Contrastive Policy Gradient: Aligning LLMs on sequence-level scores in a supervised-friendly fashion
作者: Yannis Flet-Berliac, Nathan Grinsztajn, Florian Strub, Bill Wu, Eugene Choi, Chris Cremer, Arash Ahmadian, Yash Chandak, Mohammad Gheshlaghi Azar, Olivier Pietquin, Matthieu Geist
分类: cs.LG
发布日期: 2024-06-27 (更新: 2025-01-16)
备注: EMNLP 2024
💡 一句话要点
提出对比策略梯度(CoPG),用于在序列级奖励下对齐LLM,且兼容监督学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对比策略梯度 大型语言模型 强化学习 策略对齐 Off-policy学习 序列奖励 状态基线
📋 核心要点
- 现有直接对齐方法无法优化任意奖励,而基于偏好的方法并非LLM的唯一奖励来源,例如代码生成的单元测试或文本蕴含。
- CoPG是一种off-policy策略梯度方法,无需重要性采样,通过使用合适的状态基线,可以从off-policy数据中估计最优策略。
- 实验表明,CoPG可以推广直接对齐方法IPO和经典策略梯度,并在玩具问题和LLM摘要任务上验证了其有效性。
📝 摘要(中文)
本文提出了一种新的强化学习算法——对比策略梯度(CoPG),用于微调大型语言模型(LLM),使其更好地与人类判断对齐。CoPG旨在解决现有直接对齐方法无法优化任意奖励,以及传统策略梯度方法需要昂贵的on-policy样本的问题。CoPG是一种off-policy策略梯度方法,不依赖重要性采样,并强调了状态基线的重要性。CoPG可以被视为直接对齐方法IPO和经典策略梯度的推广。论文通过玩具bandit问题验证了CoPG的性质,并将其应用于摘要任务的LLM微调,使用学习到的奖励函数作为实验的ground truth。
🔬 方法详解
问题定义:论文旨在解决使用强化学习微调大型语言模型(LLM)时,现有方法的局限性。具体来说,直接对齐方法虽然简单高效,但无法优化任意形式的奖励函数。而传统的策略梯度方法需要大量的on-policy样本,导致计算成本高昂。因此,需要一种既能优化任意奖励,又能利用off-policy数据进行学习的算法。
核心思路:CoPG的核心思路是利用对比学习的思想,通过最大化优势函数与状态基线之间的对比,来学习最优策略。这种方法避免了重要性采样,从而降低了方差,并允许使用off-policy数据进行训练。同时,通过选择合适的基线函数,可以有效地减少梯度估计的方差,提高学习效率。
技术框架:CoPG算法的整体流程如下:1) 使用任意策略生成数据;2) 使用奖励函数评估生成的数据;3) 计算优势函数;4) 使用对比损失函数更新策略。该算法的关键在于优势函数的计算和对比损失函数的设计。优势函数用于衡量当前策略相对于基线策略的优劣,对比损失函数则用于最大化优势函数与状态基线之间的对比。
关键创新:CoPG的关键创新在于提出了一种新的off-policy策略梯度估计方法,该方法不依赖于重要性采样,而是通过对比学习的方式来学习策略。这种方法可以有效地降低方差,并允许使用off-policy数据进行训练。此外,CoPG还强调了状态基线的重要性,并提供了一种选择合适基线函数的方法。
关键设计:CoPG的关键设计包括:1) 优势函数的计算方式:论文中使用了多种优势函数估计方法,包括TD-error和蒙特卡洛估计;2) 对比损失函数的设计:论文中使用了InfoNCE损失函数,该损失函数可以有效地最大化优势函数与状态基线之间的对比;3) 状态基线的选择:论文中建议使用值函数作为状态基线,并提供了一种学习值函数的方法。
🖼️ 关键图片

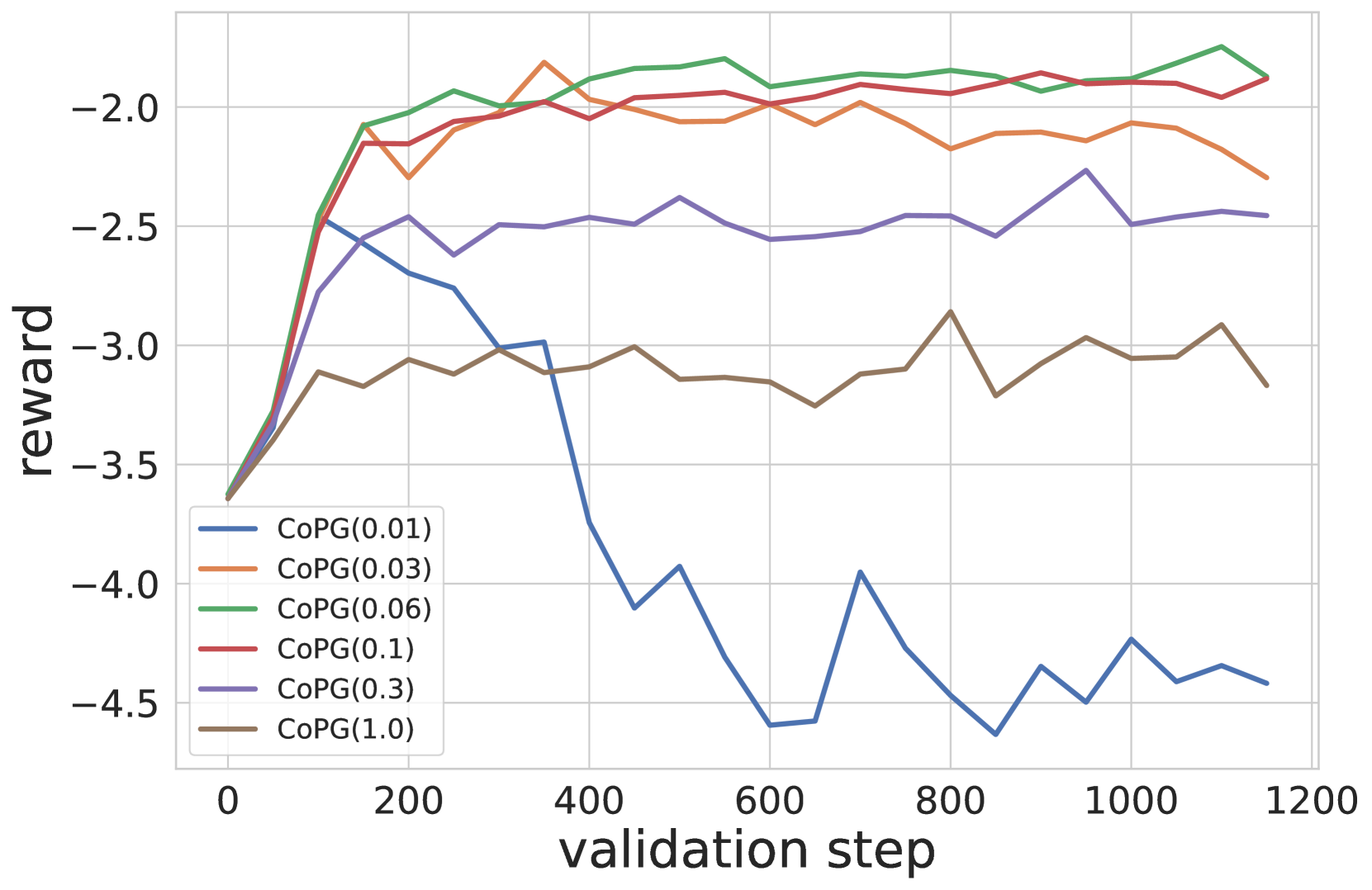

