olivier Pietquin, Matthieu Geist
分类: cs.LG
发布日期: 2024-06-27
💡 一句话要点
提出一种长度不变的直接对齐方法,优化LLM与人类判断的一致性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 直接对齐 人类反馈强化学习 长度不变性 对比学习
📋 核心要点
- 现有直接对齐方法在处理不同长度的文本时,对数似然损失不是长度不变的,影响模型训练。
- 提出一种新的平均算子,在损失函数中对对数似然进行平均,从而实现长度不变的直接对齐。
- 实验表明,该方法在生成文本的长度和质量之间取得了平衡,优化了模型性能。
📝 摘要(中文)
为了更好地使大型语言模型(LLM)与人类判断对齐,人类反馈强化学习(RLHF)学习一个奖励模型,然后使用正则化强化学习对其进行优化。最近,直接对齐方法被引入,可以直接从偏好数据集中学习这种微调模型,而无需计算代理奖励函数。这些方法建立在对比损失之上,涉及根据训练模型得出的(不)偏好完成的对数似然。然而,完成具有不同的长度,并且对数似然不是长度不变的。另一方面,监督训练中使用的交叉熵损失是长度不变的,因为批次通常是按token平均的。为了协调这些方法,我们引入了一种原则性的方法,使直接对齐长度不变。形式上,我们引入了一种新的平均算子,与最优算子组合,为底层RL问题提供最佳策略。它转化为损失中对数似然的平均。我们通过实验研究了这种平均的效果,观察到生成长度和它们的分数之间的权衡。
🔬 方法详解
问题定义:直接对齐方法旨在通过对比学习,直接从人类偏好数据中训练LLM,避免了构建奖励模型的中间步骤。然而,现有方法使用的对比损失依赖于对数似然,而对数似然受文本长度影响,导致模型在生成不同长度文本时表现不一致。现有方法的痛点在于缺乏长度不变性,影响了模型训练的稳定性和效果。
核心思路:论文的核心思路是引入一种新的平均算子,对损失函数中的对数似然进行平均。通过对每个token的对数似然进行平均,使得损失函数对文本长度不再敏感,从而实现长度不变性。这样可以避免模型偏向于生成特定长度的文本,提高模型的泛化能力和生成质量。
