MissionGNN: Hierarchical Multimodal GNN-based Weakly Supervised Video Anomaly Recognition with Mission-Specific Knowledge Graph Generation
作者: Sanggeon Yun, Ryozo Masukawa, Minhyoung Na, Mohsen Imani
分类: cs.LG
发布日期: 2024-06-27 (更新: 2025-05-23)
备注: Accepted to WACV 2025
🔗 代码/项目: GITHUB
💡 一句话要点
MissionGNN:基于层级多模态GNN与任务知识图谱的弱监督视频异常识别
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频异常检测 视频异常识别 图神经网络 知识图谱 弱监督学习
📋 核心要点
- 视频异常检测和识别任务面临数据不平衡和帧级别标注困难的挑战,现有方法难以有效利用弱监督信息。
- MissionGNN利用大型语言模型和知识图谱,通过层级GNN实现高效的弱监督学习,避免了对大型多模态模型的梯度计算。
- 实验结果表明,MissionGNN在基准数据集上表现出色,为视频监控系统中的异常检测和识别提供了新的解决方案。
📝 摘要(中文)
针对智能监控、证据调查和暴力预警等领域日益增长的安全需求,视频异常检测(VAD)和视频异常识别(VAR)任务变得至关重要。这些任务旨在识别和分类视频数据中偏离正常行为的异常情况,但由于异常的稀有性导致数据极度不平衡,以及对帧级别数据进行大规模标注的不切实际,面临着重大挑战。本文提出了一种新的基于层级图神经网络(GNN)的模型MissionGNN,该模型利用最先进的大型语言模型和全面的知识图谱,在VAR中实现高效的弱监督学习。我们的方法避免了先前方法中对大型多模态模型进行繁重的梯度计算的限制,并实现了完全帧级别的训练,而无需固定的视频分割。通过自动化的、特定于任务的知识图谱生成,我们的模型为实时视频分析提供了一种实用且高效的解决方案,不受先前基于分割或多模态方法的约束。在基准数据集上的实验验证证明了我们的模型在VAD和VAR方面的性能,突出了其在重新定义视频监控系统中异常检测和识别领域的潜力。
🔬 方法详解
问题定义:视频异常识别(VAR)旨在识别视频中不正常的行为事件。现有方法通常依赖于大量的标注数据,但异常事件的稀缺性使得获取大规模标注数据变得困难。此外,一些方法依赖于视频分割,限制了其在实时场景中的应用。多模态方法虽然可以利用多种信息源,但计算成本高昂。
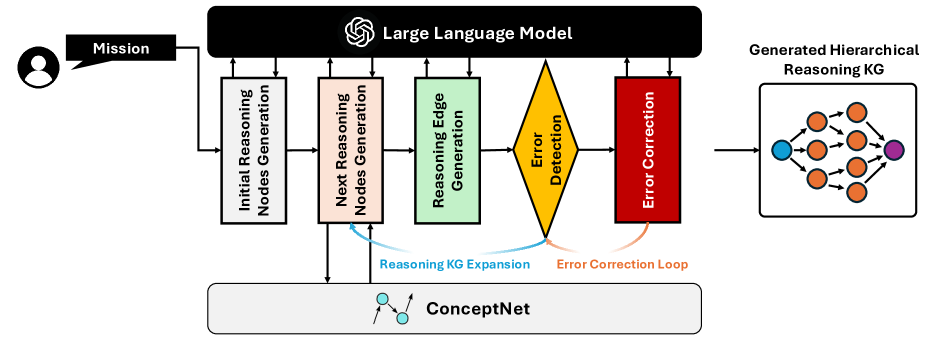
核心思路:MissionGNN的核心思路是利用大型语言模型(LLM)生成任务相关的知识图谱,并结合层级图神经网络(GNN)进行弱监督学习。通过知识图谱,模型可以学习正常行为的模式,从而更容易识别异常行为。避免了对大型多模态模型进行梯度计算,降低了计算成本。
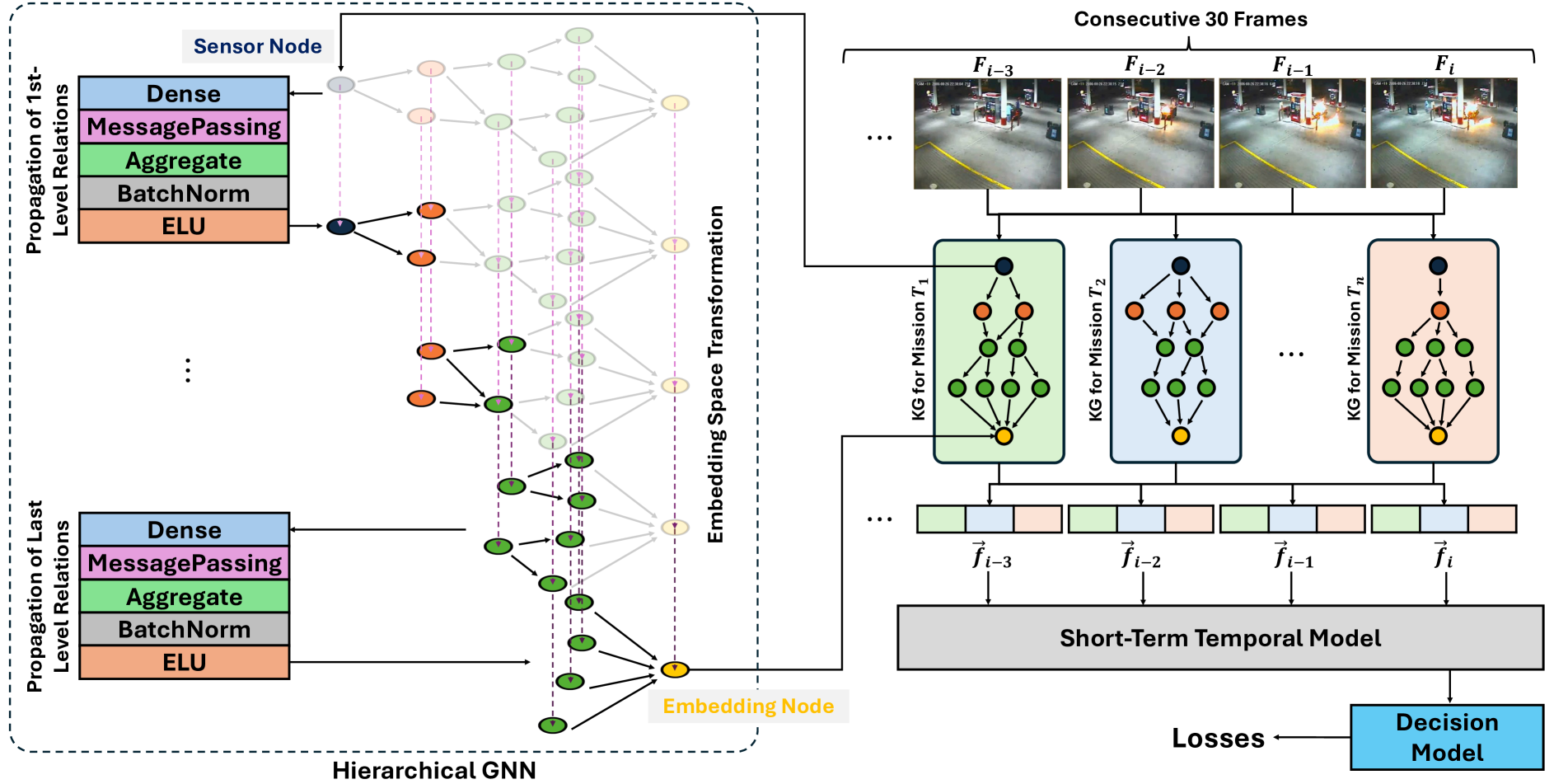
技术框架:MissionGNN的整体框架包括以下几个主要模块:1) 任务特定知识图谱生成模块:利用LLM自动生成与特定任务相关的知识图谱。2) 多模态特征提取模块:提取视频帧的视觉特征和文本特征。3) 层级GNN模块:利用层级GNN对知识图谱和多模态特征进行融合,学习视频中的行为模式。4) 异常识别模块:基于学习到的行为模式,识别视频中的异常事件。
关键创新:MissionGNN的关键创新在于:1) 提出了基于LLM的任务特定知识图谱生成方法,能够自动生成与特定任务相关的知识图谱,无需人工标注。2) 采用了层级GNN结构,能够有效地融合知识图谱和多模态特征,提高异常识别的准确率。3) 避免了对大型多模态模型进行梯度计算,降低了计算成本,使其更适用于实时场景。
关键设计:知识图谱的节点表示事件或对象,边表示它们之间的关系。层级GNN包含多个GNN层,每一层学习不同层次的特征表示。损失函数包括分类损失和对比学习损失,用于提高模型的判别能力。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