📊 实验亮点
论文在玩具bandit问题和LLM摘要任务上验证了CoPG的有效性。在摘要任务中,使用学习到的奖励函数作为ground truth,CoPG能够有效地提高摘要的质量。此外,实验结果表明,CoPG可以推广直接对齐方法IPO和经典策略梯度,并且在某些情况下能够取得更好的性能。
🎯 应用场景
CoPG算法可广泛应用于需要使用序列级奖励函数来对齐LLM的任务中,例如文本摘要、代码生成、对话系统等。该算法能够优化任意形式的奖励函数,并且可以利用off-policy数据进行训练,从而降低了计算成本。CoPG的实际价值在于能够更有效地训练LLM,使其更好地满足人类的需求。
📄 摘要(原文)
Reinforcement Learning (RL) has been used to finetune Large Language Models (LLMs) using a reward model trained from preference data, to better align with human judgment. The recently introduced direct alignment methods, which are often simpler, more stable, and computationally lighter, can more directly achieve this. However, these approaches cannot optimize arbitrary rewards, and the preference-based ones are not the only rewards of interest for LLMs (eg., unit tests for code generation or textual entailment for summarization, among others). RL-finetuning is usually done with a variation of policy gradient, which calls for on-policy or near-on-policy samples, requiring costly generations. We introduce Contrastive Policy Gradient, or CoPG, a simple and mathematically principled new RL algorithm that can estimate the optimal policy even from off-policy data. It can be seen as an off-policy policy gradient approach that does not rely on important sampling techniques and highlights the importance of using (the right) state baseline. We show this approach to generalize the direct alignment method IPO (identity preference optimization) and classic policy gradient. We experiment with the proposed CoPG on a toy bandit problem to illustrate its properties, as well as for finetuning LLMs on a summarization task, using a learned reward function considered as ground truth for the purpose of the experiments.