技术框架:该方法的核心在于修改了直接对齐方法的损失函数。整体流程如下:1. 收集人类偏好数据集;2. 使用LLM生成候选文本;3. 计算候选文本的对数似然;4. 使用新的平均算子对对数似然进行平均;5. 使用平均后的对数似然计算对比损失;6. 使用对比损失更新LLM的参数。
关键创新:最重要的技术创新点是引入了长度不变的平均算子。与现有方法直接使用对数似然不同,该方法通过对对数似然进行平均,消除了文本长度对损失函数的影响。这种方法使得模型能够更好地学习人类偏好,提高生成文本的质量和多样性。
关键设计:关键设计在于平均算子的具体实现。论文中提出的平均算子是对每个token的对数似然进行平均,即:averaged_log_likelihood = sum(log_likelihood_per_token) / sequence_length。然后,使用这个平均后的对数似然来计算对比损失。具体的损失函数形式取决于所使用的直接对齐方法,例如DPO或IPO,但核心思想都是用平均后的对数似然替换原始的对数似然。
🖼️ 关键图片

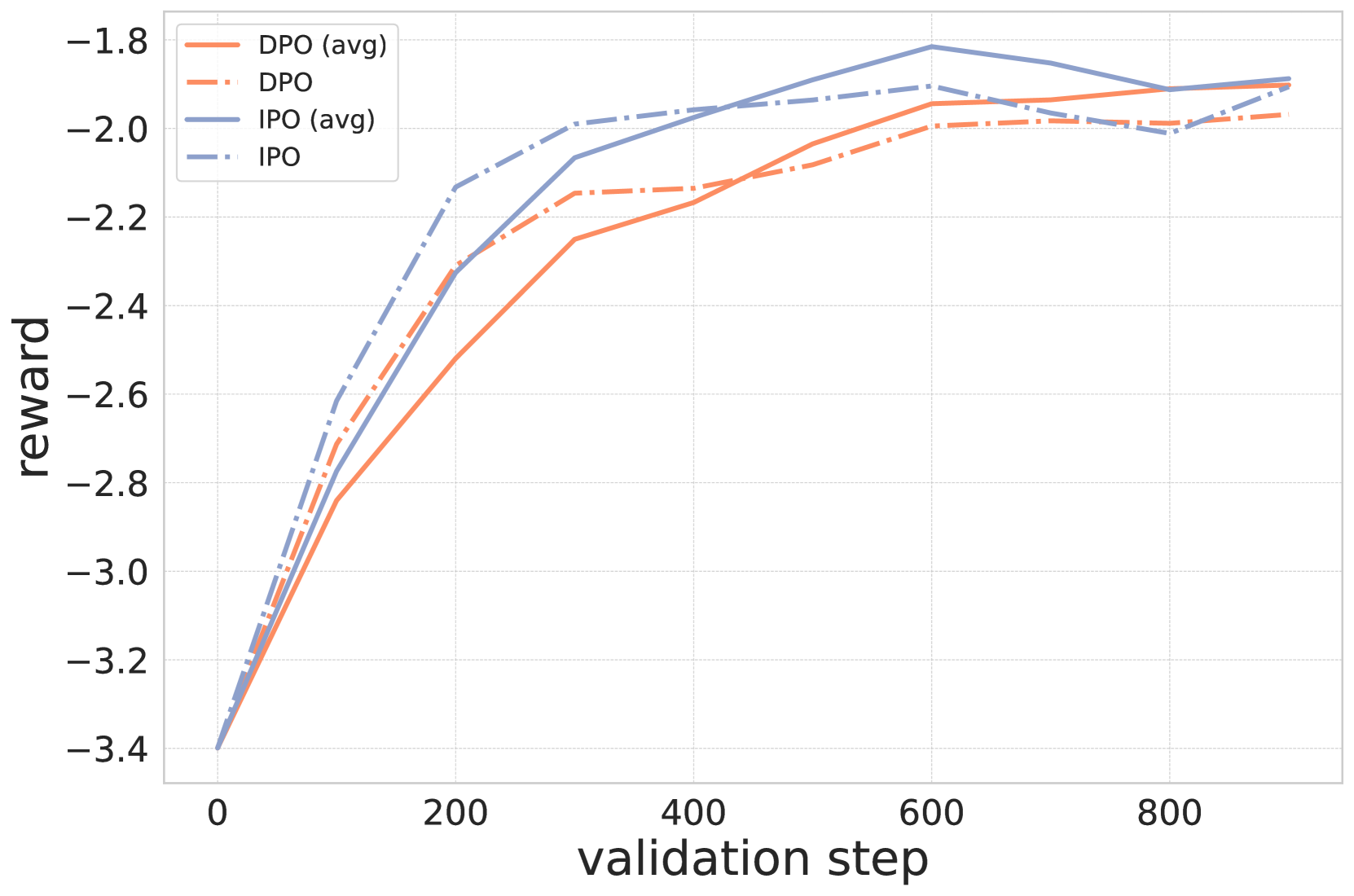
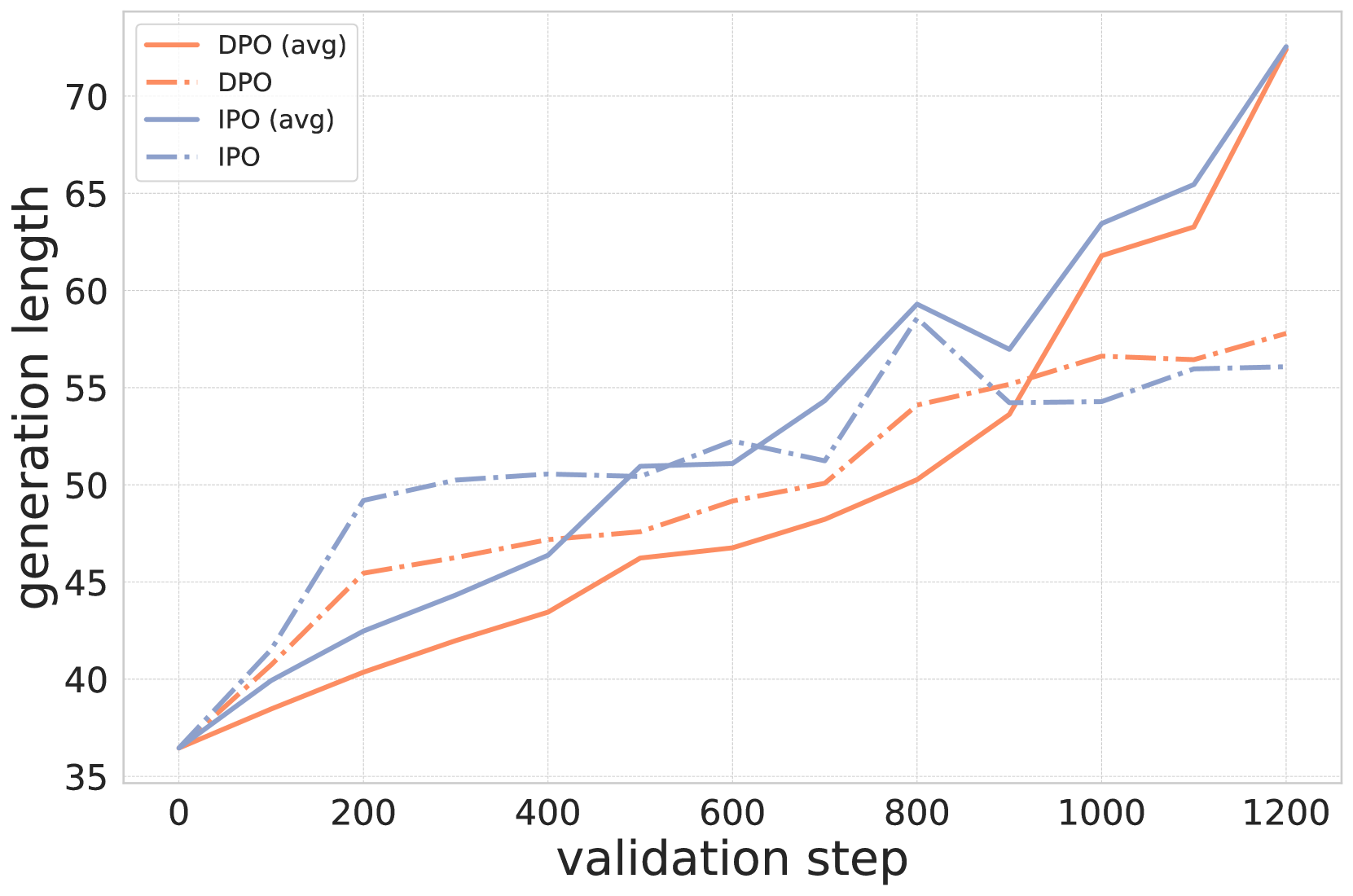
📊 实验亮点
论文通过实验验证了所提出的长度不变平均方法的有效性。实验结果表明,该方法能够在生成文本的长度和质量之间取得更好的平衡。虽然没有给出具体的性能数据,但论文强调了在生成长度和分数之间存在权衡,而该方法能够有效地管理这种权衡,从而提升整体性能。
🎯 应用场景
该研究成果可应用于各种需要与人类偏好对齐的LLM应用场景,例如对话系统、文本摘要、代码生成等。通过提高模型与人类判断的一致性,可以提升用户体验,并减少模型产生有害或不符合期望的输出的可能性。该方法还有助于提高模型的可控性和安全性。
📄 摘要(原文)
To better align Large Language Models (LLMs) with human judgment, Reinforcement Learning from Human Feedback (RLHF) learns a reward model and then optimizes it using regularized RL. Recently, direct alignment methods were introduced to learn such a fine-tuned model directly from a preference dataset without computing a proxy reward function. These methods are built upon contrastive losses involving the log-likelihood of (dis)preferred completions according to the trained model. However, completions have various lengths, and the log-likelihood is not length-invariant. On the other side, the cross-entropy loss used in supervised training is length-invariant, as batches are typically averaged token-wise. To reconcile these approaches, we introduce a principled approach for making direct alignment length-invariant. Formally, we introduce a new averaging operator, to be composed with the optimality operator giving the best policy for the underlying RL problem. It translates into averaging the log-likelihood within the loss. We empirically study the effect of such averaging, observing a trade-off between the length of generations and their scores.