Decoding-Time Language Model Alignment with Multiple Objectives
作者: Ruizhe Shi, Yifang Chen, Yushi Hu, Alisa Liu, Hannaneh Hajishirzi, Noah A. Smith, Simon S. Du
分类: cs.LG
发布日期: 2024-06-27 (更新: 2024-10-28)
备注: NeurIPS accepted version
💡 一句话要点
提出多目标解码(MOD)算法,用于解码时对齐语言模型以优化多个目标。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语言模型对齐 多目标优化 解码算法 勒让德变换 f-散度正则化
📋 核心要点
- 现有语言模型对齐方法主要优化单一奖励函数,难以适应多样化目标,限制了其应用场景。
- 论文提出多目标解码(MOD)算法,通过线性组合多个基础模型的预测,实现解码时对齐多个目标。
- 实验表明,MOD在多目标优化中优于参数合并基线,并在安全性、编码和用户偏好等指标上取得显著提升。
📝 摘要(中文)
将语言模型与人类偏好对齐已成为一项关键任务,能够使这些模型更好地服务于多样化的用户需求。现有方法主要集中于优化语言模型以适应单一奖励函数,限制了它们对不同目标的适应性。本文提出了一种多目标解码(MOD)算法,该算法在解码时从所有基础模型的预测的线性组合中输出下一个token,适用于任何给定的目标权重。我们利用一类f-散度正则化对齐方法(如PPO、DPO及其变体)中的常见形式,通过勒让德变换识别闭式解,并推导出一种高效的解码策略。理论上,我们证明了现有方法即使在自然环境中也可能次优,并获得了我们方法的最优性保证。实验结果表明了该算法的有效性。例如,与参数合并基线相比,当平等地优化3个目标时,MOD实现了12.8%的总体奖励提升。此外,我们还尝试使用MOD来组合三个完全微调的、具有不同模型大小的LLM,每个LLM都旨在实现不同的目标,如安全性、编码和一般用户偏好。与需要仔细管理数据集混合以实现全面改进的传统方法不同,我们可以使用MOD快速试验偏好权重,以找到模型的最佳组合。我们最好的组合将Toxigen上的毒性降低到接近0%,并在其他三个指标(即Codex@1、GSM-COT、BBH-COT)上实现了7.9-33.3%的改进。
🔬 方法详解
问题定义:现有语言模型对齐方法通常针对单一奖励函数进行优化,无法有效兼顾多个目标,例如安全性、编码能力和用户偏好等。这种单一目标优化限制了模型在实际应用中的灵活性和适应性。现有方法在处理多目标优化问题时,往往需要精心设计数据集混合比例,过程繁琐且效果难以保证。
核心思路:论文的核心思路是在解码阶段,通过线性组合多个基础模型的预测结果,实现对多个目标的优化。每个基础模型针对一个特定目标进行训练,MOD算法根据预设的权重,将这些模型的预测进行加权平均,从而在解码过程中同时考虑多个目标。这种方法避免了在训练阶段进行复杂的模型融合或数据集混合,提高了效率和灵活性。
技术框架:MOD算法的技术框架主要包括以下几个步骤:1) 训练多个基础语言模型,每个模型针对一个特定的目标进行优化。2) 在解码阶段,对于每个token,MOD算法首先获取所有基础模型的预测概率分布。3) 根据预设的权重,对这些概率分布进行线性组合,得到最终的预测概率分布。4) 从最终的概率分布中采样或选择概率最高的token作为输出。论文利用f-散度正则化对齐方法(如PPO、DPO)的共性,通过勒让德变换推导出闭式解,从而实现高效解码。
关键创新:MOD算法的关键创新在于其解码时多目标对齐的思想。与传统的训练时融合或数据集混合方法不同,MOD算法在解码阶段动态地调整模型的行为,从而实现对多个目标的优化。此外,论文通过理论分析证明了现有方法的次优性,并为MOD算法提供了最优性保证。
关键设计:MOD算法的关键设计包括:1) 基础模型的选择和训练:选择具有不同专长的基础模型,并针对各自的目标进行充分训练。2) 权重设置:根据实际需求,合理设置各个目标的权重,以平衡不同目标之间的优先级。3) 勒让德变换的应用:利用勒让德变换推导出闭式解,避免了复杂的优化过程,提高了解码效率。4) f-散度正则化:利用f-散度正则化方法,保证模型训练的稳定性和泛化能力。
🖼️ 关键图片

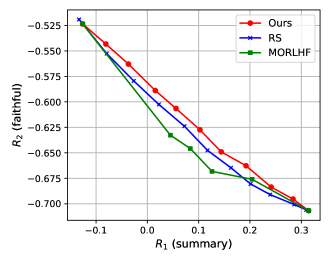

📊 实验亮点
实验结果表明,MOD算法在多目标优化方面表现出色。与参数合并基线相比,在平等优化三个目标时,MOD实现了12.8%的总体奖励提升。在结合三个分别针对安全性、编码和用户偏好进行微调的LLM时,MOD能够将Toxigen上的毒性降低到接近0%,并在Codex@1、GSM-COT、BBH-COT等指标上分别实现了7.9-33.3%的改进。
🎯 应用场景
MOD算法可应用于各种需要兼顾多个目标的语言模型应用场景,例如:安全对话系统(同时考虑流畅性和安全性)、多功能助手(同时满足用户偏好和任务完成度)、代码生成工具(同时保证代码质量和效率)。该方法能够提升语言模型在复杂场景下的适应性和实用性,并降低开发和维护成本。
📄 摘要(原文)
Aligning language models (LMs) to human preferences has emerged as a critical pursuit, enabling these models to better serve diverse user needs. Existing methods primarily focus on optimizing LMs for a single reward function, limiting their adaptability to varied objectives. Here, we propose $\textbf{multi-objective decoding (MOD)}$, a decoding-time algorithm that outputs the next token from a linear combination of predictions of all base models, for any given weightings over different objectives. We exploit a common form among a family of $f$-divergence regularized alignment approaches (such as PPO, DPO, and their variants) to identify a closed-form solution by Legendre transform, and derive an efficient decoding strategy. Theoretically, we show why existing approaches can be sub-optimal even in natural settings and obtain optimality guarantees for our method. Empirical results demonstrate the effectiveness of the algorithm. For example, compared to a parameter-merging baseline, MOD achieves 12.8% overall reward improvement when equally optimizing towards $3$ objectives. Moreover, we experiment with MOD on combining three fully-finetuned LLMs of different model sizes, each aimed at different objectives such as safety, coding, and general user preference. Unlike traditional methods that require careful curation of a mixture of datasets to achieve comprehensive improvement, we can quickly experiment with preference weightings using MOD to find the best combination of models. Our best combination reduces toxicity on Toxigen to nearly 0% and achieves 7.9--33.3% improvement across other three metrics ($\textit{i.e.}$, Codex@1, GSM-COT, BBH-COT).