MissionGNN在基准数据集上的实验结果表明,该模型在视频异常检测和识别方面取得了显著的性能提升。与现有方法相比,MissionGNN在准确率和召回率方面均有明显提高,尤其是在数据不平衡的情况下,其性能优势更加明显。具体的性能数据和对比基线可以在论文的实验部分找到。
🎯 应用场景
MissionGNN在智能监控、证据调查、暴力预警等领域具有广泛的应用前景。它可以用于自动识别监控视频中的异常行为,例如打架斗殴、盗窃等,从而提高安全防范能力。此外,该模型还可以用于分析犯罪现场视频,帮助警方快速锁定嫌疑人。未来,该模型可以进一步扩展到其他领域,例如医疗诊断、工业安全等。
📄 摘要(原文)
In the context of escalating safety concerns across various domains, the tasks of Video Anomaly Detection (VAD) and Video Anomaly Recognition (VAR) have emerged as critically important for applications in intelligent surveillance, evidence investigation, violence alerting, etc. These tasks, aimed at identifying and classifying deviations from normal behavior in video data, face significant challenges due to the rarity of anomalies which leads to extremely imbalanced data and the impracticality of extensive frame-level data annotation for supervised learning. This paper introduces a novel hierarchical graph neural network (GNN) based model MissionGNN that addresses these challenges by leveraging a state-of-the-art large language model and a comprehensive knowledge graph for efficient weakly supervised learning in VAR. Our approach circumvents the limitations of previous methods by avoiding heavy gradient computations on large multimodal models and enabling fully frame-level training without fixed video segmentation. Utilizing automated, mission-specific knowledge graph generation, our model provides a practical and efficient solution for real-time video analysis without the constraints of previous segmentation-based or multimodal approaches. Experimental validation on benchmark datasets demonstrates our model's performance in VAD and VAR, highlighting its potential to redefine the landscape of anomaly detection and recognition in video surveillance systems. The code is available here: https://github.com/c0510gy/MissionGNN.